

- 一、Hadoop概述
- 二、HDFS详解
- 1)HDFS概述
- HDFS的设计特点
- 2)HDFS组成
- 1、Client
- 2、NameNode(NN)
- 3、DataNode(DN)
- 4、Secondary NameNode(2NN)
- 3)HDFS具体工作原理
- 1、两个核心的数据结构: Fslmage和EditLog
- 2、工作流程
- 3、HDFS读文件流程
- 4、HDFS文件写入流程
- 1)HDFS概述
- 三、Yarn详解
- 1)Yarn概述
- 2)YARN架构组件
- 1、ResourceManager(RM)
- 2、ApplicationMaster(AM)
- 3、NodeManager(NM)
- 4、Container
- 3)YARN运行流程
- 4)YARN三种资源调度器
- 1、FIFO调度器(FIFO Scheduler)
- 2、容量调度器(Capacity Scheduler)
- 3、资源调度器- Fair
- 四、MapReduce详解
- 1)MapReduce概述
- 2)MapReduce运行流程
- 1、作业的提交
- 2、作业的初始化
- 3、作业任务的分配
- 4、作业任务的执行
- 5、作业任务的状态更新
- 6、作业的完成
- 3)MapReduce中的shuffle过程
- 1、map端
- 2、reduce端
- 五、安装Hadoop(HDFS+YARN)
- 1)环境准备
- 2)下载最新的Hadoop安装包
- 3)进行服务器及Hadoop的初始化配置
- 4)开始安装Hadoop
- 1、解压上面我编译好的安装包
- 2、安装包目录说明
- 3、修改配置文件
- 4、分发同步hadoop安装包到另外几台机器
- 5、将hadoop添加到环境变量(所有节点)
- 6、Hadoop集群启动(hadoop-node1上执行)
- 1)(首次启动)格式化namenode(只能执行一次)
- 2)手动逐个进程启停
- 3)通过shell脚本一键启动
- 4)通过web页面访问
- 六、Hadoop实战操作
- 1)HDFS实战操作

- 2)MapReduce+YARN实战操作
- 3)Yarn的常用命令
一、Hadoop概述
Hadoop是Apache软件基金会下一个开源分布式计算平台,以HDFS(Hadoop Distributed File System)、MapReduce(Hadoop2.0加入了YARN,Yarn是资源调度框架,能够细粒度的管理和调度任务,还能够支持其他的计算框架,比如spark)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。hdfs的高容错性、高伸缩性、高效性等优点让用户可以将Hadoop部署在低廉的硬件上,形成分布式系统。目前最新版本已经是3.x了,官方文档。也可以参考我之前的文章:Hadoop生态系统介绍
二、HDFS详解
1)HDFS概述
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。HDFS 源于 Google 在2003年10月份发表的GFS(Google File System) 论文。 它其实就是 GFS(Google File System) 的一个克隆版本。

HDFS的设计特点
之所以选择 HDFS 存储数据,因为 HDFS 具有以下优点:
- 高容错性:数据自动保存多个副本。它通过增加副本的形式,提高容错性。某一个副本丢失以后,它可以自动恢复,这是由 HDFS 内部机制实现的,我们不必关心。
- 适合批处理:它是通过移动计算而不是移动数据。它会把数据位置暴露给计算框架。
- 适合大数据处理:处理数据达到 GB、TB、甚至PB级别的数据。能够处理百万规模以上的文件数量,数量相当之大。能够处理10K节点的规模。
- 流式文件访问:一次写入,多次读取。文件一旦写入不能修改,只能追加。它能保证数据的一致性。
- 可构建在廉价机器上:它通过多副本机制,提高可靠性。它提供了容错和恢复机制。比如某一个副本丢失,可以通过其它副本来恢复。
当然 HDFS 也有它的劣势,并不适合所有的场合:
-
低延时数据访问:它适合高吞吐率的场景,就是在某一时间内写入大量的数据。但是它在低延时的情况下是不行的,比如毫秒级以内读取数据,这样它是很难做到的。
-
小文件存储:存储大量小文件(这里的小文件是指小于HDFS系统的Block大小的文件(Hadoop 3.x默认128M)的话,它会占用 NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。小文件存储的寻道时间会超过读取时间,它违反了HDFS的设计目标。
-
并发写入、文件随机修改:一个文件只能有一个写,不允许多个线程同时写。仅支持数据 append(追加),不支持文件的随机修改。
2)HDFS组成

HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。下面我们分别介绍这四个组成部分 :
1、Client
Client就是客户端
- 文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的- Block,然后进行存储。
- 与 NameNode 交互,获取文件的位置信息。
- 与 DataNode 交互,读取或者写入数据。
- Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
- Client 可以通过一些命令来访问 HDFS。
2、NameNode(NN)
NameNode就是 master,它是一个主管、管理者。
3、DataNode(DN)
DataNode就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
- 存储实际的数据块。
- 执行数据块的读/写操作。
4、Secondary NameNode(2NN)
Secondary NameNode并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
- Secondary NameNode仅仅是NameNode的一个工具,这个工具帮助NameNode管理元数据信息。
- 定期合并 fsimage和fsedits,并推送给NameNode。
- 在紧急情况下,可辅助恢复 NameNode。
3)HDFS具体工作原理

