
今天,我们将和大家分享一些用于数据科学任务的Python库,这些库并不常见,它们不如panda、scikit-learn、matplotlib等知名,但却十分实用,下面就一起来看看都有哪些库:
1. Wget
数据提取,尤其是从网络中提取数据,是数据科学家的重要任务之一。Wget是一个免费的工具,用于从Web下载非交互式的文件,它支持HTTP、HTTPS和FTP协议,以及通过HTTP代理进行检索。由于它是非交互式的,所以即使用户没有登录,它也可以在后台工作。因此,她很适合用于下载一个网站或一个页面的所有图像。
(项目地址:https://pypi.org/project/wget/)
安装:
- $ pip install wget
示例:
- import wget
- url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'
- filename = wget.download(url)
- 100% [................................................] 3841532 / 3841532
- filename
- 'razorback.mp3'
2. Pendulum
对于那些需要在Python项目中使用日期时间的人来说,Pendulum就是一项不错的项目选自。它是一个用于简化datetimes操作的Python包。它完全可以替代Python的原生类。
(项目地址:https://github.com/sdispater/pendulum)
安装:
- $ pip install pendulum
示例:
- import pendulum
- dt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto')
- dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver')
- print(dt_vancouver.diff(dt_toronto).in_hours())
- 3
3. imbalanced-learn
事实上,当每个类的样本数量几乎相同的情况下,分类算法的效果是最好的,但在实际项目中大部分的数据集是不平衡的,这些数据集对机器学习算法的学习阶段和后续预测都有影响,imbalanced-learn的创建就是为了解决此类问题,它与scikit-learn兼容,是scikit-learn-contrib项目的一部分。下次如果你遇到不平衡的数据集时,考虑一下它。
(项目地址:https://github.com/scikit-learn-contrib/imbalanced-learn)
安装:
- pip install -U imbalanced-learn
- # or
- conda install -c conda-forge imbalanced-learn
4. FlashText
在NLP任务中清理文本数据通常需要替换句子中的关键字或从句子中提取关键字。这类操作一般使用正则表达式来完成,但是如果搜索的关键词数量达到数千个,就会变得很麻烦。Python的FlashText模块是基于FlashText算法,它为这种情况提供了一个合适的替代方案。FlashText最好的部分是,不管搜索词的数量是多少,运行时都是一样的。
(项目地址:https://github.com/vi3k6i5/flashtext)
安装:
- $ pip install flashtext
示例:
- from flashtext import KeywordProcessor
- keyword_processor = KeywordProcessor()
- # keyword_processor.add_keyword(<unclean name>, <standardised name>)
- keyword_processor.add_keyword('Big Apple', 'New York')
- keyword_processor.add_keyword('Bay Area')
- keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
- keywords_found
- ['New York', 'Bay Area']
关键词替换:
- keyword_processor.add_keyword('New Delhi', 'NCR region')
- new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
- new_sentence
- 'I love New York and NCR region.'
5. Fuzzywuzzy
这个名字听起来确实很奇怪,但是涉及到字符匹配时,fuzzywuzzy是一个非常有用的库。可以快速实现诸如字符串匹配度、令牌匹配度等操作。它还可以方便地匹配保存在不同数据库中的记录。
(项目地址:https://github.com/seatgeek/fuzzywuzzy)
安装:
- $ pip install fuzzywuzzy
示例:
- from fuzzywuzzy import fuzz
- from fuzzywuzzy import process
- # Simple Ratio
- fuzz.ratio("this is a test", "this is a test!")
- 97
- # Partial Ratio
- fuzz.partial_ratio("this is a test", "this is a test!")
- 100
6. PyFlux
时间序列分析是机器学习领域最常遇到的问题之一。PyFlux是为处理时间序列问题而构建的Python开源库。该库拥有一系列优秀的现代时间序列模型,包括但不限于ARIMA、GARCH和VAR模型。总之,PyFlux为时间序列建模提供了一种高效的方法。值得尝试。
(项目地址:https://github.com/RJT1990/pyflux)
安装:
- pip install pyflux
7. Ipyvolume
结果交流是数据科学的一个重要方面,可视化是一个很大的优势,IPyvolume是一个Python库,用于在Jupyter笔记本中可视化三维图形(如三维立体图等),遗憾的是目前它还处于测试版本阶段。
(项目地址:https://github.com/maartenbreddels/ipyvolume)
安装:
- Using pip
- $ pip install ipyvolume
- Conda/Anaconda
- $ conda install -c conda-forge ipyvolume
示例:
8. Dash
Dash是一个用于构建Web应用程序的高效Python框架。它是基于Flask、Plotly.js和React.js创建的,并结合了现代UI元素(如下拉框、滑块和图形)与用户分析性Python代码绑定在一起,而不需要再借助Javascript。Dash非常适合构建数据可视化应用。然后可以在Web浏览器中呈现这些应用程序。
(项目地址:https://github.com/plotly/dash)
安装:
- pip install dash==0.29.0 # The core dash backend
- pip install dash-html-components==0.13.2 # HTML components
- pip install dash-core-components==0.36.0 # Supercharged components
- pip install dash-table==3.1.3 # Interactive DataTable component (new!)
示例:
9. Bashplotlib
Bashplotlib是一个Python包和命令行工具,用于在终端生成基本的绘图,使用Python编写的,当用户无法访问GUI时,可视化数据就变得很方便。
安装:
- pip install bashplotlib
示例:
- scatter --file data/texas.txt --pch .
- hist --file data/exp.txt
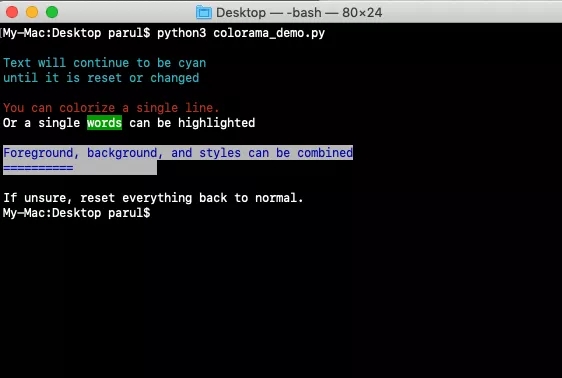
10. Colorama
colorama是一个Python专门用来在控制台、命令行输出彩色文字的模块,可以跨平台使用,在windows下linux下都工作良好。它使用标准的ANSI转义码来着色和样式终端输出。(项目地址:https://github.com/tartley/colorama)
安装:
- pip install colorama
示例:
- import colorama
- from colorama import Fore, Back, Style
- colorama.init()
- # Set the color semi-permanently
- print(Fore.CYAN)
- print("The Text will appear in cyan until it is reset")
- print(Style.RESET_ALL)
- # Colorize a single line and then reset
- print(Fore.RED + 'Colorize a single line in RED' + Style.RESET_ALL)
- # Colorize a single word in the output
- print('You can also colorize a single word' + Back.GREEN + 'words' + Style.RESET_ALL + ' can be highlighted')
- # Combine foreground and background color
- print(Fore.BLUE + Back.WHITE)
- print('Foreground, background, and styles can be combined')
- print("========== ")
- print(Style.RESET_ALL)
- print('Reset everything back to normal.')
输出如下:
以上就是我推荐的有关于处理数据科学方面任务的Python库,不知道有没有你喜欢的。








{kind=link}
{kind=link}
{kind=link}
{kind=link}