
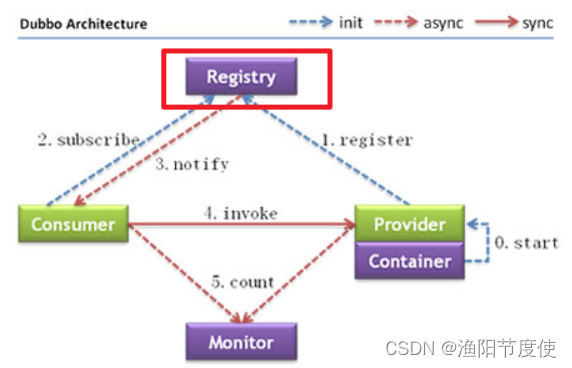
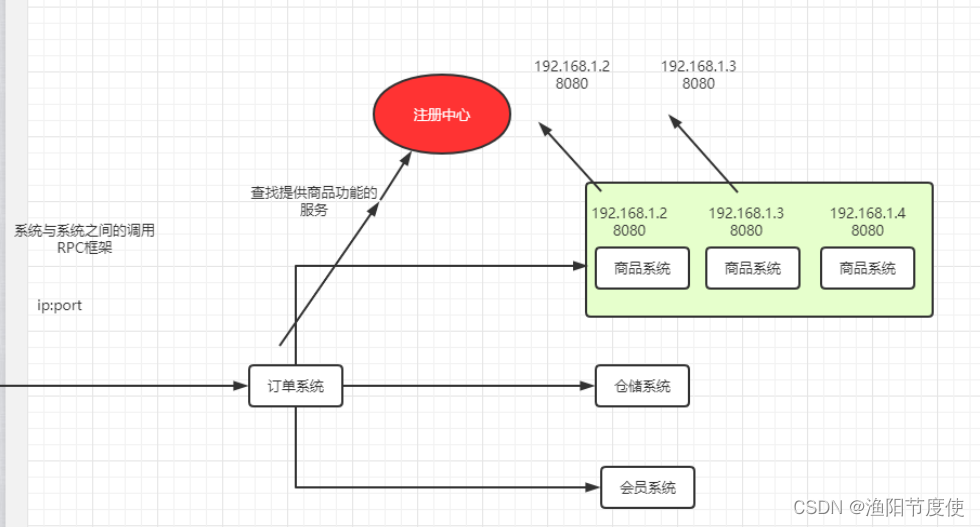
为什么要使用Zookeeper
dubbo需要一个注册中心,而Zookeeper是我们在使用Dubbo是官方推荐的注册中心
Zookeeper介绍

Zookeeper的集群机制
Zookeeper是为了其他分布式程序提供服务的,所以不能随便就挂了。Zookeeper的集群机制采取的是半数存活机制。也就是整个集群节点中有半数以上的节点存活,那么整个集群环境可用。这也是为什么说zk的集群最好是奇数个节点。
zk的作用
| 序号 | 功能 |
|---|---|
| 1 | 为别的分布式程序服务的 |
| 2 | 本身就是一个分布式程序 |
| 3 | 主从协调 服务器节点动态上下线 统一配置管理 分布式共享锁 统一名称服务 |
| 4 | 管理(存储,读取)用户程序提交的数据 并为用户程序提供数据节点监听服务 |
Zookeeper 节点的三种角色
Leader
Leader是Zookeeper集群工作的核心,其主要工作是:
- 事务请求的唯一调度和处理者,保证集群事务处理的顺序性。
- 集群内部各服务器的调度者
Follower
Follower是zookeeper集群的跟随者,主要工作是:
- 处理客户端非事务性请求(读取数据),转发事务请求给Leader服务器
- 参与事务请求Proposal的投票
- 参与Leader选举投票
Observer
Observer充当观察者的角色,观察Zookeeper集群的最小状态变化并将这些状态同步过来,其对于非事务请求可以独立处理,对于事务请求,会转给Leader节点进行处理。Observer不会参与投票,包括事务请求Proposal的投票和Leader选举投票
###Zookeeper 节点的四种状态
在知道了 Zookeeper 中有三种角色后,我们可能会问: Zookeeper 是如何知道自己目前是什么角色的呢?
在 ZAB 协议中定义:通过自身的状态来区分自己的角色的,在运行期间各个进程可能出现以下四种状态之一:
- Looking:不确定Leader状态,该状态下的服务器认为当前集群中没有Leader,会发起Leader选举
- Following:跟随者状态,表明当前服务器角色是Follower,并且它知道Leader是谁
- Leading:领导者状态,表明当前服务器角色是Leader,它会维护与Follower间的心跳
- Observing:观察者状态,表明当前服务器角色是Observer,与Follower唯一的不同在于不参与选举,也不参与集群写操作时的投票
在组成 ZAB 协议的所有进程启动的时候,初始化状态都是 LOOKING 状态,此时进程组中不存在 Leader,选举之后才有,在进行选举成功后,就进入消息广播模式,此时 Zookeeper 集群中的角色状态就不再是 LOOKING 状态。
集群环境准备
节点的映射关系
每个节点设置相应的ip和主机名的映射关系,方便集群环境的部署
修改hosts配置文件中的信息

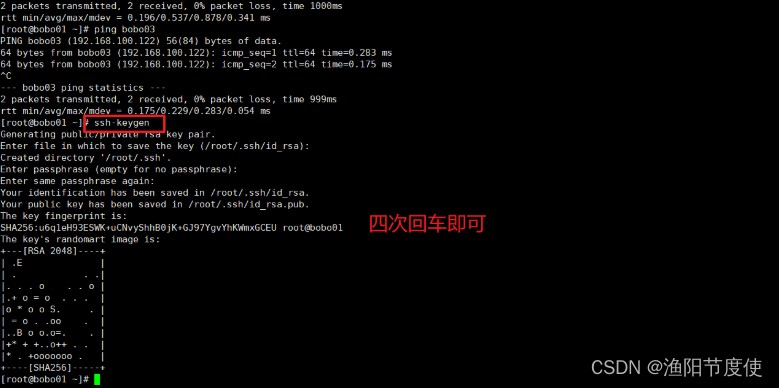
配置免密登录
生成公钥和私钥
ssh-keygen输入命令后根据提示,四次回车即可
发送公钥给需要免密登录的节点
ssh-copy-id zk01ssh-copy-id zk02ssh-copy-id zk03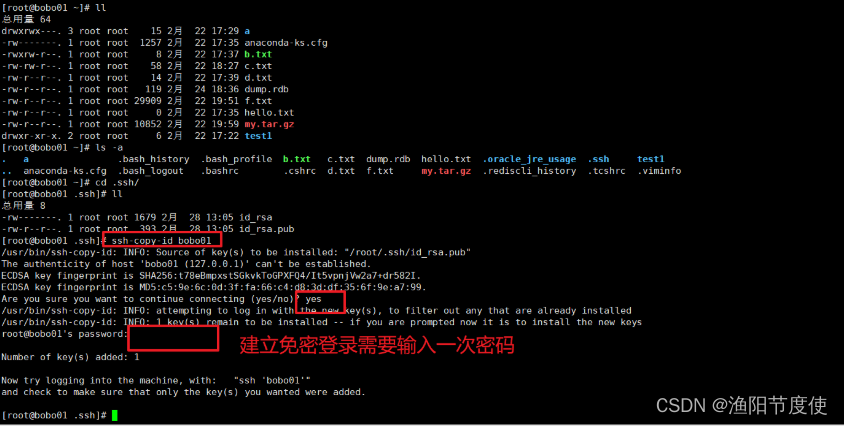
节点和节点发送文件通过scp命令实现
scp -r b.txt bobo01:/root/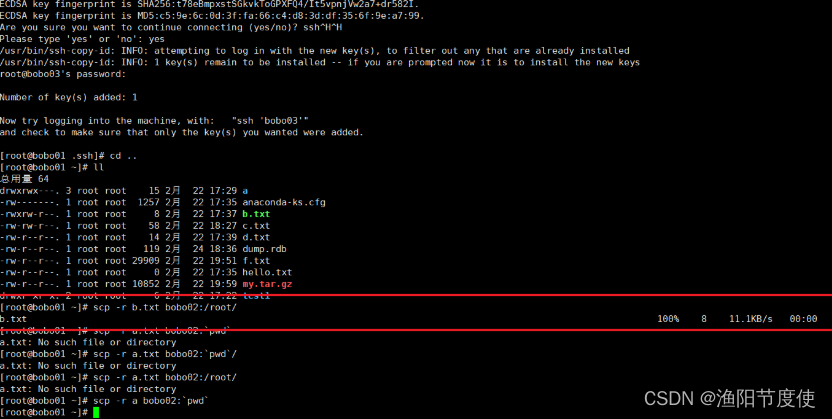
关闭防火墙
查看防火墙状态
firewall-cmd --state停止防火墙
systemctl stop firewall.service禁止开机启动
systemctl disable firewall.serviceZookeeper的选举机制
Leader主要作用是保证分布式数据一致性,即每个节点的存储的数据同步。
服务器初始化时Leader选举
Zookeeper由于自身的性质,一般建议选取奇数个节点进行搭建分布式服务器集群。以3个节点组成的服务器集群为例,说明服务器初始化时的选举过程。启动第一台安装Zookeeper的节点时,无法单独进行选举,启动第二台时,两节点之间进行通信,开始选举Leader。
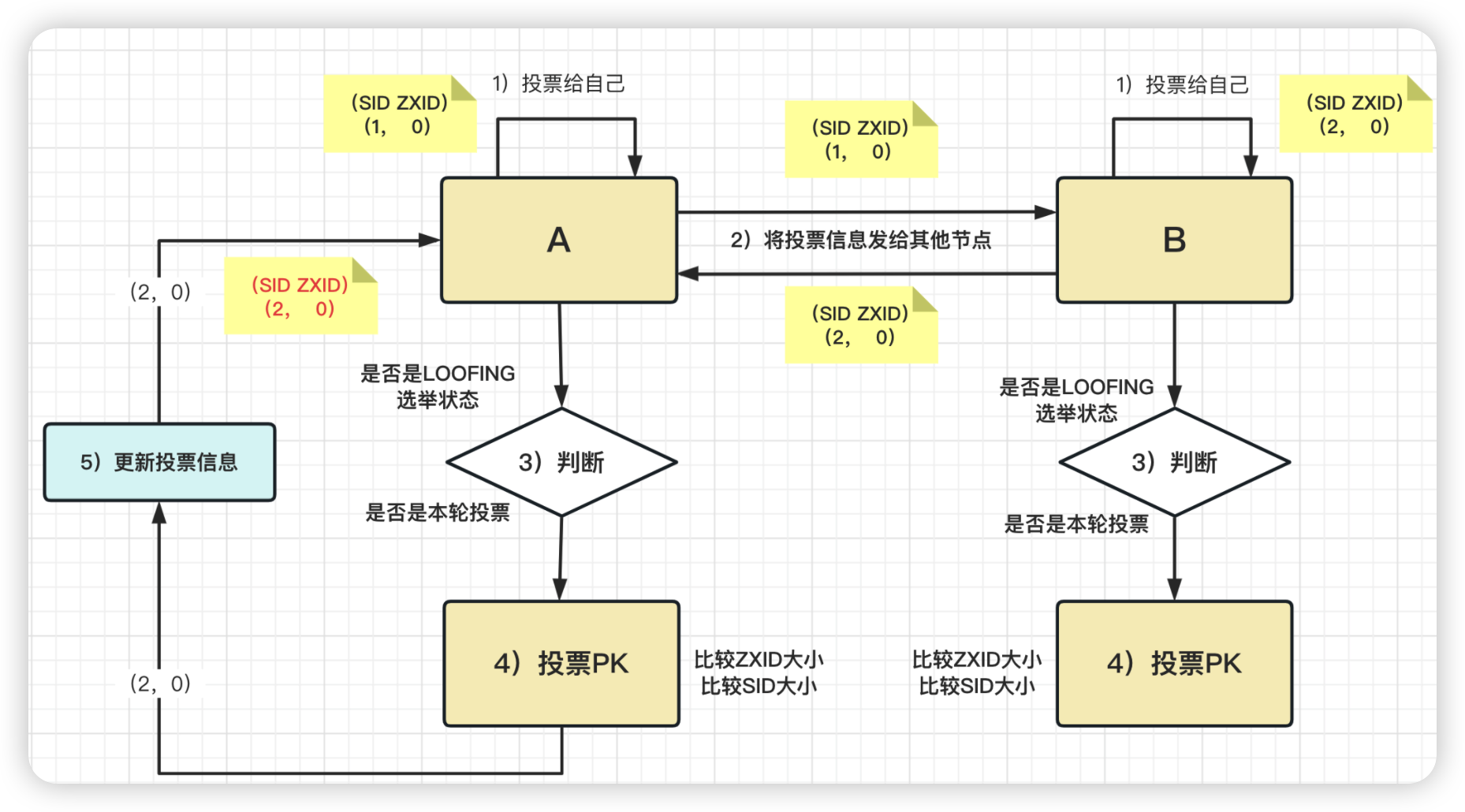
- 每个Server投出一票。第一次他们都投给自己作为Leader,投票内容未(SID,ZXID)。
SID为Server的id,即启动ZK时配置文件中的myid;
ZXID为事务id,为节点的更新程序,ZXID越大,代表Server对ZK节点的操作越新。由于服务器初始化,
