
38、面向对象深度优先和广度优先是什么?


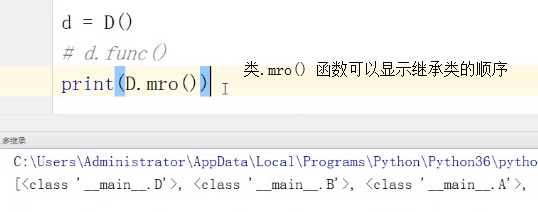

39、面向对象中super的作用?

40、是否使用过functools中的函数?其作用是什么?
1 Python自带的 functools 模块提供了一些常用的高阶函数,也就是用于处理其它函数的特殊函数。换言之,就是能使用该模块对可调用对象进行处理。
2
3 functools模块函数概览
4 functools.cmp_to_key(func)
5 functools.total_ordering(cls)
6 functools.reduce(function, iterable[, initializer])
7 functools.partial(func[, args][, *keywords])
8 functools.update_wrapper(wrapper, wrapped[, assigned][, updated])
9 functools.wraps(wrapped[, assigned][, updated])41、列举面向对象中带双下划线的魔术方法?
1. init()
2. del()
1 在调用del方法的时候,实际使用的是del()
2
3 class Person(object):
4 def __del__(self):
5 print('我给干掉啦')
6
7 bill = Person()
8 del bill #我给干掉啦3. new()
1 new()只有继承自objectd的类才有new()这方法是在init()之前调用的,用于生成实例对象。多用于设计模式中的单例模式。单例模式是为了确保类有且只有一个对象。多用于日志记录和数据库操作,打印机后台处理程序。这样子可以避免对统一资源产生相互冲突的请求
2 new()负责创建一个类的对象,init()方法负责对创建后的类对象进行默认设置
3 class Singleton(object):
4 def __new__(cls):
5 if not hasattr(cls, 'instance'):
6 cls.instance = super(Singleton, cls).__new__(cls)
7 return cls.instance
8
9 s = Singleton()
10 print('Object created', s)
11 s1 = Singleton()
12 print('Object created', s1)
13
14 # output
15 # Object created <__main__.Singleton object at 0x0000018EFF662DA0>
16 # Object created <__main__.Singleton object at 0x0000018EFF662DA0>
17
18 cls是当前类,new()返回的是一个实例,和init()中的self是同一个东西42、如何判断是函数还是方法?
一般情况下,单独写一个def func():表示一个函数,如果写在类里面是一个方法。但是不完全准确。
1 class Foo(object):
2 def fetch(self):
3 pass
4
5 print(Foo.fetch) # 打印结果<function Foo.fetch at 0x000001FF37B7CF28>表示函数
6 # 如果没经实例化,直接调用Foo.fetch()括号里要self参数,并且self要提前定义
7 obj = Foo()
8 print(obj.fetch) # 打印结果<bound method Foo.fetch of <__main__.Foo object at 0x000001FF37A0D208>>表示方法43、面向对象中的property属性、类方法、静态方法?
property属性:

类方法:
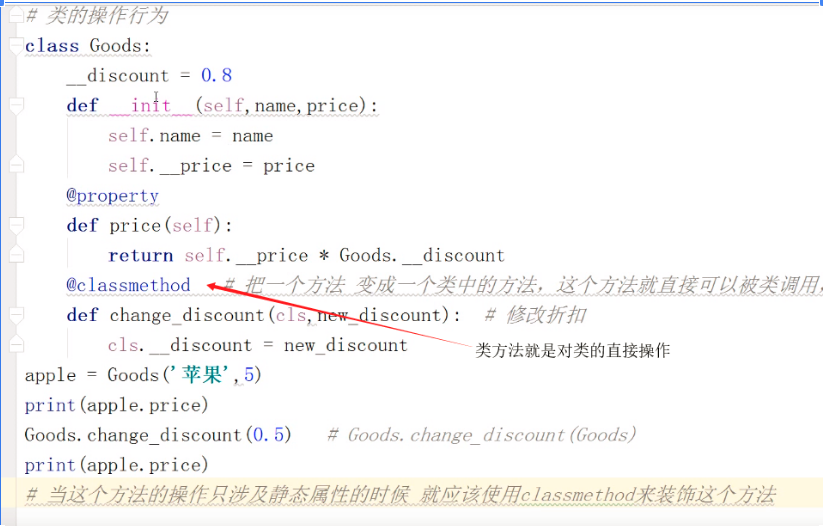
静态方法:

44、列举面向对象中的特殊成员以及应用场景
1 1. __doc__
2 表示类的描述信息
3 class Foo:
4 """ 描述类信息,这是用于看片的神奇 """
5 def func(self):
6 pass
7 print Foo.__doc__
8
9 ==============
10 描述类信息,这是用于看片的神奇1 2. __module__ 和 __class__
2 __module__ 表示当前操作的对象在哪个模块
3 __class__ 表示当前操作的对象的类是什么1 3. __init__
2 构造方法,通过类创建对象时,自动触发执行。1 4. __del__
2 析构方法,当对象在内存中被释放时,自动触发执行。
3
4 注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以,析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。5. __call__
对象后面加括号,触发执行。
注:构造方法的执行是由创建对象触发的,即:对象 = 类名() ;而对于 __call__ 方法的执行是由对象后加括号触发的,即:对象() 或者 类()()6. __dict__
类或对象中的所有成员7. __str__
如果一个类中定义了__str__方法,那么在打印 对象 时,默认输出该方法的返回值。8、__eq__

45、什么是反射?以及应用场景?





46、用尽量多的方法实现单例模式。
一、模块单例
Python 的模块就是天然的单例模式,因为模块在第一次导入时,会生成 .pyc 文件,当第二次导入时,就会直接加载 .pyc 文件,而不会再次执行模块代码。
1 #foo1.py
2 class Singleton(object):
3 def foo(self):
4 pass
5 singleton = Singleton()
6
7 #foo.py
8 from foo1 import singleton二、静态变量方法
先执行了类的__new__方法(我们没写时,默认调用object.__new__),实例化对象;然后再执行类的__init__方法,对这个对象进行初始化,所有我们可以基于这个,实现单例模式。
1 class Singleton(object):
2 def __new__(cls,a):
3 if not hasattr(cls, '_instance'):
4 cls._instance = object.__new__(cls)
5 return cls._instance
6 def __init__(self,a):
7 self.a = a
8 def aa(self):
9 print(self.a)
10
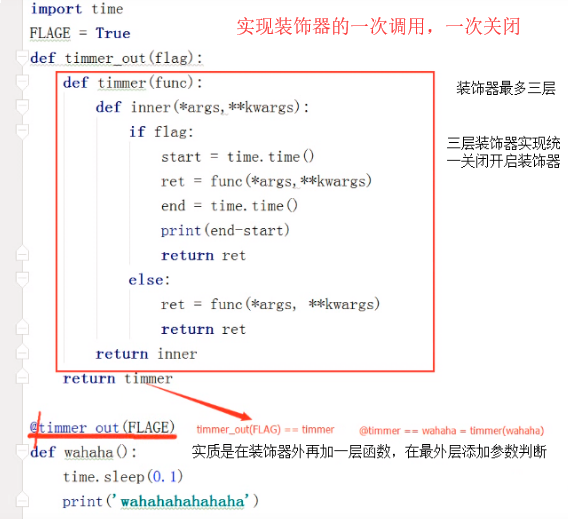
11 a = Singleton("a")47、装饰器的写法以及应用场景。

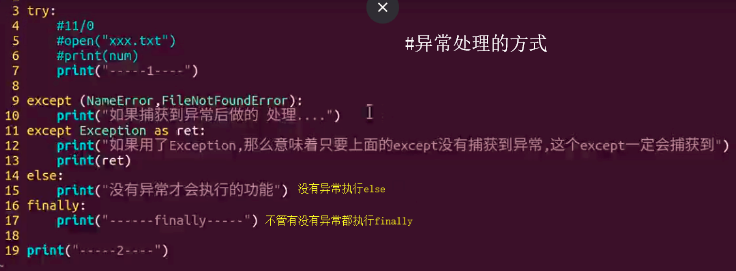
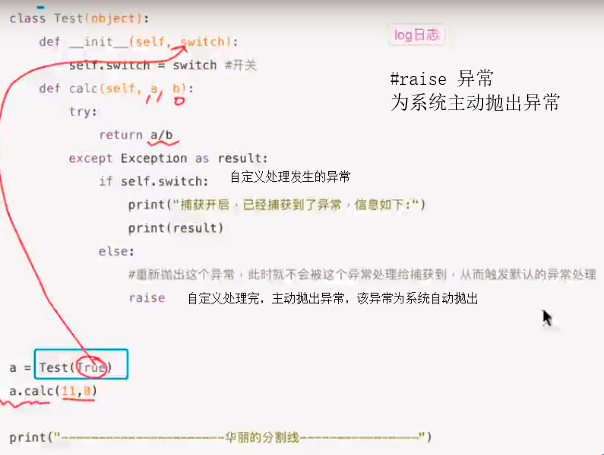
48、异常处理写法以及如何主动跑出异常(应用场景)
49、isinstance作用以及应用场景?