1、两个核心的数据结构: Fslmage和EditLog
- FsImage负责维护文件系统树和树中所有文件和文件夹的元数据。
———维护文件结构和文件元信息的镜像 - EditLog操作日志文件中记录了所有针对文件的创建,删除,重命名操作。
———记录对文件的操作
PS:
1.NN的元数据为了读写速度块是写在内存里的,FsImage只是它的一个镜像保存文件
2.当每输入一个增删改操作,EditLog都会单独生成一个文件,最后EL会生成多个文件
3.2NN不是NN的备份(但可以做备份),它的主要工作是帮助NN合并edits log,减少NN启动时间。
4.拓扑距离:根据节点网络构成的树形结构计算最短路径
5.机架感知:根据拓扑距离得到的节点摆放位置
2、工作流程
- 第一步: 当客户端对元数据进行增删改请求时,由于hadoop安全性要求比较高,它会先将操作写入到editlog文件里,先持久化。
- 第二步: 然后将具体增删改操作,将FSimage和edit写入内存里进行具体的操作,先写文件,即使宕机了也可以恢复数据,不然先内存数据就会消失,此时2NN发现时间到了,或者edit数据满了或者刚开机时,就会请求执行辅助操作,NN收到后将edit瞬间复制一份,这个时候客户端传过来的数据继续写到edit里。
- 第三步:我们把复制的edit和fsimage拷贝到2NN(SecondaryNameNode)里,操作写在2NN的内存里合并,合并后将文件返回给NN做为新的Fsimage。所以一旦NN宕机2NN比NN差一个edit部分,无法完全恢复原先状态,只能说辅助恢复。
3、HDFS读文件流程

【第一步】Client调用FileSystem.open()方法
- FileSystem通过RPC与NN通信,NN返回该文件的部分或全部block列表(含有block拷贝的DN地址)。
- 选取举栗客户端最近的DN建立连接,读取block,返回FSDataInputStream。
【第二步】Client调用输入流的read()方法
- 当读到block结尾时,FSDataInputStream关闭与当前DN的连接,并未读取下一个block寻找最近DN。
- 读取完一个block都会进行checksum验证,如果读取DN时出现错误,客户端会通知NN,然后再从下一个拥有该block拷贝的DN继续读。
- 如果block列表读完后,文件还未结束,FileSystem会继续从NN获取下一批block列表。
【第三步】关闭FSDataInputStream
4、HDFS文件写入流程

【第一步】Client调用FileSystem的create()方法
- FileSystem向NN发出请求,在NN的namespace里面创建一个新的文件,但是并不关联任何块。
- NN检查文件是否已经存在、操作权限。如果检查通过,NN记录新文件信息,并在某一个DN上创建数据块。
- 返回FSDataOutputStream,将Client引导至该数据块执行写入操作。
【第二步】Client调用输出流的write()方法
- HDFS默认将每个数据块放置3份。FSDataOutputStream将数据首先写到第一节点,第一节点将数据包传送并写入第二节点,第二节点 --> 第三节点。
【第三步】Client调用流的close()方法
- flush缓冲区的数据包,block完成复制份数后,NN返回成功消息。
三、Yarn详解
1)Yarn概述
Apache Yarn(Yet Another Resource Negotiator的缩写)是hadoop集群资源管理器系统,Yarn从hadoop 2引入,最初是为了改善MapReduce的实现,但是它具有通用性,同样执行其他分布式计算模式。
Yarn特点:
- 支持非mapreduce应用的需求
- 可扩展性
- 提高资源是用率
- 用户敏捷性
- 可以通过搭建为高可用
2)YARN架构组件
Yarn从整体上还是属于master/slave模型,主要依赖于三个组件来实现功能,第一个就是ResourceManager,是集群资源的仲裁者,它包括两部分:一个是可插拔式的调度Scheduler,一个是ApplicationManager,用于管理集群中的用户作业。第二个是每个节点上的NodeManager,管理该节点上的用户作业和工作流,也会不断发送自己Container使用情况给ResourceManager。第三个组件是ApplicationMaster,用户作业生命周期的管理者它的主要功能就是向ResourceManager(全局的)申请计算资源(Containers)并且和NodeManager交互来执行和监控具体的task。架构图如下:

1、ResourceManager(RM)
RM是一个全局的资源管理器,管理整个集群的计算资源,并将这些资源分配给应用程序。包括:
- 与客户端交互,处理来自客户端的请求
- 启动和管理ApplicationMaster,并在它运行失败时重新启动它
- 管理NodeManager ,接收来自NodeManager 的资源汇报信息,并向NodeManager下达管理指令
- 资源管理与调度,接收来自ApplicationMaster 的资源申请请求,并为之分配资源
RM关键配置参数:
- 最小容器内存: yarn.scheduler.minimum-allocation-mb
- 容器内存增量: yarn.scheduler.increment-allocation-mb
- 最大容器内存: yarn.scheduler.maximum-allocation-mb
- 最小容器虚拟 CPU 内核数量: yarn.scheduler.minimum-allocation-mb
- 容器虚拟 CPU 内核增量: yarn.scheduler.increment-allocation-vcores
- 最大容器虚拟 CPU 内核数量: yarn.scheduler.maximum-allocation-mb
- ResourceManager Web 应用程序 HTTP 端口: yarn.resourcemanager.webapp.address
2、ApplicationMaster(AM)
应用程序级别的,管理运行在YARN上的应用程序。包括:
- 用户提交的每个应用程序均包含一个AM,它可以运行在RM以外的机器上。
- 负责与RM调度器协商以获取资源(用Container表示)
- 将得到的资源进一步分配给内部的任务(资源的二次分配)
- 与NM通信以启动/停止任务。
- 监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务
AM关键配置参数:
- ApplicationMaster 最大尝试次数: yarn.resourcemanager.am.max-attempts
- ApplicationMaster 监控过期: yarn.am.liveness-monitor.expiry-interval-ms
3、NodeManager(NM)
YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点。包括:
- 启动和监视节点上的计算容器(Container)
- 以心跳的形式向RM汇报本节点上的资源使用情况和各个Container的运行状态(CPU和内存等资源)
- 接收并处理来自AM的Container启动/停止等各种请求
NM关键配置参数:
- 节点内存: yarn.nodemanager.resource.memory-mb
- 节点虚拟 CPU 内核: yarn.nodemanager.resource.cpu-vcores
- NodeManager Web 应用程序 HTTP 端口: yarn.nodemanager.webapp.address
4、Container
Container是YARN中资源的抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。Container由AM向RM申请的,由RM中的资源调度器异步分配给AM。Container的运行是由AM向资源所在的NM发起。
一个应用程序所需的Container分为两大类:
- 运行AM的Container:这是由RM(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的AM所需的资源;
- 运行各类任务的Container:这是由AM向RM申请的,并由AM与NM通信以启动之。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即AM可能与它管理的任务运行在一个节点上。
3)YARN运行流程
Application在Yarn中的执行过程如下图所示:

-
客户端程序向ResourceManager提交应用并请求一个ApplicationMaster实例,ResourceManager在应答中给出一个applicationID以及有助于客户端请求资源的资源容量信息。
-
ResourceManager找到可以运行一个Container的NodeManager,并在这个Container中启动ApplicationMaster实例
- Application Submission Context发出响应,其中包含有:ApplicationID,用户名,队列以及其他启动ApplicationMaster的信息,Container Launch Context(CLC)也会发给ResourceManager,CLC提供了资源的需求,作业文件,安全令牌以及在节点启动ApplicationMaster所需要的其他信息。
- 当ResourceManager接收到客户端提交的上下文,就会给ApplicationMaster调度一个可用的container(通常称为container0)。然后ResourceManager就会联系NodeManager启动ApplicationMaster,并建立ApplicationMaster的RPC端口和用于跟踪的URL,用来监控应用程序的状态。
-
ApplicationMaster向ResourceManager进行注册,注册之后客户端就可以查询ResourceManager获得自己ApplicationMaster的详细信息,以后就可以和自己的ApplicationMaster直接交互了。在注册响应中,ResourceManager会发送关于集群最大和最小容量信息,
-
在平常的操作过程中,ApplicationMaster根据resource-request协议向ResourceManager发送resource-request请求,ResourceManager会根据调度策略尽可能最优的为ApplicationMaster分配container资源,作为资源请求的应答发个ApplicationMaster
-
当Container被成功分配之后,ApplicationMaster通过向NodeManager发送container-launch-specification信息来启动Container, container-launch-specification信息包含了能够让Container和ApplicationMaster交流所需要的资料,一旦container启动成功之后,ApplicationMaster就可以检查他们的状态,Resourcemanager不在参与程序的执行,只处理调度和监控其他资源,Resourcemanager可以命令NodeManager杀死container,
-
应用程序的代码在启动的Container中运行,并把运行的进度、状态等信息通过application-specific协议发送给ApplicationMaster,随着作业的执行,ApplicationMaster将心跳和进度信息发给ResourceManager,在这些心跳信息中,ApplicationMaster还可以请求和释放一些container。
-
在应用程序运行期间,提交应用的客户端主动和ApplicationMaster交流获得应用的运行状态、进度更新等信息,交流的协议也是application-specific协议
-
一但应用程序执行完成并且所有相关工作也已经完成,ApplicationMaster向ResourceManager取消注册然后关闭,用到所有的Container也归还给系统,当container被杀死或者回收,Resourcemanager都会通知NodeManager聚合日志并清理container专用的文件。
4)YARN三种资源调度器
1、FIFO调度器(FIFO Scheduler)
FIFO调度器的优点是简单易懂不需要任何配置,但是不适合共享集群。大型应用会占用集群中的所有资源,所以每个应用必须等待直到轮到自己运行。在一个共享集群中,更适合使用容量调度器或公平调度器。这两种调度器都允许长时间运行的作业能及时完成,同时也允许正在进行较小临时查询的用户能够在合理时间内得到返回结果。

2、容量调度器(Capacity Scheduler)
容量调度器允许多个组织共享一个Hadoop集群,每个组织可以分配到全部集群资源的一部分。每个组织被配置一个专门的队列,每个队列被配置为可以使用一定的集群资源。队列可以进一步按层次划分,这样每个组织内的不同用户能够共享该组织队列所分配的资源。在一个队列内,使用FIFO调度策略对应用进行调度。
- 单个作业使用的资源不会超过其队列容量。然而如果队列中有多个作业,并且队列资源不够了呢?这时如果仍有可用的空闲资源那么容量调度器可能会将空余的资源分配给队列中的作业,哪怕这会超出队列容量。这被称为弹性队列(queue elasticity)。

3、资源调度器- Fair
公平调度是一种对于全局资源,对于所有应用作业来说,都均匀分配的资源分配方法。默认情况,公平调度器FairScheduler基于内存来安排公平调度策略。也可以配置为同时基于内存和CPU来进行调度(Dominant Resource Fairness)。在一个队列内,可以使用FIFO、FAIR、DRF调度策略对应用进行调度。FairScheduler允许保障性的分配最小资源到队列。
- 【注意】在下图 Fair 调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的 Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终效果就是 Fair 调度器即得到了高的资源利用率又能保证小任务及时完成。

四、MapReduce详解
1)MapReduce概述
MapReduce是一种编程模型(没有集群的概念,会把任务提交到yarn集群上跑),用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。(MapReduce在企业里几乎不再使用了,稍微了解即可)
2)MapReduce运行流程
作业的运行过程主要包括如下几个步骤:
作业的提交
2、作业的初始化
3、作业任务的分配
4、作业任务的执行
5、作业执行状态更新
6、作业完成
具体作业执行过程的流程图如下图所示:

1、作业的提交
在MR的代码中调用waitForCompletion()方法,里面封装了Job.submit()方法,而Job.submit()方法里面会创建一个JobSubmmiter对象。当我们在waitForCompletion(true)时,则waitForCompletion方法会每秒轮询作业的执行进度,如果发现与上次查询到的状态有差别,则将详情打印到控制台。如果作业执行成功,就显示作业计数器,否则将导致作业失败的记录输出到控制台。
其中JobSubmmiter实现的大概过程如下:
- 向资源管理器resourcemanager提交申请,用于一个mapreduce作业ID,如图步骤2所示
- 检查作业的输出配置,判断目录是否已经存在等信息
- 计算作业的输入分片的大小
- 将运行作业的jar,配置文件,输入分片的计算资源复制到一个以作业ID命名的hdfs临时目录下,作业jar的复本比较多,默认为10个(通过参数mapreduce.client.submit.file.replication控制),
- 通过资源管理器的submitApplication方法提交作业
2、作业的初始化
-
当资源管理器通过方法submitApplication方法被调用后,便将请求传给了yarn的调度器,然后调度器在一个节点管理器上分配一个容器(container0)用来启动application master(主类是MRAppMaster)进程。该进程一旦启动就会向resourcemanager注册并报告自己的信息,application master并且可以监控map和reduce的运行状态。因此application master对作业的初始化是通过创建多个薄记对象以保持对作业进度的跟踪。
-
application master接收作业提交时的hdfs临时共享目录中的资源文件,jar,分片信息,配置信息等。并对每一个分片创建一个map对象,以及通过mapreduce.job.reduces参数(作业通过setNumReduceTasks()方法设定)确定reduce的数量。
-
application master会判断是否使用uber(作业与application master在同一个jvm运行,也就是maptask和reducetask运行在同一个节点上)模式运行作业,uber模式运行条件:map数量小于10个,1个reduce,且输入数据小于一个hdfs块
可以通过参数:
mapreduce.job.ubertask.enable #是否启用uber模式
mapreduce.job.ubertask.maxmaps #ubertask的最大map数
mapreduce.job.ubertask.maxreduces #ubertask的最大reduce数
mapreduce.job.ubertask.maxbytes #ubertask最大作业大小
- application master调用setupJob方法设置OutputCommiter,FileOutputCommiter为默认值,表示建立做的最终输出目录和任务输出的临时工作空间
3、作业任务的分配
-
在application master判断作业不符合uber模式的情况下,那么application master则会向资源管理器为map和reduce任务申请资源容器。
-
首先就是为map任务发出资源申请请求,直到有5%的map任务完成时,才会为reduce任务所需资源申请发出请求。
-
在任务的分配过程中,reduce任务可以在任何的datanode节点运行,但是map任务执行的时候需要考虑到数据本地化的机制,在给任务指定资源的时候每个map和reduce默认为1G内存,可以通过如下参数配置:
mapreduce.map.memory.mb
mapreduce.map.cpu.vcores
mapreduce.reduce.memory.mb
mapreduce.reduce.cpu.vcores
4、作业任务的执行
application master提交申请后,资源管理器为其按需分配资源,这时,application master就与节点管理器通信来启动容器。该任务由主类YarnChild的一个java应用程序执行。在运行任务之前,首先将所需的资源进行本地化,包括作业的配置,jar文件等。接下来就是运行map和reduce任务。YarnChild在单独的JVM中运行。
5、作业任务的状态更新
每个作业和它的每个任务都有一个状态:作业或者任务的状态(运行中,成功,失败等),map和reduce的进度,作业计数器的值,状态消息或描述当作业处于正在运行中的时候,客户端可以直接与application master通信,每秒(可以通过参数mapreduce.client.progressmonitor.pollinterval设置)轮询作业的执行状态,进度等信息。
6、作业的完成
- 当application master收到最后一个任务已完成的通知,便把作业的状态设置为成功。
- 在job轮询作业状态时,知道任务已经完成,然后打印消息告知用户,并从waitForCompletion()方法返回。
- 当作业完成时,application master和container会清理中间数据结果等临时问题。OutputCommiter的commitJob()方法被调用,作业信息由作业历史服务存档,以便用户日后查询。
3)MapReduce中的shuffle过程
mapreduce确保每个reduce的输入都是按照键值排序的,系统执行排序,将map的输入作为reduce的输入过程称之为shuffle过程。shuffle也是我们优化的重点部分。shuffle流程图如下图所示:

1、map端
-
在生成map之前,会计算文件分片的大小
-
然后会根据分片的大小计算map的个数,对每一个分片都会产生一个map作业,或者是一个文件(小于分片大小*1.1)生成一个map作业,然后通过自定的map方法进行自定义的逻辑计算,计算完毕后会写到本地磁盘。
-
在这里不是直接写入磁盘,为了保证IO效率,采用了先写入内存的环形缓冲区,并做一次预排序(快速排序)。缓冲区的大小默认为100MB(可通过修改配置项mpareduce.task.io.sort.mb进行修改),当写入内存缓冲区的大小到达一定比例时,默认为80%(可通过mapreduce.map.sort.spill.percent配置项修改),将启动一个溢写线程将内存缓冲区的内容溢写到磁盘(spill to disk),这个溢写线程是独立的,不影响map向缓冲区写结果的线程,在溢写到磁盘的过程中,map继续输入到缓冲中,如果期间缓冲区被填满,则map写会被阻塞到溢写磁盘过程完成。溢写是通过轮询的方式将缓冲区中的内存写入到本地mapreduce.cluster.local.dir目录下。在溢写到磁盘之前,我们会知道reduce的数量,然后会根据reduce的数量划分分区,默认根据hashpartition对溢写的数据写入到相对应的分区。在每个分区中,后台线程会根据key进行排序,所以溢写到磁盘的文件是分区且排序的。如果有combiner函数,它在排序后的输出运行,使得map输出更紧凑。减少写到磁盘的数据和传输给reduce的数据。
-
每次环形换冲区的内存达到阈值时,就会溢写到一个新的文件,因此当一个map溢写完之后,本地会存在多个分区切排序的文件。在map完成之前会把这些文件合并成一个分区且排序(归并排序)的文件,可以通过参数mapreduce.task.io.sort.factor控制每次可以合并多少个文件。
-
在map溢写磁盘的过程中,对数据进行压缩可以提交速度的传输,减少磁盘io,减少存储。默认情况下不压缩,使用参数mapreduce.map.output.compress控制,压缩算法使用mapreduce.map.output.compress.codec参数控制。
-
2、reduce端
- map任务完成后,监控作业状态的application master便知道map的执行情况,并启动reduce任务,application master并且知道map输出和主机之间的对应映射关系,reduce轮询application master便知道主机所要复制的数据。
- 一个Map任务的输出,可能被多个Reduce任务抓取。每个Reduce任务可能需要多个Map任务的输出作为其特殊的输入文件,而每个Map任务的完成时间可能不同,当有一个Map任务完成时,Reduce任务就开始运行。Reduce任务根据分区号在多个Map输出中抓取(fetch)对应分区的数据,这个过程也就是Shuffle的copy过程。。reduce有少量的复制线程,因此能够并行的复制map的输出,默认为5个线程。可以通过参数mapreduce.reduce.shuffle.parallelcopies控制。
- 这个复制过程和map写入磁盘过程类似,也有阀值和内存大小,阀值一样可以在配置文件里配置,而内存大小是直接使用reduce的tasktracker的内存大小,复制时候reduce还会进行排序操作和合并文件操作。
- 如果map输出很小,则会被复制到Reducer所在节点的内存缓冲区,缓冲区的大小可以通过mapred-site.xml文件中的mapreduce.reduce.shuffle.input.buffer.percent指定。一旦Reducer所在节点的内存缓冲区达到阀值,或者缓冲区中的文件数达到阀值,则合并溢写到磁盘。
- 如果map输出较大,则直接被复制到Reducer所在节点的磁盘中。随着Reducer所在节点的磁盘中溢写文件增多,后台线程会将它们合并为更大且有序的文件。当完成复制map输出,进入sort阶段。这个阶段通过归并排序逐步将多个map输出小文件合并成大文件。最后几个通过归并合并成的大文件作为reduce的输出
五、安装Hadoop(HDFS+YARN)
1)环境准备
这里准备三台VM虚拟机
| OS | hostname | ip | 运行角色 |
|---|---|---|---|
| Centos8.x | hadoop-node1 | 192.168.0.113 | namenode,datanode ,resourcemanager,nodemanager |
| Centos8.x | hadoop-node2 | 192.168.0.114 | secondarynamedata,datanode,nodemanager |
| Centos8.x | hadoop-node3 | 192.168.0.115 | datanode,nodemanager |
2)下载最新的Hadoop安装包
下载地址:https://dlcdn.apache.org/hadoop/common/


这里下载源码包安装,默认的编译好的文件不支持snappy压缩,因此我们需要自己重新编译。
$ mkdir -p /opt/bigdata/hadoop && cd /opt/bigdata/hadoop
$ wget https://dlcdn.apache.org/hadoop/common/stable/hadoop-3.3.1-src.tar.gz
# 解压
$ tar -zvxf hadoop-3.3.1-src.tar.gz
为什么需要重新编译Hadoop源码?
匹配不同操作系统本地库环境,Hadoop某些操作比如压缩,IO需要调用系统本地库(.so|.dll)
重构源码
源码包目录下有个 BUILDING.txt,因为我这里的操作系统是Centos8,所以选择Centos8的操作步骤,小伙伴们找到自己对应系统的操作步骤执行即可。
$ grep -n -A40 "Building on CentOS 8" BUILDING.txt

Building on CentOS 8
----------------------------------------------------------------------------------
* Install development tools such as GCC, autotools, OpenJDK and Maven.
$ sudo dnf group install --with-optional "Development Tools"
$ sudo dnf install java-1.8.0-openjdk-devel maven
* Install Protocol Buffers v3.7.1.
$ git clone https://github.com/protocolbuffers/protobuf
$ cd protobuf
$ git checkout v3.7.1
$ autoreconf -i
$ ./configure --prefix=/usr/local
$ make
$ sudo make install
$ cd ..
* Install libraries provided by CentOS 8.
$ sudo dnf install libtirpc-devel zlib-devel lz4-devel bzip2-devel openssl-devel cyrus-sasl-devel libpmem-devel
* Install optional dependencies (snappy-devel).
$ sudo dnf --enablerepo=PowerTools snappy-devel
* Install optional dependencies (libzstd-devel).
$ sudo dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
$ sudo dnf --enablerepo=epel install libzstd-devel
* Install optional dependencies (isa-l).
$ sudo dnf --enablerepo=PowerTools install nasm
$ git clone https://github.com/intel/isa-l
$ cd isa-l/
$ ./autogen.sh
$ ./configure
$ make
$ sudo make install
----------------------------------------------------------------------------------
将进入Hadoop源码路径,执行maven命令进行Hadoop编译
$ cd /opt/bigdata/hadoop/hadoop-3.3.1-src
# 编译
$ mvn package -Pdist,native,docs -DskipTests -Dtar
【问题】Failed to execute goal org.apache.maven.plugins:maven-enforcer-plugin:3.0.0-M1:enforce
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 19:49 min
[INFO] Finished at: 2021-12-14T09:36:29+08:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-enforcer-plugin:3.0.0-M1:enforce (enforce-banned-dependencies) on project hadoop-client-check-test-invariants: Some Enforcer rules have failed. Look above for specific messages explaining why the rule failed. -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn-rf :hadoop-client-check-test-invariants
【解决】
- 方案一:跳过enforcer的强制约束,在构建的命令加上跳过的指令,如:-Denforcer.skip=true
- 方案二:设置规则校验失败不影响构建流程,在构建的命令上加指令,如: -Denforcer.fail=false
具体原因目前还不明确,先使用上面两个方案中的方案一跳过,有兴趣的小伙伴,可以打开DEBUG模式(-X)查看具体报错
$ mvn package -Pdist,native,docs,src -DskipTests -Dtar -Denforcer.skip=true
所以编译命令
# 当然还有其它选项
$ grep -n -A1 "$ mvn package" BUILDING.txt