每个Sever上的Znode为0,所以Server1投的票为(1,0),Server2为(2,0)。两Server将各自投票发给集群中其他机器。 - 每个Server接收来自其他Server的投票。集群中的每个Server先判断投票的有效性,如检查是不是本轮的投票,是不是来Looking状态的服务器投的票。
- 对投票结果进行处理。处理规则为:
- 首先对比ZXID。ZXID大的服务器优先作为Leader
- 若ZXID系统,如初始化时,每个Server的ZXID都是0
- 就会比较sid即myid,myid大的选出来做Leader。
首次选举对于Server而言,他接受到的投票为(2,0),因为自身的票为(1,0),所以此时它会选举Server2为Leader,
将自己的更新为(2,0)。而Server2收到的投票为Server1的(1,0)由于比他自己小,
Server2的投票不变。Server1和Server2再次将票投出,投出的票都为(2,0)
- 统计投票。每次投票后,服务器都会统计投票信息,如果判定某个Server有过半的票数,俺么该Server就是Leader。首次投票对于Server1和Server2而言,统计出已经有两台机器接收了(2,0)的投票信息,此时认为选出了Leader。
- 改变服务器的状态。当确定了Leader之后,每个Server更新自己的状态,
Leader将状态更新为Leading,Follower将状态更新为Following。
服务器运行期间的Leader选举
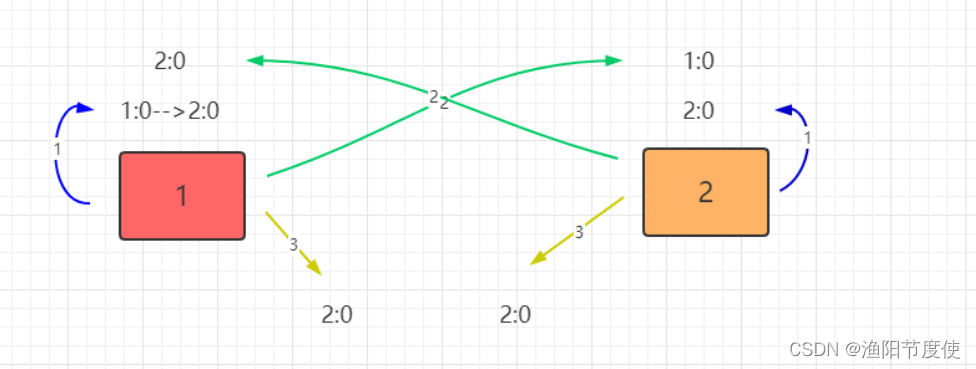
ZK运行期间,如果有新的Server加入,或非Leader节点挂了,那么Leader会同步数据给新的Server或寻找其他备用Server替代宕机的Server。若Leader宕机,此时集群暂停对外服务,开始在内部选举新的Leader。假设当前集群中有Server1、Server2、Server3三台服务器,Server2为当前集群的Leader,由于意外情况,Server2宕机了,便开始进入选举状态。过程如下
1 变更状态。其他非Observer服务器将自己的状态改变成Looking,开始进入Leader选举。
2. 每个Server投出1张票(myid,ZXID),由于集群运行过,所以每个Server的ZXID可能不同。
假设Server1的ZXID为145,Server3的为122,第一轮投票中,Server1和Server3都投自己,
票分别为(1,145)、(3,122),将自己的票发送给集群中所有机器。
3. 每个Server接收接收来自其他Server的投票,接下来的步骤与初始化时相同。
恢复模式的两个原则
当集群正在启动过程中,或 Leader 与超过半数的主机断连后,集群就进入了恢复模式。对于要恢复的数据状态需要遵循两个原则。
已被处理过的消息不能丢失
被丢弃的消息(原Leader未提交的事务)不能再现
1.已被处理过的消息不能丢失(部分follower提交了)
当 Leader 收到超过半数 Follower 的 ACKs 后,就向各个 Follower 广播 COMMIT 消息, 批准各个 Server 执行该写操作事务。当各个 Server 在接收到 Leader 的 COMMIT 消息后就会在本地执行该写操作,然后会向客户端响应写操作成功。
但是如果在非全部 Follower 收到 COMMIT 消息之前 Leader 就挂了,这将导致一种后 果:部分 Server 已经执行了该事务,而部分 Server 尚未收到 COMMIT 消息,所以其并没有执行该事务。当新的 Leader 被选举出,集群经过恢复模式后需要保证所有 Server 上都执行 了那些已经被部分 Server 执行过的事务。
2.被 Leader 提出的但没有被提交的消息不能再现(无follower提交)
当新事务在 Leader 上已经通过,其已经将该事务更新到了本地,但所有 Follower 还都没有收到 COMMIT 之前,Leader 宕机了(比前面叙述的宕机更早),此时,所有 Follower 根本 就不知道该 Proposal 的存在。当新的 Leader 选举出来,整个集群进入正常服务状态后,之 前挂了的 Leader 主机重新启动并注册成为了 Follower。
若那个别人根本不知道的 Proposal 还保留在那个主机,那么其数据就会比其它主机多出了内容,导致整个系统状态的不一致。所以,该 Proposa 应该被丢弃。类似这样应该被丢弃的事务,是不能再次出现在集群中的, 应该被清除。
myid与zxid
myid : 每个 Zookeeper 服务器,都需要在数据文件夹下创建一个名为 myid 的文件,该文件包含整个 Zookeeper 集群唯一的 ID
例如,某个 Zookeeper 集群包含三台服务器,在配置文件中,server.后面的数据即为 myid
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
zxid : 类似于 RDBMS 中的事务ID,用于标识一个 Proposal ID,为了保证顺序性,ZXID 必须单调递增.