50、json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
1 官方文档中的一个Demo:
2 >>> import json
3
4 >>> class ComplexEncoder(json.JSONEncoder):
5 ... def default(self, obj):
6 ... if isinstance(obj, complex):
7 ... return [obj.real, obj.imag]
8 ... return json.JSONEncoder.default(self, obj)
9 ...
10 >>> dumps(2 + 1j, cls=ComplexEncoder)
11 '[2.0, 1.0]'
12 >>> ComplexEncoder().encode(2 + 1j)
13 '[2.0, 1.0]'
14 >>> list(ComplexEncoder().iterencode(2 + 1j))
15 ['[', '2.0', ', ', '1.0', ']']
16 1 然后简单扩展了一个JSONEncoder出来用来格式化时间
2 class CJsonEncoder(json.JSONEncoder):
3
4 def default(self, obj):
5 if isinstance(obj, datetime):
6 return obj.strftime('%Y-%m-%d %H:%M:%S')
7 elif isinstance(obj, date):
8 return obj.strftime('%Y-%m-%d')
9 else:
10 return json.JSONEncoder.default(self, obj)
11 1 使用时候只要在json.dumps增加一个cls参数即可:
2
3 json.dumps(datalist, cls=CJsonEncoder)51、json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?

52、使用代码实现查看列举目录下的所有文件。
1 import os
2
3 if __name__ == '__main__':
4 work_dir = 'C:\Program Files\MySQL\Connector ODBC 8.0'
5 for parent, dirnames, filenames in os.walk(work_dir, followlinks=True):
6 for filename in filenames:
7 file_path = os.path.join(parent, filename)
8 print('文件名:%s' % filename)
9 print('文件完整路径:%s\n' % file_path)53、简述 yield和yield from关键字。
1、可迭代对象与迭代器的区别
可迭代对象:指的是具备可迭代的能力,即enumerable. 在Python中指的是可以通过for-in 语句去逐个访问元素的一些对象,比如元组tuple,列表list,字符串string,文件对象file 等。
迭代器:指的是通过另一种方式去一个一个访问可迭代对象中的元素,即enumerator。在python中指的是给内置函数iter()传递一个可迭代对象作为参数,返回的那个对象就是迭代器,然后通过迭代器的next()方法逐个去访问。
1 from collections import Iterable
2
3 li=[1,4,2,3]
4 iterator1 = iter(li)
5 print(next(iterator1))
6 print(next(iterator1))
7 print(next(iterator1))
8 print(isinstance(iterator1,Iterable)) # 判断是否是迭代器,导入collection模块>>>
1
4
2
True2、生成器
生成器的本质就是一个逐个返回元素的函数,即“本质——函数”
最大的好处在于它是“延迟加载”,即对于处理长序列问题,更加的节省存储空间。即生成器每次在内存中只存储一个值
3、什么又是yield from呢?
简单地说,yield from generator 。实际上就是返回另外一个生成器。如下所示:
1 def generator1():
2 item = range(10)
3 for i in item:
4 yield i
5
6 def generator2():
7 yield 'a'
8 yield 'b'
9 yield 'c'
10 yield from generator1() #yield from iterable本质上等于 for item in iterable: yield item的缩写版
11 yield from [11,22,33,44]
12 yield from (12,23,34)
13 yield from range(3)
14
15 for i in generator2() :
16 print(i)从上面的代码可以看出,yield from 后面可以跟的式子有“ 生成器 元组 列表等可迭代对象以及range()函数产生的序列”
上面代码运行的结果为:
a
b
c
0
1
2
3
4
5
6
7
8
9
11
22
33
44
12
23
34
0
1
2