$ mvn package -Pdist -DskipTests -Dtar -Dmaven.javadoc.skip=true
$ mvn package -Pdist,native,docs -DskipTests -Dtar
$ mvn package -Psrc -DskipTests
$ mvn package -Pdist,native,docs,src -DskipTests -Dtar
$ mvn package -Pdist,native -DskipTests -Dmaven.javadoc.skip
-Dopenssl.prefix=/usr/local/opt/openssl

至此~Hadoop源码编译完成,
编译后的文件位于源码路径下 hadoop-dist/target/

将编译好的二进制包copy出来
$ cp hadoop-dist/target/hadoop-3.3.1.tar.gz /opt/bigdata/hadoop/
$ cd /opt/bigdata/hadoop/
$ ll

这里也把编译好的包放在百度云上,如果小伙伴不想自己编译,可以直接用我这里的:
链接:https://pan.baidu.com/s/1hmdHY20zSLGyKw1OAVCg7Q
提取码:8888
3)进行服务器及Hadoop的初始化配置
1、修改主机名
# 192.168.0.113机器上执行
$ hostnamectl set-hostname hadoop-node1
# 192.168.0.114机器上执行
$ hostnamectl set-hostname hadoop-node2
# 192.168.0.115机器上执行
$ hostnamectl set-hostname hadoop-node3
2、修改主机名和IP的映射关系(所有节点都执行)
$ echo "192.168.0.113 hadoop-node1" >> /etc/hosts
$ echo "192.168.0.114 hadoop-node2" >> /etc/hosts
$ echo "192.168.0.115 hadoop-node3" >> /etc/hosts
3、关闭防火墙和selinux(所有节点都执行)
$ systemctl stop firewalld
$ systemctl disable firewalld
# 临时关闭(不用重启机器):
$ setenforce 0 ##设置SELinux 成为permissive模式
# 永久关闭修改/etc/selinux/config 文件
将SELINUX=enforcing改为SELINUX=disabled
4、时间同步(所有节点都执行)
$ dnf install chrony -y
$ systemctl start chronyd
$ systemctl enable chronyd
/etc/chrony.conf配置文件内容
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#pool 2.centos.pool.ntp.org iburst (这一行注释掉,增加以下两行)
server ntp.aliyun.com iburst
server cn.ntp.org.cn iburst
重新加载配置并测试
$ systemctl restart chronyd.service
$ chronyc sources -v
5、配置ssh免密(在hadoop-node1上执行)
# 1、在hadoop-node1上执行如下命令生成公私密钥:
$ ssh-keygen -t rsa -P "" -f ~/.ssh/id_dsa
# 2、然后将master公钥id_dsa复制到hadoop-node1|hadoop-node2|hadoop-node3进行公钥认证。
$ ssh-copy-id -i /root/.ssh/id_dsa.pub hadoop-node1
$ ssh-copy-id -i /root/.ssh/id_dsa.pub hadoop-node2
$ ssh-copy-id -i /root/.ssh/id_dsa.pub hadoop-node3
$ ssh hadoop-node1
$ exit
$ ssh hadoop-node2
$ exit
$ ssh hadoop-node3
$ exit

6、安装统一工作目录(所有节点都执行)
# 软件安装路径
$ mkdir -p /opt/bigdata/hadoop/server
# 数据存储路径
$ mkdir -p /opt/bigdata/hadoop/data
# 安装包存放路径
$ mkdir -p /opt/bigdata/hadoop/software
7、安装JDK(所有节点都执行)
官网下载:https://www.oracle.com/java/technologies/downloads/
百度下载
链接:https://pan.baidu.com/s/1-rgW-Z-syv24vU15bmMg1w
提取码:8888
$ cd /opt/bigdata/hadoop/software
$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/bigdata/hadoop/server/
# 在文件加入环境变量/etc/profile
export JAVA_HOME=/opt/bigdata/hadoop/server/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# source加载
$ source /etc/profile
# 查看jdk版本
$ java -version

4)开始安装Hadoop
1、解压上面我编译好的安装包
$ cd /opt/bigdata/hadoop/software
$ tar -zxvf hadoop-3.3.1.tar.gz -C /opt/bigdata/hadoop/server/
$ cd /opt/bigdata/hadoop/server/
$ cd hadoop-3.3.1/
$ ls -lh