ZAB协议
ZAB(Zookeeper Atomic Broadcast)协议是Apache Zookeeper分布式协调服务中使用的一种原子广播协议。Zookeeper是一个开源的、高性能的分布式协调服务,用于管理分布式系统中的配置信息、命名服务、分布式锁等。ZAB协议是Zookeeper的核心协议,通过确保Zookeeper集群中所有服务器之间的事务广播顺序,它实现了Zookeeper数据的一致性。
Zab 协议核心
Zookeeper采用ZAB协议的核心就是只要一台服务器提交了Proposal(事务),就要确保所有服务器最终都能正确提交Proposal,这也是CAP/BASE最终一致性的体现。(选举的核心)
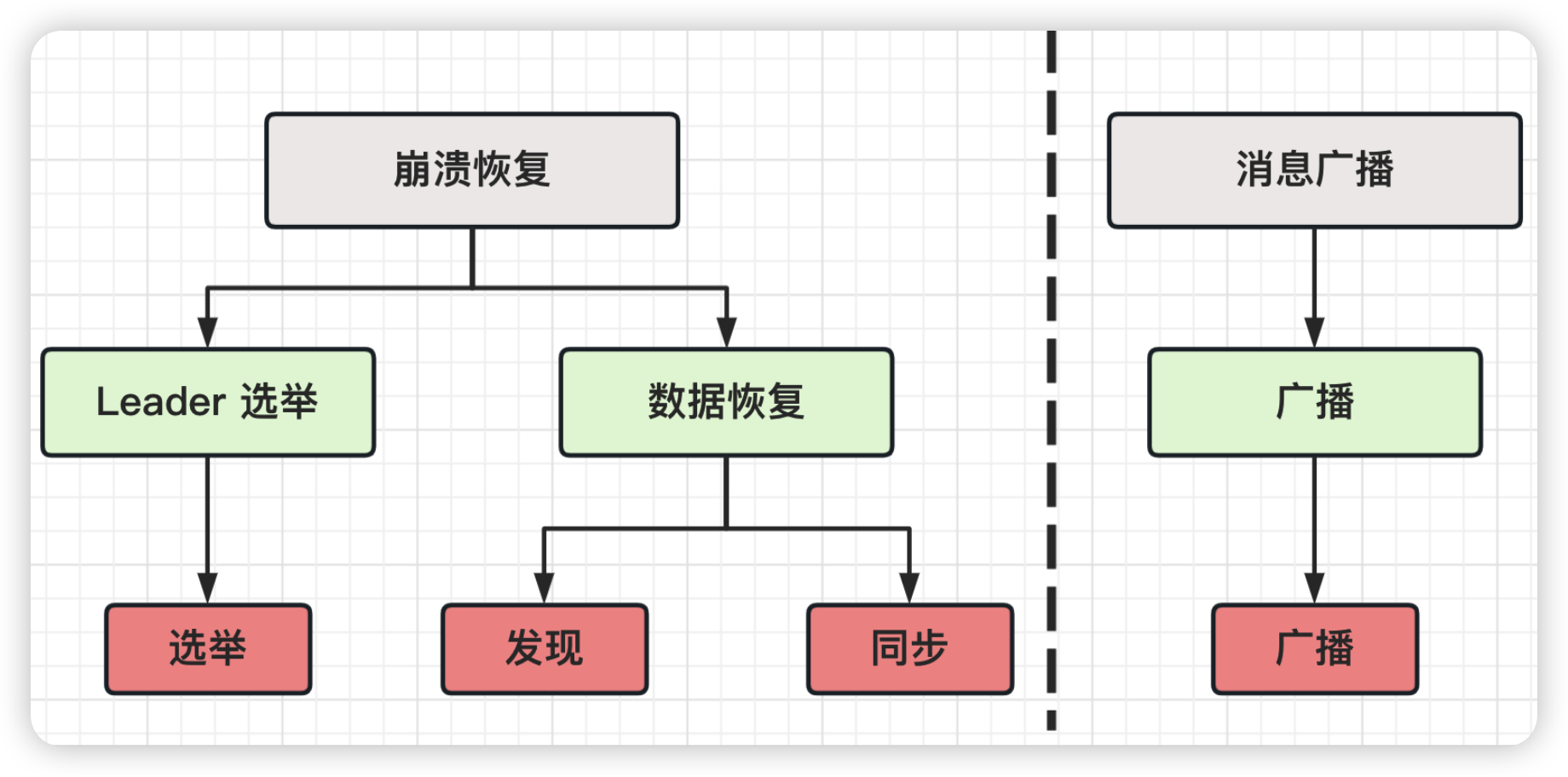
从大体上看,Zab 协议的原理可细分为四个阶段:
选举(Leader Election)发现(Discovery)同步(Synchronization)广播(Broadcast)
但是在 ZooKeeper 的实现中,将发现和同步两部分内容合成数据恢复一部分,所以按实现划分可以分为三个阶段:(选举的核心)Leader选举(Fast Leader Election)数据恢复(Recovery Phase)广播(Broadcast)
Zab 协议按照功能的不同,有两种模式:一种是消息广播模式,另一种是崩溃恢复模式。
消息广播模式用于处理客户端的请求,崩溃恢复模式用于在节点意外崩溃时能够快速恢复,继续对外提供服务,让集群达成高可用状态。
1) 消息广播模式
- 在Zookeeper集群中数据副本的传递策略就是采用消息广播模式,Zookeeper中的数据副本同步方式与2PC方式相似但却不同,2PC是要求协调者必须等待所有参与者全部反馈ACK确认消息后,再发送commit消息,要求所有参与者要么全成功要么全失败,2PC方式会产生严重的阻塞问题。
- 而Zookeeper中Leader等待Follower的ACK反馈是指:只要半数以上的Follower成功反馈即可,不需要收到全部的Follower反馈。
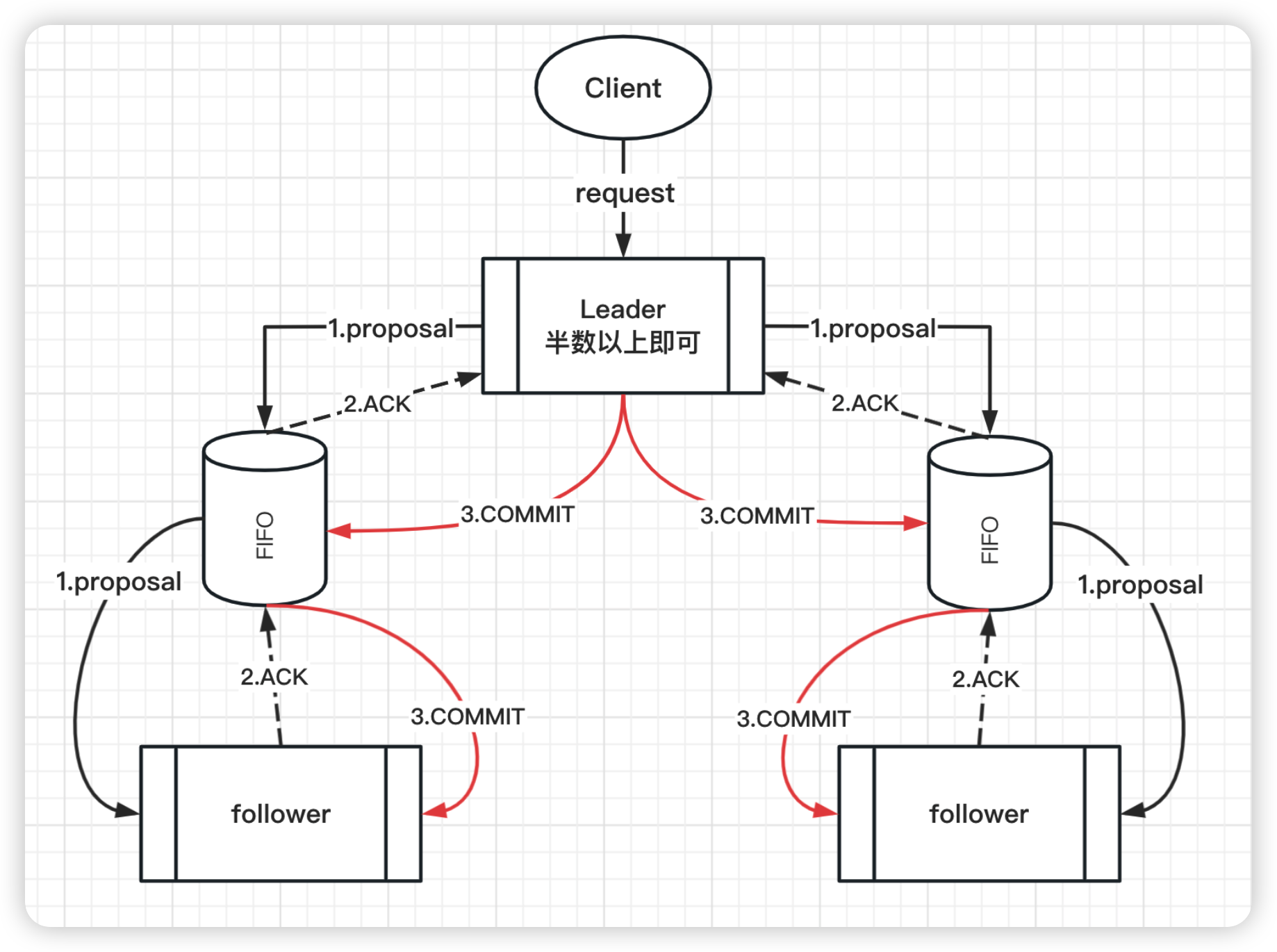
Zookeeper 中广播消息步骤:
- 客户端发起一个写操作请求
- Leader服务器处理客户端请求后将请求转为Proposal(事务),同时为每个Proposal分配一个全局唯一ID,即ZXID
- Leader服务器与每个Follower之间都有一个队列,Leader将消息发送到该队列
- Follower机器从队列中取出消息处理完(写入本地事务日志中)后,向LEader服务器发送ACK确认
- Leader服务器收到半数以上的Follower的ACK后,即可以发送Commit
- Leader向所有的Follower服务器发送Commit消息
崩溃恢复模式
