
欢迎各位阅读本篇,Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。
有人认为 Hadoop 正在失败,但硅谷数据管理 Hortonworks 的 Vamsi K. Chemitiganti 并不这么看,他在自己的博客上写了一篇论述自己看法的文章,他认为达尔文式的开源生态系统正在确保Hadoop 成为稳固和成熟的技术平台。机器之心对这篇反驳文章进行了编译介绍,但本文内容并不代表机器之心的观点。

为什么 Hadoop 正在发展壮大
过去两年来,我一直致力于大数据方面的研究,并在这段时间里经历了令人感到震撼的变革,因为我一直在全球各地为银行业的领导者们提供咨询服务。
我必须站出来反对了。在那篇文章中,作者的讨论具有建设性,但问题在于其讨论基于一些毫无根据的假设。在深入研究之前,我们要考虑其中的背景。
公司业务中数字架构的出现意味着公司能够与全球客户/消费者/病人持续地在线互动。其目的并不仅仅是为了提供友好的可视化内容,而是为了提供跨渠道,多类型的个性化服务。
移动应用首先迫使企业将服务形式升级为与消费者在多渠道中展开沟通。例如银行业,所有银行现在都涵盖了四到五种服务方式:移动 app、电子银行、呼叫中心、快捷银行等。医疗保健业有希望成为下一个改变面貌的行业,护理人员已经开始采用 iPad 来协助诊断,存储和处理患者的药物和疾病数据。大数据技术的发展是为了克服以往方法(RDBMS 和 EDW)的局限性,解决在数字应用堆栈中数据架构和分析的挑战。
这些挑战包括:
数据体量扩大的挑战。
公司数据种类的飞速膨胀。
Hadoop 显然也有自己的限制——例如支持低延迟 BI(Business Intelligence,商业智能)查询的能力。但是 Hadoop 之前的方法显然有更多的缺陷,它们无法处理和管理大量数据,从而为数字架构的业务带来了两大挑战。第一个挑战是在企业数据流架构中实时提供洞见;第二个挑战是进行进一步分析的能力:快速进行预测分析和深度学习(经常需要每秒处理百万条信息),从而能够跨领域解决复杂问题。Hadoop 是唯一能让这些挑战化为有效商业机会的方式。
达尔文式的开源生态系统正在确保 Hadoop 成为稳固和成熟的技术平台。
目前的绝大多数 Hadoop 大数据项目(超过 25 个)都依靠开源社区在 Apache 生态系统中孵化、开发和维护。开源社区本质上是达尔文式的。它专注于代码质量和行业应用,依赖于路线图和提交者的正确性,如果一个项目缺乏这些,那它会很快走进坟墓。换句话说,生态系统中没有落后者的位置。
让我们看看那篇文章中作者的主要假设吧。
假设 1:Hadoop 采用不再增长,最多持平
我日常工作中的最重要的部分是与多个客户合作探讨他们的业务计划以及寻找应用技术来解决这些复杂难题的方法。
我可以证明最大企业对 Hadoop 的采用绝对没有停滞不前。尽管我的观点肯定是道听途说,而且不是来自于企业内部的内幕,但在银行业、电信业、制造业和保险业,Hadoop 的采用却实实在在地在飞涨。
在早期就与领先的供应商合作的企业已经或多或少找到了将这项技术应用于它们的业务难题的好方法。采用 Hadoop 的模式正在成熟,而且它们也正在意识到其中巨大的商业价值。一家领先的供应商 Hortonworks 在实现 1 亿美元年收入的道路上比其它任何科技创业公司都跑得快——这是该领域潜力的有力证明。Cloudera 刚刚已经上市。在见证着这样的增长的同时,我们也看到领先的 EDW 供应商的收入和股价却略有下跌。
我预计,未来 5-7 年内就会出现第一家年收入达到 10 亿美元的大数据「创业公司」,与备受尊敬的开源先驱 Red Hat 相比还多少快一点。至少,Hadoop 项目能帮助企业从昂贵和不灵活的企业数据仓库项目上节省成百上千万美元。几乎所有组织都已经开始部署 Hadoop,以作为它们的企业登陆区(ELZ:Enterprise Landing Zone),从而增强它们的 EDW。
假设 2:使用 Hadoop 创造的项目的商业价值不明显
该作者在这方面还有点道理,但让我解释一下为什么这是组织机构所面临的难题,而实际上并不是任何技术堆栈(中间件或云或大数据)的过错。这个难题在于:寻找大数据项目的商业价值往往是一个精细活,涉及到整个复杂的组织结构。IT 部分当然可以将 POC(概念验证)作为一门科学或一项「一次性简历构建」项目而开始,但其业务线需要从一开始就参与进来,比其它任务技术类别都早。大数据并不是关于存储大量数据的基础设施的施工,而是关于如何在收集和策划的数据上创造业务分析。不管这些分析是简单而老套的商业智能(BI),还是数据科学导向的,它们都依赖于一个组织本身的文化和创新。
组织机构不仅在使用大数据来解决已有的业务难题(销售更多商品、检测欺诈、报告风险等),而且也在使用大数据分析得到的见解来快速实验新的业务模型。聪明的 CDO(首席数据官)应该知道如何拥有这种技术、创造合适的内部成本核算模型并将已有的业务线(LOB)项目纳入到数据湖(data lake)。
每个 CDO 在一开始时就要提出以下两个问题:
整个组织将要具备怎样的业务能力?