2、安装包目录说明
| 目录 | 说明 |
|---|---|
| bin | hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用hadoop |
| etc | hadoop配置文件所在的目录 |
| include | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些文件均是用c++定义,通常用于c++程序访问HDFS或者编写MapReduce程序。 |
| lib | 该目录包含了hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。 |
| libexec | 各个服务队用的shell配置文件所在的免疫力,可用于配置日志输出,启动参数(比如JVM参数)等基本信息。 |
| sbin | hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动、关闭脚本。 |
| share | hadoop 各个模块编译后的jar包所在的目录。官方示例也在其中 |
3、修改配置文件
配置文件目录:/opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop
官方文档:https://hadoop.apache.org/docs/r3.3.1/
- 修改hadoop-env.sh
# 在hadoop-env.sh文件末尾追加
export JAVA_HOME=/opt/bigdata/hadoop/server/jdk1.8.0_212
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 修改core-site.xml #核心模块配置
在
fs.defaultFS
hdfs://hadoop-node1:8082
hadoop.tmp.dir
/opt/bigdata/hadoop/data/hadoop-3.3.1
hadoop.http.staticuser.user
root
hadoop.proxyuser.hosts
*
hadoop.proxyuser.root.groups
*
fs.trash.interval
1440
- hdfs-site.xml #hdfs文件系统模块配置
在
dfs.namenode.secondary.http-address
hadoop-node2:9868
dfs.webhdfs.enabled
true
- 修改mapred.xml #MapReduce模块配置
在
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop-node1:10020
mapreduce.jobhistory.webapp.address
hadoop-node1:19888
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.map.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
- 修改yarn-site.xml #yarn模块配置
在
yarn.resourcemanager.hostname
hadoop-node1
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
yarn.log-aggregation-enable
true
yarn.log.server.url
http://hadoop-node1:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
604880
- 修改workers
将下面内容覆盖文件,默认只有localhost
hadoop-node1
hadoop-node2
hadoop-node3

4、分发同步hadoop安装包到另外几台机器
$ cd /opt/bigdata/hadoop/server/
$ scp -r hadoop-3.3.1 hadoop-node2:/opt/bigdata/hadoop/server/
$ scp -r hadoop-3.3.1 hadoop-node3:/opt/bigdata/hadoop/server/
5、将hadoop添加到环境变量(所有节点)
$ vi /etc/profile
export HADOOP_HOME=/opt/bigdata/hadoop/server/hadoop-3.3.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 加载
$ source /etc/profile
6、Hadoop集群启动(hadoop-node1上执行)
1)(首次启动)格式化namenode(只能执行一次)
- 首次启动HDFS时,必须对其进行格式化操作
- format本质上初始化工作,进行HDFS清理和准备工作
$ hdfs namenode -format

2)手动逐个进程启停
每台机器每次手动启动关闭一个角色进程,可以精确控制每个进程启停,避免群起群停
1、HDFS集群启动
$ hdfs --daemon start|stop namenode|datanode|secondarynamenode
2、YARN集群启动
$ yarn --daemon start|stop resourcemanager|nodemanager
3)通过shell脚本一键启动
在hadoop-node1上,使用软件自带的shell脚本一键启动。前提:配置好机器之间的SSH免密登录和works文件
- HDFS集群启停
$ start-dfs.sh
$ stop-dfs.sh #这里不执行

检查java进程
$ jps

- YARN集群启停
$ start-yarn.sh
$ stop-yarn.sh # 这里不执行
# 查看java进程
$ jps

通过日志检查,日志路径:/opt/bigdata/hadoop/server/hadoop-3.3.1/logs
$ cd /opt/bigdata/hadoop/server/hadoop-3.3.1/logs
$ ll

- Hadoop集群启停(HDFS+YARN)
$ start-all.sh
$ stop-all.sh
4)通过web页面访问
【注意】在window C:WindowsSystem32driversetchosts文件配置域名映射,hosts文件中增加如下内容:
192.168.0.113 hadoop-node1
192.168.0.114 hadoop-node2
192.168.0.115 hadoop-node3
1、HDFS集群
地址:http://namenode_host:9870
这里地址为:http://192.168.0.113:9870

2、YARN集群
地址:http://resourcemanager_host:8088
这里地址为:http://192.168.0.113:8088

到此为止,hadoop和yarn集群就已经部署完了~
六、Hadoop实战操作
1)HDFS实战操作
- 命令介绍
# 访问本地文件系统
$ hadoop fs -ls file:///
# 默认不带协议就是访问hdfs文件系统
$ hadoop fs -ls /
- 查看配置
$ cd /opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop
$ grep -C5 "fs.defaultFS" core-site.xml

# 这里加上hdfs协议与不带协议等价
$ hadoop fs -ls hdfs://hadoop-node1:8082/

【温馨提示】所以默认不带协议就是访问HDFS文件系统
- 老版本的使用方式
$ hdfs dfs -ls /
$ hdfs dfs -ls hdfs://hadoop-node1:8082/
1、创建和删除文件
# 查看
$ hadoop fs -ls /
# 创建目录
$ hadoop fs -mkdir /test20211214
$ hadoop fs -ls /
# 创建文件
$ hadoop fs -touchz /test20211214/001.txt
$ hadoop fs -ls /test20211214