一旦 Leader 服务器出现崩溃或者由于网络原因导致 Leader 服务器失去了与过半 Follower 的联系,那么就会进入崩溃恢复模式。
Zookeeper 集群中为保证任何进程能够顺序执行,只能是 Leader 服务器接收写请求,其他服务器接收到客户端的写请求,也会转发至 Leader 服务器进行处理。
Zab 协议崩溃恢复需满足以下2个请求:
- 确保已经被 Leader 提交的 proposal 必须最终被所有的 Follower 服务器提交
- 确保丢弃已经被 Leader 提出的但没有被提交的 Proposal(事务)
也就是新选举出来的 Leader 不能包含未提交的 Proposal(事务),必须都是已经提交了的 Proposal 的 Follower 服务器节点,新选举出来的 Leader 节点中含有最高的 ZXID,所以,在 Leader 选举时,将 ZXID 作为每个 Follower 投票时的信息依据。这样做的好处是避免了 Leader 服务器检查 Proposal 的提交和丢弃工作。(具体看上面的恢复规则)
Zookeeper是不是强一致性
写操作时是强一致性,读操作则不是强一致性
强一致性
- 数据的强一致性指的是:一个外部的客户端,去请求一个分布式系统时,一旦这个数据被允许查询,那么任何一个被要求存储该数据的节点上,在任何时候都能查询到这份数据,且数据内容要求一模一样。
顺序一致性
- 写入操作顺序一致性:当多个客户端同时向ZooKeeper进行写入操作时,这些写入操作会被按照客户端发起的顺序逐个执行。ZooKeeper通过强制所有写入操作都经过Leader节点进行协调,保证了写入操作的顺序一致性(Leader节点与从节点写入的数据一定是一致的)。
- 读取数据顺序一致性:无论客户端连接到哪个ZooKeeper节点,它们在读取数据时都会获得相同的数据视图。
Zookeeper官方定义:顺序一致性。(Sequential consistency)
- zookeeper 并不能保证所有客户端在某一时刻读到的数据是一致的,客户端还是有可能读到旧数据的,但可以使用sync()方法向leader节点同步最新的已提交数据。

已上图为例,如果一个zk集群有10000台节点,当进行写入的时候,如果已经有6K个节点写入成功,zk就认为本次写请求成功。但是这时候如果一个客户端读取的刚好是另外4K个节点的数据,那么读取到的就是旧的过期数据。
在zk的官方文档中对此有解释,地址在:https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html
ZK保证了保持长链接的单个客户端,总是能得到自己保持链接的机器上的最新值,这个值不一定是Leader的最新值。如果该机器挂了,会连接到zxid不小于当前节点的机器,从而保证不会读到更旧的值。
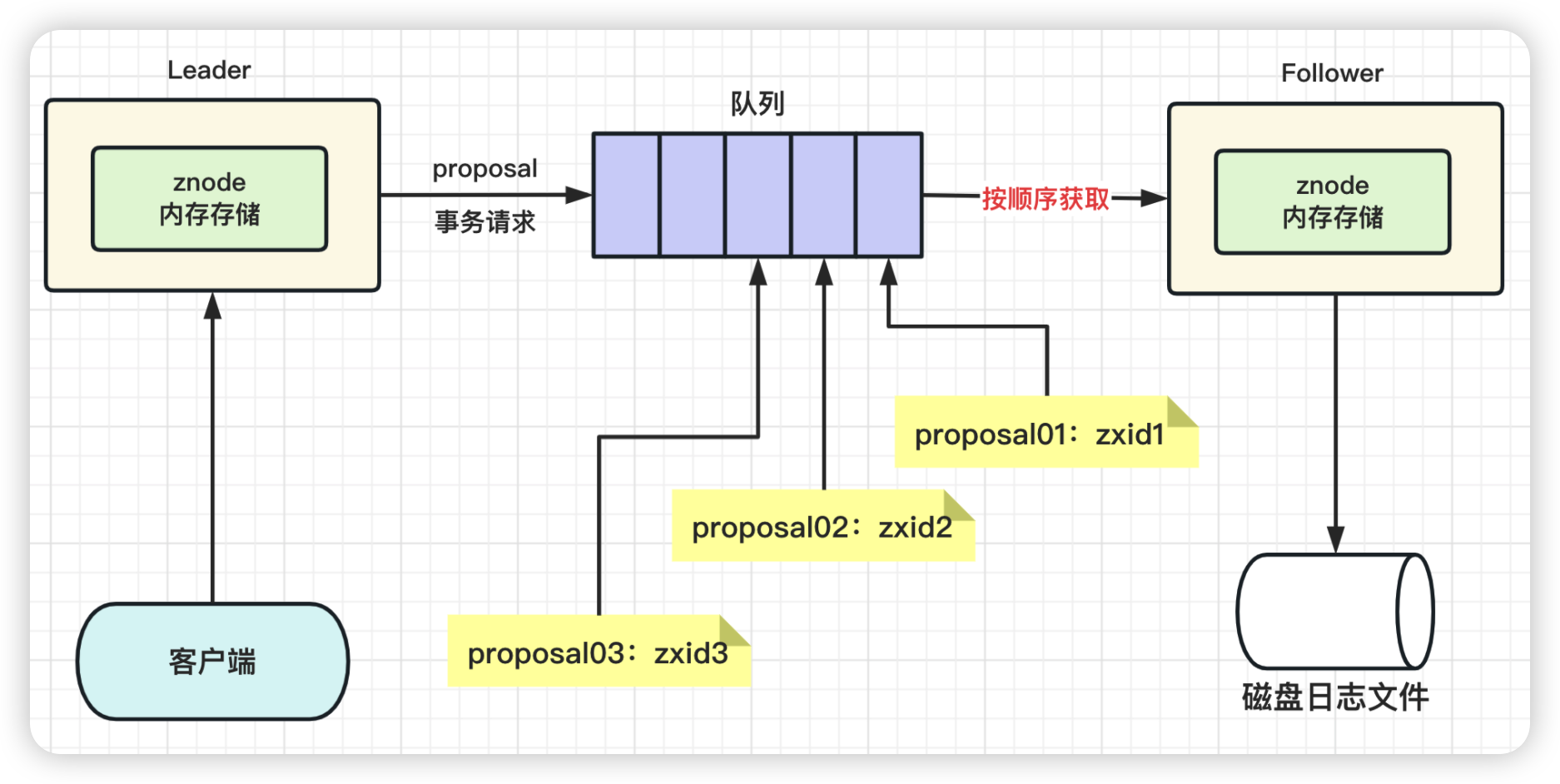
Zookeeper顺序一致性怎么做到的?