哪方面的数字转换可以通过大数据达到最优?
假设 3:对于 PB 级的大规模数据,大数据是唯一可行的技术解决方案
该作者写道:「如果你的企业没有巨量数据的问题,你真的用不着 Hadoop,所以数以百计的企业都对他们无用的 2 到 10 TB 的 Hadoop 集群感到非常失望——在这种规模上,Hadoop 技术没有任何优势。」
这并不能从实际情况上观察到,因为以下三个原因:
首先,大多数 TB 级的项目都是租用的更大规模的集群。数据湖的真正价值是在跨组织的数据库上构建,而在此之前,这么做需要高昂的成本,或者难度太大。一旦你将所有数据都集中到了一处,那么你就可以将它们混合起来,以一种前所未有的方式对其进行分析。
其次,正如我将在下面说的那样,许多玩家正在使用大数据来在操作 TB 级的数据的同时获得关键的「速度」优势。
第三,我推荐每一个客户从「小」开始,并将数据湖用作企业登陆区——用于企业常规业务运营所产生的数据。Hadoop 集群不仅可被用作廉价的存储,但也可用于执行一些重复但计算密集型的数据处理任务(数据连接、排序、分割、binning 等等),这能将企业数据仓库(EDW)从一系列繁重的工作中解脱出来。
假设 4:很难找到 Hadoop 人才
作者的话——「尽管 57% 的人认为,技术鸿沟是主要原因,这个比例也不会一夜之间发生改变。
这正好与 Indeed 的发现吻合:他们追踪了『Hadoop 测试』岗位情况,2014 年中期,招聘广告百分比最高为 0.061%,但是,2016 年增至 0.087%,18 个月里增加了 43%。这些情况可能预示着,采用 Hadoop 并没有下降到那些传闻臆想所暗示的程度,不过,公司也很容易发现他们很难从公司当前团队的 Hadoop 那里实现价值,他们需要更好的专业技术人才。」
这个技术鸿沟是确实存在的且主要存在这三个领域——数据科学家、数据工程师以及 Hadoop 管理员。不过,这并不是 Hadoop 独有的难题,实际上每种新技术都会有这种烦恼。公司要通过增强内部员工的的技能、与全球系统集成商(GSI)、与学术界合作来弥合这个鸿沟。实际上,从事大数据项目的前景会吸引人才加入组织。
大型组织该如何启动自己的大数据之旅?
避免跌进「大数据并不带来价值」这个坑的最佳措施是什么?
以最高级别推进大数据以及大数据商业和技术应用的讨论。大数据需要在最高级别上成为组织 DNA 的一部分,需要和其他驱动产业的主要技术一起加以讨论——比如云技术、移动技术、开发运营以及社交、API 等。
打造或者组建一支首席数据官领导下的团队。团队可以是现实的,也可是虚拟的,但都需要将组织策略纳入考虑。
建立一个卓越中心(COE:Center of Excellence)或者类似这样的联合渠道,在这里,中心团队可以就这些项目与不同的业务线合作。
作为 COE 的一部分,还要制定一个采纳最新技术的流程。
合适的监管和项目监督
找出那些能驱动大数据项目的关键业务标准,包括对期望增长加速、成本削减、风险管理以及实现竞争优势的详细分析。
让业务线参与进来,以迭代的方式发展这些能力。几乎所有成功的大数据项目都是以一种开发运营的方式得以推进的。
总结
大数据生态系统和 Hadoop 技术为全球垂直领域的组织提供了一个成熟、稳定和功能丰富的平台来实施复杂的数字化项目。不过,技术的成熟度仅仅是一个必要因素。就旨在创新的思维模式而言,组织能力才是驱动内部变革的关键力量。因此,在商业领导、IT 团队以及内部领域专家和管理各个方面,孕育学习的思维模式也很关键。
对于大数据来说,普世座右铭「一分耕耘一分收获」更加真实。尽管很容易将某个项目的失败归咎给一项技术、某个公司或者某个技术不佳的人员,但是,你应该与安于现状的思维模式作斗争。确认竞争没有停下来时,你才能安心。
分享:hadoop优点介绍
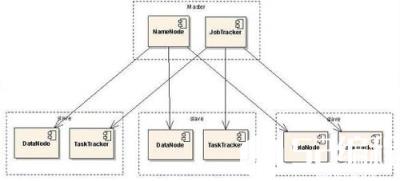
hadoop架构替代数据仓 Hadoop是一个能够对大量数据进行分布式处理的软件框架。但是 Hadoop 是以一种可靠、高效、可伸缩的方式进行处理的。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop 还是可伸缩的,能够处理 PB 级数据。此外,Hadoop 依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
⒈高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
⒉高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
⒊高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
⒋高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
Hadoop带有用 Java 语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
小结:Hadoop 是最受欢迎的在 Internet 上对搜索关键字进行内容分类的工具,但它也可以解决许多要求极大伸缩性的问题。









