爬虫
【Python3爬虫】拉勾网爬虫
一、思路分析:在之前写拉勾网的爬虫的时候,总是得到下面这个结果(真是头疼),当你看到下面这个结果的时候,也就意味着被反爬了,因为一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正

Python爬虫教程-01-爬虫介绍
Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求参考资料精通Python爬虫框架Scrapy,人民邮电出版社url, httpweb前端,html,css,jsajaxre,xp

爬虫学习之第四章爬虫进阶之多线程爬虫
有些时候,比如下载图片,因为下载图片是一个耗时的操作。如果采用之前那种同步的方式下载。那效率肯会特别慢。这时候我们就可以考虑使用多线程的方式来下载图片。多线程介绍:多线程是为了同步完成多项任务,通过提高资源使用效率来提高系统的效率。线程是在


Python3网络爬虫实战-17、爬虫基
爬虫,即网络爬虫,我们可以把互联网就比作一张大网,而爬虫便是在网上爬行的蜘蛛,我们可以把网的节点比做一个个网页,爬虫爬到这就相当于访问了该页面获取了其信息,节点间的连线可以比做网页与网页之间的链接关系,这样蜘蛛通过一个节点后可以顺着节点连线

Requests爬虫
之前写过一个urllib的爬虫方法,这个库是python内建的,从那篇文章也可以看到,使用起来很繁琐。现在更流行的一个爬虫库就是requests,他是基于urllib3封装的,也就是将之前比较繁琐的步骤封装到一块,更适合人来使用。 该库中

Python爬虫入门:爬虫基础了解
Python爬虫入门(1):综述Python爬虫入门(2):爬虫基础了解Python爬虫入门(3):Urllib库的基本使用Python爬虫入门(4):Urllib库的高级用法Python爬虫入门(5):URLError异常处理Python

Python爬虫-04:贴吧爬虫以及GE
目录 1. URL的组成 2. 贴吧爬虫 2.1. 只爬贴吧第一页 2.2. 爬取所有贴吧的页面 3. GET和POST的区别

Python3网络爬虫实战-15、爬虫基
在写爬虫之前,还是需要了解一些爬虫的基础知识,如 HTTP 原理、网页的基础知识、爬虫的基本原理、Cookies 基本原理等。那么本章内容就对一些在做爬虫之前所需要的基础知识做一些简单的总结。在本节我们会详细了解 HTTP 的基本原理,了解

Python3网络爬虫(十一):爬虫黑科
原文链接: Jack-Cui,http://blog.csdn.net/c406495762 运行平台: Windows Python版本: Python3.x IDE: Sublime text31 前言近期,有些朋友问我一些关于如何应对

python爬虫
#!/usr/bin/pythonimport re #导入正则模块import urllib #导入url模块def getHtml(url): #定义获取网页函数 page = urllib.urlopen(url) #打

Python 爬虫
--安装爬虫需要的库C:\python37>pip install requestsCollecting requests Downloading https://files.pythonhosted.org/packages/7d/e3

python—爬虫
1.1 介绍通过过滤和分析HTML代码,实现对文件、图片等资源的获取,一般用到:urllib和urllib2模块正则表达式(re模块)requests模块Scrapy框架urllib库:1)获取web页面2)在远程http服务器上验证3)表

爬虫笔记1:Python爬虫常用库
请求库:1、urllib:urllib库是Python3自带的库(Python2有urllib和urllib2,到了Python3统一为urllib),这个库是爬虫里最简单的库。2、requests:requests属于第三方库,使用起来比

Python3网络爬虫实战-10、爬虫框
我们直接用 Requests、Selenium 等库写爬虫,如果爬取量不是太大,速度要求不高,是完全可以满足需求的。但是写多了会发现其内部许多代码和组件是可以复用的,如果我们把这些组件抽离出来,将各个功能模块化,就慢慢会形成一个框架雏形,久


Python3网络爬虫实战-11、爬虫框
ScrapySplash 是一个 Scrapy 中支持 JavaScript 渲染的工具,本节来介绍一下它的安装方式。ScrapySplash 的安装分为两部分,一个是是 Splash 服务的安装,安装方式是通过 Docker,安装之后会启

Python爬虫怎么突破反爬虫机制
这篇文章主要介绍“Python爬虫怎么突破反爬虫机制”,在日常操作中,相信很多人在Python爬虫怎么突破反爬虫机制问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python爬虫怎么突破反爬虫机制”的疑惑有所

Python爬虫-01:爬虫的概念及分类
目录 # 1. 为什么要爬虫? 2. 什么是爬虫? 3. 爬虫如何抓取网页数据? # 4. Python爬虫的优势? 5. 学习路
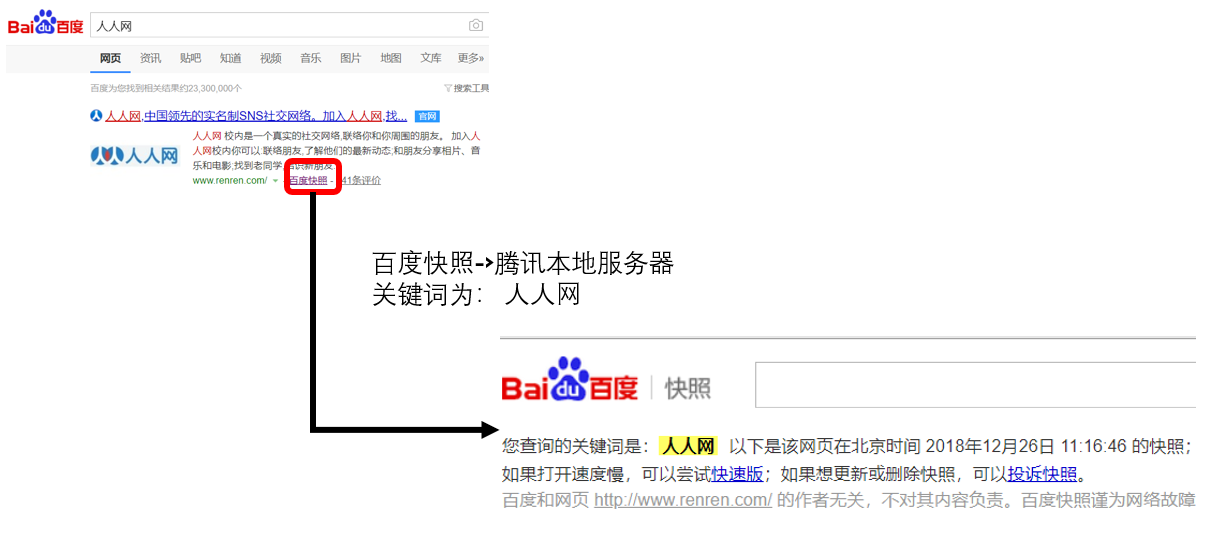
Python爬虫教程-34-分布式爬虫介
Python爬虫教程-34-分布式爬虫介绍分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫什么是分布式爬虫分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集。单机爬虫就是只在一台计算机上的爬虫。其实搜索引擎都是爬虫,负责从