Leader 发送 proposal 时,其实会为每个 Follower 创建一个队列,都往各自的队列中发送 proposal。
Zookeeper客户端使用
配置Zookeeper的环境变量
为了简化我们每次操作Zookeeper而不用进入到Zookeeper的安装目录,我们可以将Zookeeper的安装信息配置到系统的环境变量中
vim /etc/profile添加的内容
export ZOOKEPPER_HOME=/opt/zookeeperexport PATH=$PATH:$ZOOKEEPER_HOME/bin执行source命令
source /etc/profile我们就可以在节点的任意位置操作Zookeeper了,通过scp命令将profile文件发送到其他几个节点上
scp /etc/profile zk02:/etc/客户端连接
通过bin目录下的zkCli.sh 命令连接即可
zkCli.sh
zkCli.sh默认连接的是当前节点的Zookeeper节点,如果我们要连接其他节点执行如下命令即可
zkCli.sh -timeout 5000 -server zk02:2181数据操作
Zookeeper的数据结构
- 层次化的目录结构,命名符合常规文件系统规范
- 每个节点在Zookeeper中叫做znode,并且有一个唯一的路径标识
- 节点znode可以包含数据和子节点(但是EPHEMERAL类型的节点不能有子节点)
- 客户端应用可以在节点上设置监听器
节点类型
1).znode有两种类型:
短暂性(ephemeral)(断开连接自己删除)
持久性(persistent)(断开连接不删除)
2).znode有四种形式的目录节点(默认是persistent)如下
| 序号 | 节点类型 | 描述 |
|---|---|---|
| 1 | PERSISTENT | 持久节点 |
| 2 | PERSISTENT_SEQUENTIAL | 持久有序节点(顺序节点) |
| 3 | EPHEMERAL | 短暂节点 (临时节点) |
| 4 | EPHEMERAL_SEQUENTIAL | 短暂有序节点 (临时顺序节点) |
创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,有父节点维护在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
常用命令
Zookeeper作为Dubbo的注册中心用来保存我们各个服务的节点信息,显示Zookeeper是可以实现输出的存储操作的,我们来看下Zookeeper中存储操作的基本命令
ls
ls用来查看某个节点下的子节点信息
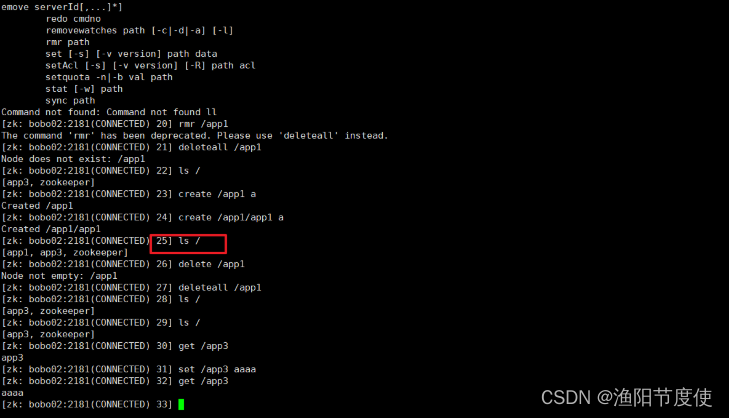
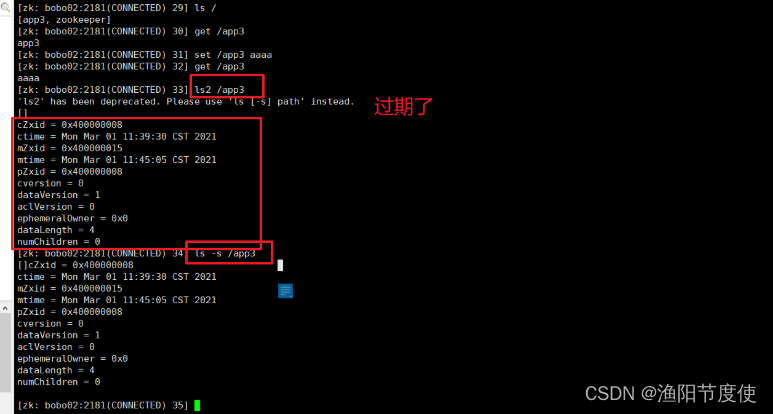
增强的命令,查看节点下的子节点及当前节点的属性信息 ls2或者 ls -s 命令
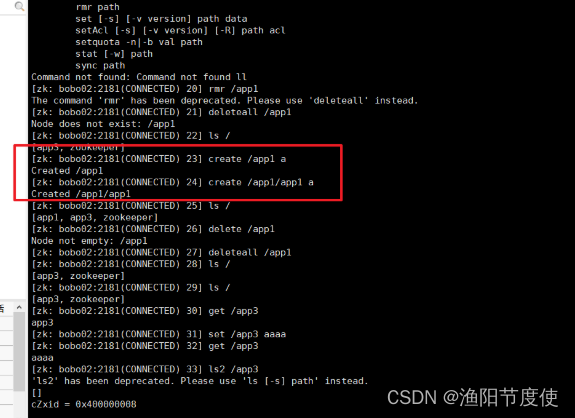
create
创建节点信息
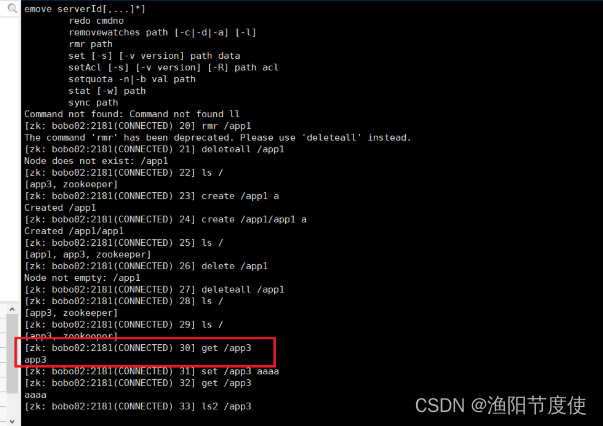
get
get命令用来查看节点的数据
如果要查看节点的属性信息那么我们可以通过get -s 来实现
delete
delete只能删除没有子节点的节点要删除非空节点可以通过 rmr 或者 deleteall 命令实现
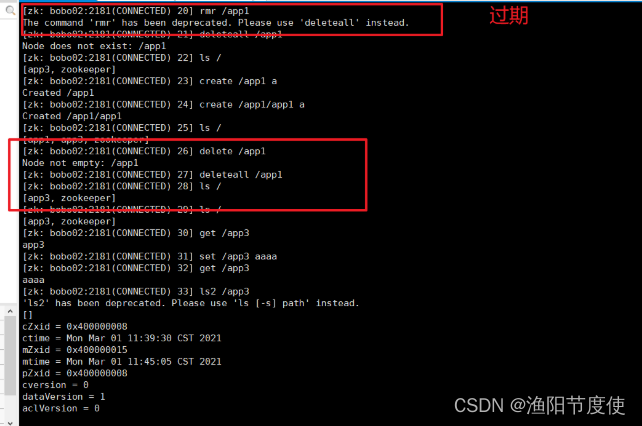
set
set命令可以用来修改节点的内容。

事件监听
监听某个节点的数据内容变化,通过get命令 带 -w 参数即可,在3.4版本的Zookeeper中是通过 get path watch 来说实现监控的

然后我们在其他节点上修改app1节点的数据,会触监听事件
Zookeeper Java API使用
pom
<dependencies><dependency> <groupId>org.apache.zookeepergroupId> <artifactId>zookeeperartifactId> <version>3.5.9version> dependency> <dependency> <groupId>com.github.sgroschupfgroupId> <artifactId>zkclientartifactId> <version>0.1version> dependency> <dependency> <groupId>junitgroupId> <artifactId>junitartifactId> <version>4.12version> dependency>dependencies>连接ZK服务,并监听节点变化
@Slf4jpublic class ConfigCenter { private final static String CONNECT_STR="192.168.40.243:2181"; private final static Integer SESSION_TIMEOUT=30*1000; private static ZooKeeper zooKeeper=null; private static CountDownLatch countDownLatch=new CountDownLatch(1); public static void main(String[] args) throws IOException, InterruptedException, KeeperException { zooKeeper=new ZooKeeper(CONNECT_STR, SESSION_TIMEOUT, new Watcher() { @Override public void process(WatchedEvent event) { if (event.getType()== Event.EventType.None && event.getState() == Event.KeeperState.SyncConnected){ log.info("连接已建立"); countDownLatch.countDown(); } } }); countDownLatch.await(); MyConfig myConfig = new MyConfig(); myConfig.setKey("anykey"); myConfig.setName("anyName"); ObjectMapper objectMapper=new ObjectMapper(); byte[] bytes = objectMapper.writeValueAsBytes(myConfig); String s = zooKeeper.create("/myconfig", bytes, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); Watcher watcher = new Watcher() { @SneakyThrows @Override public void process(WatchedEvent event) { if (event.getType()== Event.EventType.NodeDataChanged && event.getPath()!=null && event.getPath().equals("/myconfig")){ log.info(" PATH:{} 发生了数据变化" ,event.getPath()); //循环监听 //监听结束后,重新设置 byte[] data = zooKeeper.getData("/myconfig", this, null); MyConfig newConfig = objectMapper.readValue(new String(data), MyConfig.class); log.info("数据发生变化: {}",newConfig); } } }; byte[] data = zooKeeper.getData("/myconfig", watcher, null); MyConfig originalMyConfig = objectMapper.readValue(new String(data), MyConfig.class); log.info("原始数据: {}", originalMyConfig);// TimeUnit.SECONDS.sleep(Integer.MAX_VALUE); }
standalone版本
@Slf4jpublic abstract class StandaloneBase { private static final String CONNECT_STR="192.168.109.200:2181"; private static final int SESSION_TIMEOUT=30 * 1000; private static ZooKeeper zooKeeper =null; private static CountDownLatch countDownLatch = new CountDownLatch(1); private Watcher watcher =new Watcher() { @Override public void process(WatchedEvent event) { if (event.getState() == Event.KeeperState.SyncConnected && event.getType()== Event.EventType.None){ countDownLatch.countDown(); log.info("连接建立"); } } }; @Before public void init(){ try { log.info(" start to connect to zookeeper server: {}",getConnectStr()); zooKeeper=new ZooKeeper(getConnectStr(), getSessionTimeout(), watcher); log.info(" 连接中..."); countDownLatch.await(); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } public static ZooKeeper getZooKeeper() { return zooKeeper; } @After public void test(){ try { TimeUnit.SECONDS.sleep(Integer.MAX_VALUE); } catch (InterruptedException e) { e.printStackTrace(); } } protected String getConnectStr(){ return CONNECT_STR; } protected int getSessionTimeout() { return SESSION_TIMEOUT; }} private String first_node = "/first-node"; @Test public void testCreate() throws KeeperException, InterruptedException { ZooKeeper zooKeeper = getZooKeeper(); String s = zooKeeper.create(first_node, "first".