
文件名自定义(文件格式为.py),脚本内容:
#!/usr/bin/env python
#-*-coding:utf-8-*-
import requests
import random
import time
def get_json(url):
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
params = {
'page_size': 10,
'next_offset': str(num),
'tag': '今日热门',
'platform': 'pc'
}
try:
html = requests.get(url,params=params,headers=headers)
return html.json()
except BaseException:
print('request error')
pass
def download(url,path):
start = time.time() # 开始时间
size = 0
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
response = requests.get(url,headers=headers,stream=True) # stream属性必须带上
chunk_size = 1024 # 每次下载的数据大小
content_size = int(response.headers['content-length']) # 总大小
if response.status_code == 200:
print('[文件大小]:%0.2f MB' %(content_size / chunk_size / 1024)) # 换算单位
with open(path,'wb') as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data) # 已下载的文件大小
if __name__ == '__main__':
for i in range(10):
url = 'http://api.vc.bilibili.com/board/v1/ranking/top?'
num = i*10 + 1
html = get_json(url)
infos = html['data']['items']
for info in infos:
title = info['item']['description'] # 小视频的
video_url = info['item']['video_playurl'] # 小视频的下载链接
print(title)
# 为了防止有些视频没有提供下载链接的情况
try:
download(video_url,path='videos/%s.mp4' %title)
print('成功下载一个!')
except BaseException:
print('凉凉,下载失败')
pass
time.sleep(int(format(random.randint(2,8)))) # 设置随机等待时间爬取效果如下:

爬取的文件:

生成一个windows平台可执行exe程序
工具安装:pip install PyInstaller
生成exe程序:
pyinstaller -i test.ico -F Grasp.py
打包过程:
打包好的文件:
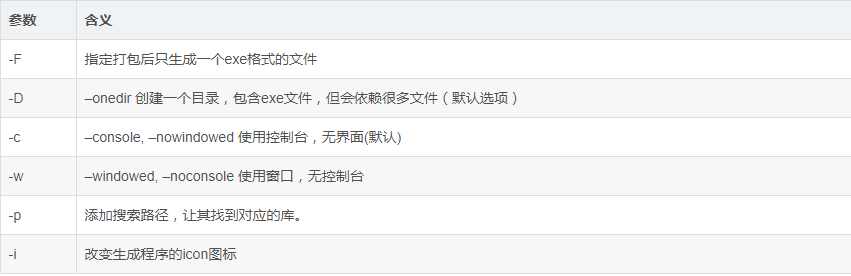
参数含义:
程序:

百度云下载链接
链接:百度云
提取码:hqhr







