文本分类
python实现文本分类
一、中文文本分类流程:1. 预处理2. 中文分词3. 结构化表示-构建词向量空间4.权重策略-TF-IDF5. 分类器6. 评价二、具体细节1.预处理 1.1. 得到训练集语料库 本文采用复旦中文文本分类语料库,下载链接:htt

【Python NLTK】文本分类,轻松搞定文本归类难题
文本分类是自然语言处理(NLP)中的基本任务之一,其目标是将文本归类到预定义的类别中。本文将介绍使用Python NLTK库完成文本分类的任务,包括数据预处理、特征提取、模型训练和评估等步骤。

基于Spark Mllib文本分类的示例分析
这篇文章将为大家详细讲解有关基于Spark Mllib文本分类的示例分析,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。基于Spark Mllib的文本分类文本分类是一个典型的机器学习问题,其主要目标是通过

nlp文本分类方法怎么应用
NLP文本分类方法可以应用于许多场景,包括情感分析、垃圾邮件过滤、主题分类等。以下是一般的应用步骤:1. 数据收集和预处理:收集相关文本数据并进行必要的预处理,如去除标点符号、停用词等。2. 特征提取:从文本中提取有用的特征表示。常用的特征

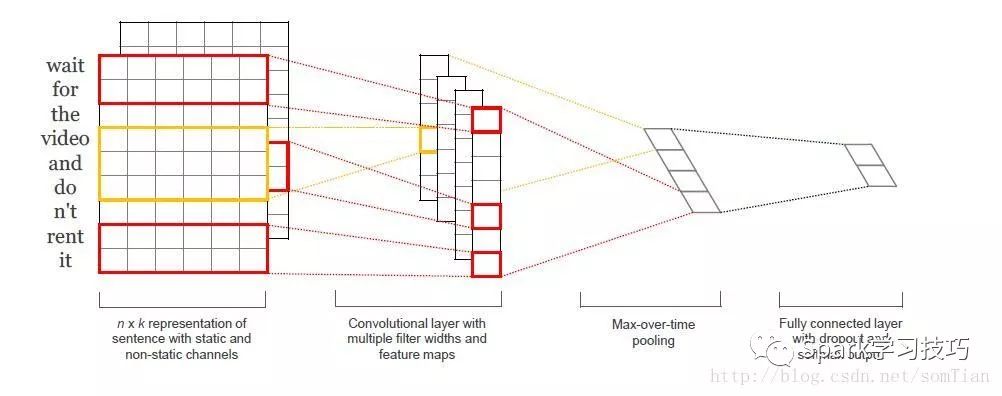
Tensorflow中怎么实现CNN文本分类
今天就跟大家聊聊有关Tensorflow中怎么实现CNN文本分类,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。1. 数据和预处理我们将在这篇文章中使用的数据集是 Movie Revi



Tensorflow2.4从头训练Word Embedding实现文本分类
这篇文章主要为大家介绍了Tensorflow2.4从头训练Word Embedding实现文本分类,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪

PaddlePaddle框架怎么处理文本分类任务
在PaddlePaddle框架中处理文本分类任务通常包括以下步骤:数据准备:首先需要准备训练数据和测试数据,并进行数据预处理,如分词、去除停用词等操作。构建模型:选择合适的文本分类模型,如TextCNN、BiLSTM等,可以使用Paddle

C#基本数据类型分类
本篇内容主要讲解“C#基本数据类型分类”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“C#基本数据类型分类”吧!C#基本数据类型中的值类型是直接存储它的数据内容,而引用类型存储的是对象的引用,这两

Tensorflow2.4中怎么使用Word Embedding实现文本分类
这篇“Tensorflow2.4中怎么使用Word Embedding实现文本分类”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这

深度学习Tensorflow2.8 使用 BERT 进行文本分类
这篇文章主要为大家介绍了深度学习Tensorflow2.8 使用 BERT 进行文本分类示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪

Tensorflow2.1实现文本中情感分类实现解析
这篇文章主要为大家介绍了Tensorflow2.1实现文本中情感分类实现解析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪


信息收集渠道:文本分享类网站Paste Site
信息收集渠道:文本分享类网站Paste SitePaste Site是一种专门的文本分享的网站。用户可以将一段文本性质的内容(如代码)上传到网站,然后通过链接分享给其他用户。这一点很类似于现在的优酷的视频分享功能。该功能最初流行于网络聊天

python3-分割文本文件
#myhaspl@myhaspl.comfId=1with open("tf-allsrc.txt","r") as sf: while True: with open("tf-src-"+str(fId)+".txt

【Python】文本分析
依赖库pip install jiebapip install matplotlibpip install wordcloudpip install snownlp词频统计# -*- coding: utf-8 -*-import jieb