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); log.info("Create:{}",s); }@Test public void testGetData(){ Watcher watcher = new Watcher() { @Override public void process(WatchedEvent event) { if (event.getPath()!=null && event.getPath().equals(first_node) && event.getType()== Event.EventType.NodeDataChanged){ log.info(" PATH: {} 发现变化",first_node); try { byte[] data = getZooKeeper().getData(first_node, this, null); log.info(" data: {}",new String(data)); } catch (KeeperException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } } }; try { byte[] data = getZooKeeper().getData(first_node, watcher, null); // log.info(" data: {}",new String(data)); } catch (KeeperException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } @Test public void asyncTest(){ String userId="xxx"; getZooKeeper().getData("/test", false, (rc, path, ctx, data, stat) -> { Thread thread = Thread.currentThread(); log.info(" Thread Name: {}, rc:{}, path:{}, ctx:{}, data:{}, stat:{}",thread.getName(),rc, path, ctx, data, stat); },"test"); log.info(" over ."); } @Test public void exist() throws Exception{ ZooKeeper zooKeeper = getZooKeeper(); // true表示的是使用Zookeeper中的watch Stat stat = zooKeeper.exists(first_node, true); if(stat != null){ System.out.println("节点存在"+ stat.getNumChildren()); }else{ System.out.println("节点不存在 ...."); } } @Test public void getChildrens() throws Exception{ ZooKeeper zooKeeper = getZooKeeper(); List<String> childrens = zooKeeper.getChildren(first_node, true); for (String children : childrens) { // System.out.println(children); // 获取子节点中的数据 byte[] data = zooKeeper.getData(first_node+"/" + children, false, null); System.out.println(children+":" + new String(data)); } } @Test public void setData() throws Exception{ // -1 不指定版本 自动维护 Stat stat = zooKeeper.setData(first_node+"/a1", "666666".getBytes(), -1); System.out.println(stat); // 指定版本 自动维护//ZooKeeper zooKeeper = getZooKeeper(); //Stat stat = new Stat(); //byte[] data = zooKeeper.getData(first_node, false, stat); //int version = stat.getVersion();//版本号 //zooKeeper.setData(first_node, "third".getBytes(), version); } @Test public void deleteNode() throws Exception{ zooKeeper.delete(first_node,-1); }事件监听处理
@Test public void nodeChildrenChange() throws Exception{ List<String> list = zooKeeper.getChildren("/app1", new Watcher() { @Override public void process(WatchedEvent watchedEvent) { System.out.println("--->"+ watchedEvent.getType()); } }); for (String s : list) { System.out.println(s); } Thread.sleep(Integer.MAX_VALUE); } @Test public void nodeDataChanged() throws Exception{ byte[] data = zooKeeper.getData("/app1/a1", new Watcher() { @Override public void process(WatchedEvent watchedEvent) { System.out.println("--->" + watchedEvent.getType()); } }, null); System.out.println("--->" + new String(data)); Thread.sleep(Integer.MAX_VALUE); }Curator
Curator 是一套由netflix 公司开源的,Java 语言编程的 ZooKeeper 客户端框架,Curator项目
是现在ZooKeeper 客户端中使用最多,对ZooKeeper 版本支持最好的第三方客户端,并推荐使
用,Curator 把我们平时常用的很多 ZooKeeper 服务开发功能做了封装,例如 Leader 选举、
分布式计数器、分布式锁。这就减少了技术人员在使用 ZooKeeper 时的大部分底层细节开发工
作。在会话重新连接、Watch 反复注册、多种异常处理等使用场景中,用原生的 ZooKeeper
处理比较复杂。而在使用 Curator 时,由于其对这些功能都做了高度的封装,使用起来更加简
单,不但减少了开发时间,而且增强了程序的可靠性。
yaml
<dependency> <groupId>org.apache.curatorgroupId> <artifactId>curator-recipesartifactId> <version>5.0.0version> <exclusions> <exclusion> <groupId>org.apache.zookeepergroupId> <artifactId>zookeeperartifactId> exclusion> exclusions>dependency><dependency> <groupId>org.apache.curatorgroupId> <artifactId>curator-x-discoveryartifactId> <version>5.0.0version> <exclusions> <exclusion> <groupId>org.apache.zookeepergroupId> <artifactId>zookeeperartifactId> exclusion> exclusions>dependency><dependency> <groupId>org.apache.zookeepergroupId> <artifactId>zookeeperartifactId> <version>3.5.8version>dependency>父类
@Slf4jpublic abstract class CuratorStandaloneBase { private static final String CONNECT_STR = "192.168.109.200:2181"; private static final int sessionTimeoutMs = 60*1000; private static final int connectionTimeoutMs = 5000; private static CuratorFramework curatorFramework; @Before public void init() { RetryPolicy retryPolicy = new ExponentialBackoffRetry(5000, 30); curatorFramework = CuratorFrameworkFactory.builder().connectString(getConnectStr()) .retryPolicy(retryPolicy) .sessionTimeoutMs(sessionTimeoutMs) .connectionTimeoutMs(connectionTimeoutMs) .canBeReadOnly(true) .build(); curatorFramework.getConnectionStateListenable().addListener((client, newState) -> { if (newState == ConnectionState.CONNECTED) { log.info("连接成功!"); } }); log.info("连接中......"); curatorFramework.start(); } public void createIfNeed(String path) throws Exception { Stat stat = curatorFramework.checkExists().forPath(path); if (stat==null){ String s = curatorFramework.create().forPath(path); log.info("path {} created! ",s); } } public static CuratorFramework getCuratorFramework() { return curatorFramework; } protected String getConnectStr(){ return CONNECT_STR; }}// 递归创建子节点 @Test public void testCreateWithParent() throws Exception { CuratorFramework curatorFramework = getCuratorFramework(); String pathWithParent = "/node-parent/sub-node-1"; String path = curatorFramework.create().creatingParentsIfNeeded().forPath(pathWithParent); log.info("curator create node :{} successfully.", path); } // protection 模式,防止由于异常原因,导致僵尸节点 @Test public void testCreate() throws Exception { CuratorFramework curatorFramework = getCuratorFramework(); String forPath = curatorFramework .create() .withProtection() .withMode(CreateMode.EPHEMERAL_SEQUENTIAL). forPath("/curator-node", "some-data".getBytes()); log.info("curator create node :{} successfully.", forPath); } @Test public void testGetData() throws Exception { CuratorFramework curatorFramework = getCuratorFramework(); byte[] bytes = curatorFramework.getData().forPath("/curator-node"); log.info("get data from node :{} successfully.", new String(bytes)); } @Test public void testSetData() throws Exception { CuratorFramework curatorFramework = getCuratorFramework(); curatorFramework.setData().forPath("/curator-node", "changed!".getBytes()); byte[] bytes = curatorFramework.getData().forPath("/curator-node"); log.info("get data from node /curator-node :{} successfully.", new String(bytes)); } @Test public void testDelete() throws Exception { CuratorFramework curatorFramework = getCuratorFramework(); String pathWithParent = "/node-parent"; curatorFramework.delete().guaranteed().deletingChildrenIfNeeded().forPath(pathWithParent); } @Test public void testListChildren() throws Exception { CuratorFramework curatorFramework = getCuratorFramework(); String pathWithParent = "/discovery/example"; List<String> strings = curatorFramework.getChildren().forPath(pathWithParent); strings.forEach(System.out::println); }//线程池方式 @Test public void testThreadPool() throws Exception { CuratorFramework curatorFramework = getCuratorFramework(); ExecutorService executorService = Executors.newSingleThreadExecutor(); String ZK_NODE="/zk-node"; curatorFramework.getData().inBackground((client, event) -> { log.info(" background: {}", event); },executorService).forPath(ZK_NODE); }Watch机制
ZooKeeper的Watch机制是它的一个重要特性,它允许客户端在ZooKeeper节点发生变化时得到通知。通过Watch机制,客户端可以设置对指定节点的监视,并在节点发生变化(数据更新、节点删除、子节点变化等)时,ZooKeeper会通知相关的客户端。(相当与redis分布式锁中的watchDog机制,是分布式锁中十分重要的机制,用于监听比自己小的节点)
Watch机制的主要特点包括:
一次性触发:一旦Watch被设置在一个节点上,并且该节点发生了监视的事件(例如数据更新),那么Watch就会触发通知。一次触发后,Watch就会失效,客户端需要重新设置Watch以继续监视节点。
轻量级通知:ZooKeeper的Watch机制是轻量级的,因为Watch只是一个通知,不包含实际数据。客户端收到Watch通知后,可以根据需要再次向ZooKeeper请求节点的最新数据。
顺序性:Watch通知是有序的。也就是说,如果多个Watch被设置在一个节点上,当该节点发生变化时,通知的顺序是确定的,保证了客户端可以按照特定的顺序处理通知。
一次性回调:客户端收到Watch通知后,需要进行一次性回调来处理事件。在处理通知的过程中,如果发生了新的变化,之前的Watch不会再次触发。
需要注意的是,Watch机制并不保证强一致性。由于网络延迟或其他因素,Watch通知可能有一定的延迟,客户端可能会收到旧的数据变更通知。因此,客户端在处理Watch通知时,需要谨慎处理,并考虑可能出现的数据不一致情况。
Watch机制是ZooKeeper实现分布式协作的关键机制之一。通过Watch,客户端可以实时获取ZooKeeper节点的变化,从而在分布式系统中做出相应的处理,实现高效的协作和协调。
ZK分布式锁
创建节点,判断顺序号是否是最小的
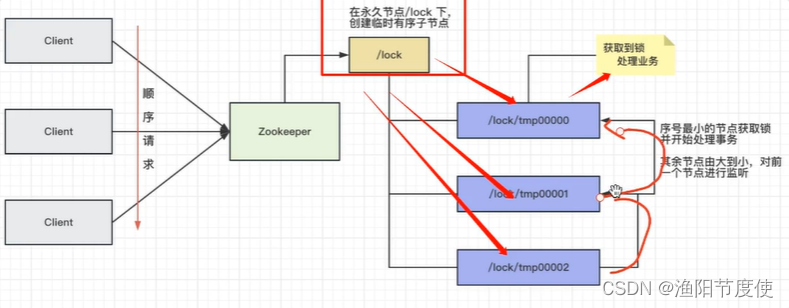
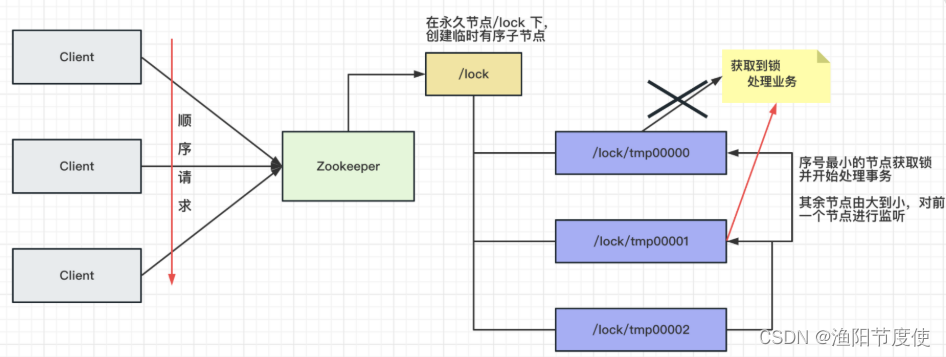
创建永久节点,在普通节点下创建临时顺序节点,节点之间按顺序依次监听(通过watch机制),当拿到锁的节点处理完事务后,释放锁,后一个节点监听到前一个节点释放锁后,立刻申请获得锁,以此类推
过程解析
- 第一部分:客户端在Zookeeper集群创建临时顺序节点
- 第二部分:判断节点是否是当前最小的节点,如果是,获取锁,反之,监听前一个节点
原生方式实现Zookeeper的分布式锁
public class DistributedLock { private String connectString = "192.168.58.100:2181"; private ZooKeeper client; private CountDownLatch countDownLatch = new CountDownLatch(1); private CountDownLatch waitLatch = new CountDownLatch(1); //当前节点 private String currentNode; //要等待的节点 private String waitPath; //1.连接Zookeeper public DistributedLock() throws Exception { client = new ZooKeeper(connectString, 300000, new Watcher() { @Override public void process(WatchedEvent watchedEvent) { //连接上zk 释放 if(watchedEvent.getState() == Event.KeeperState.SyncConnected){ countDownLatch.countDown(); } // waitLatch 需要释放,节点被删除,并且是前一个节点 if(watchedEvent.getType() == Event.EventType.NodeDeleted && watchedEvent.getPath().equals(waitPath)){ waitLatch.countDown(); } } }); //zk 连接成功,再往下走 countDownLatch.await(); //2.判断节点是否存在 Stat stat = client.exists("/locks", false); if(stat == null){ //创建根节点 client.create("/locks","locks".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); } } //3.加锁 public void zkLock() throws KeeperException, InterruptedException { //创建临时顺序节点 currentNode = client.create("/locks/" + "seq-" ,null,ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL); //判断创建的节点是否是最小序号节点,如果是 就获取锁,不是监听前一个节点 List<String> children = client.getChildren("/locks", false); //如果集合中只有一个元素,可以直接获取锁 if(children.size() == 1){ return; }else{ //先排序 Collections.sort(children); //获取节点名称 String nodeName = currentNode.substring("/locks/".length()); //获取节点名称 在集合的位置 int index = children.indexOf(nodeName); if(index == -1){ System.out.println("数据异常"); }else if(index == 0){ return; }else{ //需要监听前一个节点的变化 waitPath = "/locks/" + children.get(index - 1); client.getData(waitPath,true,null); //等待监听执行 waitLatch.await(); return; } } } //解锁 public void unZkLock() throws KeeperException, InterruptedException { //删除节点 client.delete(currentNode,-1); }}Nginx代理转发

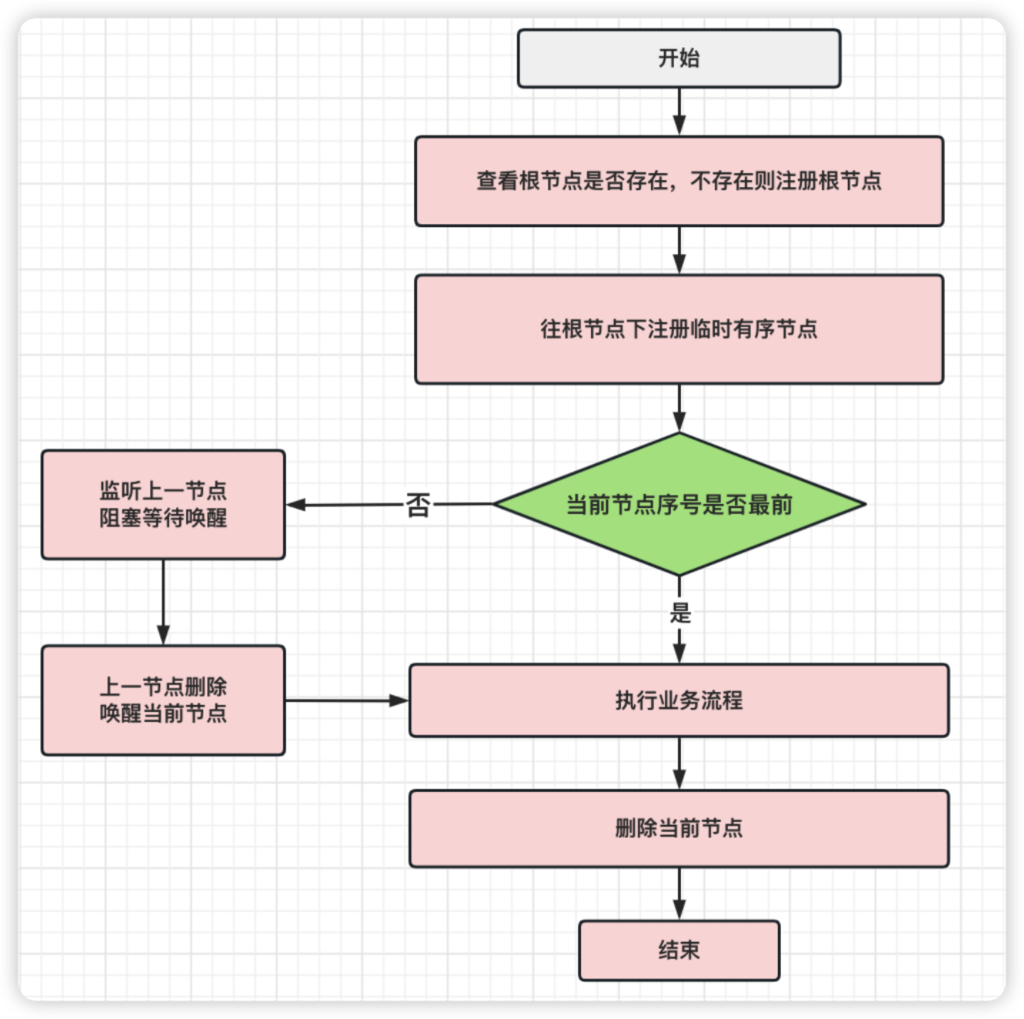
Curator框架实现分布式锁
实现思路
InterProcessMutex介绍
Apache Curator 内置了分布式锁的实现: InterProcessMutex。
- InterProcessMutex有两个构造方法
public InterProcessMutex(CuratorFramework client, String path){ this(client, path, new StandardLockInternalsDriver());}public InterProcessMutex(CuratorFramework client, String path, LockInternalsDriver driver){ this(client, path, LOCK_NAME, 1, driver);}- 参数说明如下
| 参数 | 说明 |
|---|---|
| client | curator中zk客户端对象 |
| path | 抢锁路径,同一个锁path需一致 |
| driver | 可自定义lock驱动实现分布式锁 |
- 主要方法
//获取锁,若失败则阻塞等待直到成功,支持重入public void acquire() throws Exception //超时获取锁,超时失败public boolean acquire(long time, TimeUnit unit) throws Exception //释放锁public void release() throws Exception- 注意点,调用acquire()方法后需相应调用release()来释放锁
代码实现
配置类
@Configurationpublic class CuratorCfg { //Curator初始化 @Bean(initMethod = "start") public CuratorFramework curatorFramework(){ RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); CuratorFramework client = CuratorFrameworkFactory.newClient("192.168.40.240:2181", retryPolicy);//CuratorFramework build = CuratorFrameworkFactory.builder()// .connectString("192.168.40.240:2181")// .sessionTimeoutMs(60*1000)// .connectionTimeoutMs(60*1000)// .retryPolicy(new ExponentialBackoffRetry(1000,3))// .build(); return client; }}业务代码
@RestControllerpublic class TestController { @Autowired private OrderService orderService; @Value("${server.port}") private String port; public static final String product = "/product_"; @Autowired CuratorFramework curatorFramework; @PostMapping("/stock/deduct") public Object reduceStock(Integer id) throws Exception { InterProcessMutex interProcessMutex = new InterProcessMutex(curatorFramework, product + id);//互斥锁 try { // ... interProcessMutex.acquire();//加锁 orderService.reduceStock(id); } catch (Exception e) { if (e instanceof RuntimeException) { throw e; } }finally { interProcessMutex.release();//解锁 } return "ok:" + port; }}全局异常处理类
@ControllerAdvicepublic class ExceptionHandlerController { @ExceptionHandler @ResponseStatus(value = HttpStatus.BAD_REQUEST) @ResponseBody public Object exceptionHandler(RuntimeException e){ Map<String,Object> result=new HashMap<>( ); result.put( "status","error" ); result.put( "message",e.getMessage() ); return result; }}ZK注册中心
项目较小的话会考虑使用ZK做注册中心,原理:使用临时节点
spring.application.name=product-center1#zookeeper 连接地址spring.cloud.zookeeper.connect-string=192.168.40.240:2181#将本服务注册到zookeeper,如果不希望直接被发现可以配置为false,默认为truespring.cloud.zookeeper.discovery.register=truespring.cloud.zookeeper.session-timeout=30000来源地址:https://blog.csdn.net/Forbidden_City/article/details/132010388