2、web端查看

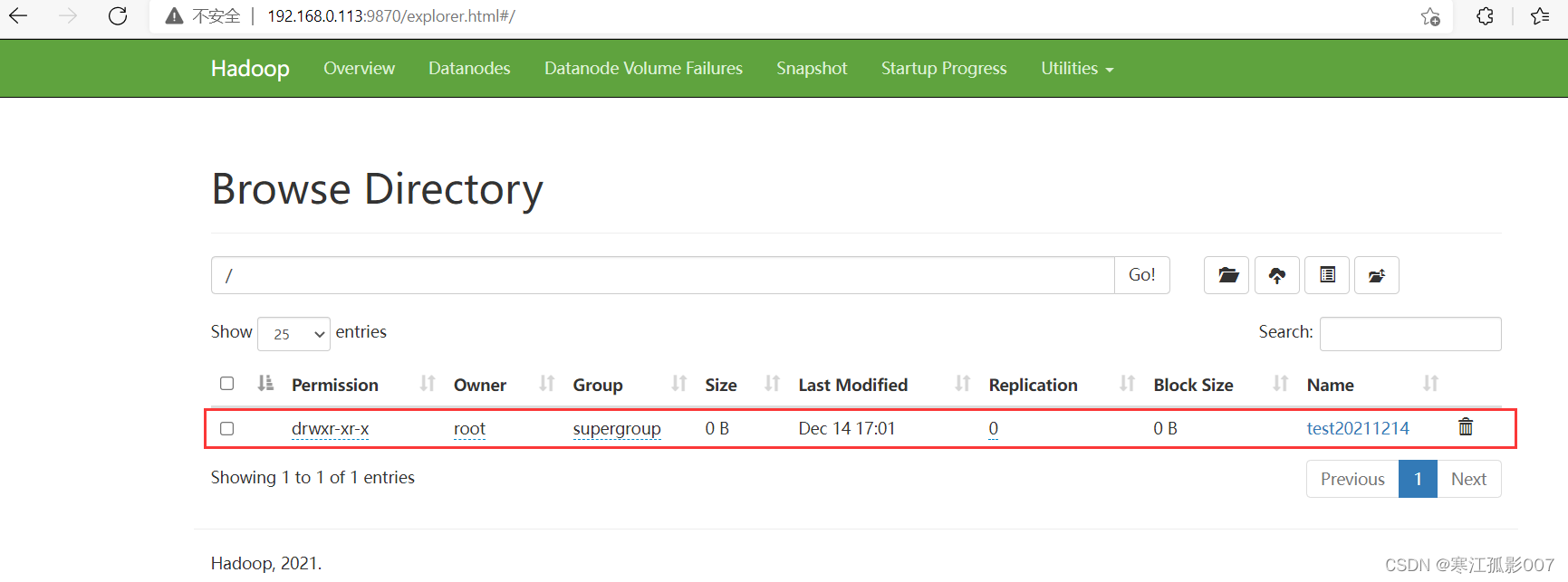
# 删除文件
$ hadoop fs -rm /test20211214/001.txt
# 删除目录
$ hadoop fs -rm -r /test20211214
3、推送文件到hdfs
$ touch test001.txt
$ hadoop fs -put test001.txt /
$ hadoop fs -ls /

4、从hdfs上拉取文件
# 把test001.txt拉取下来,并改名为a.txt
$ hadoop fs -get /test001.txt a.txt

2)MapReduce+YARN实战操作
执行Hadoop官方自带的MapReduce案例,评估圆周率Π的值
$ cd /opt/bigdata/hadoop/server/hadoop-3.3.1/share/hadoop/mapreduce
$ hadoop jar hadoop-mapreduce-examples-3.3.1.jar pi 2 4

统计单词
创建hello.txt,文件内容如下:
hello hadoop yarn world
hello yarn hadoop
hello world
在hdfs创建存放文件目录
$ hadoop fs -mkdir -p /wordcount/input
# 把文件上传到hdfs
$ hadoop fs -put hello.txt /wordcount/input/
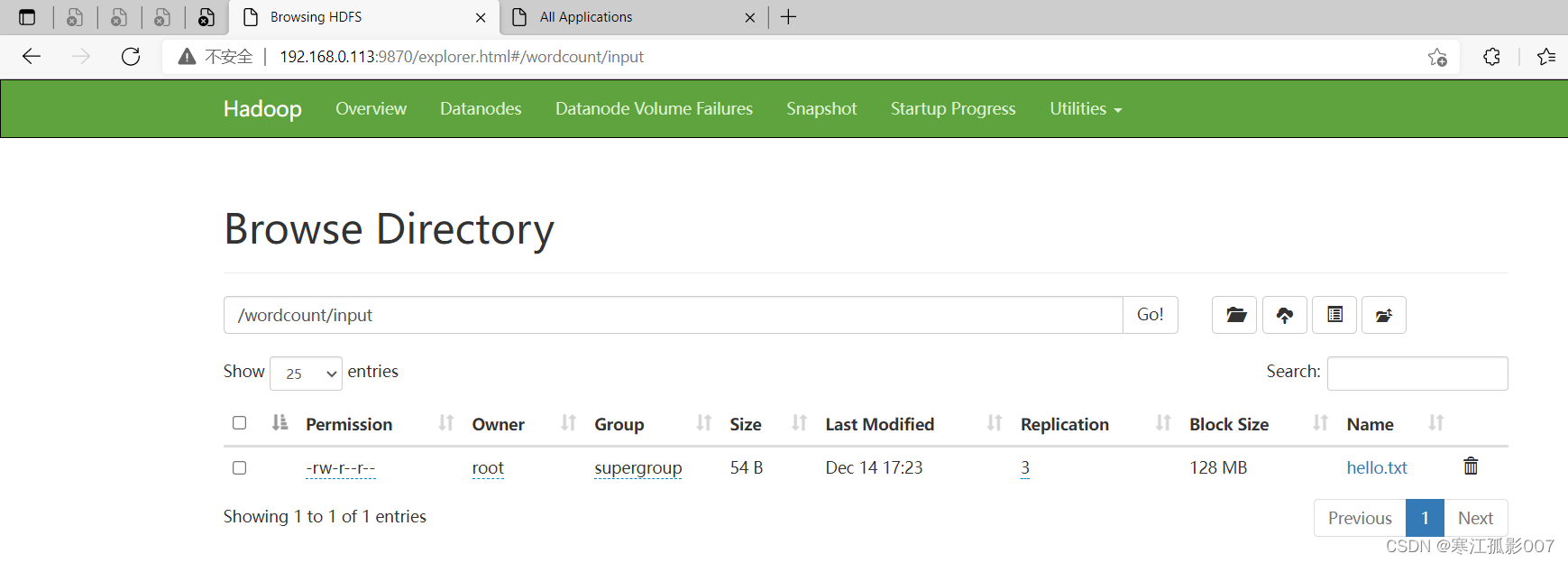
执行
$ cd /opt/bigdata/hadoop/server/hadoop-3.3.1/share/hadoop/mapreduce
$ hadoop jar hadoop-mapreduce-examples-3.3.1.jar wordcount /wordcount/input /wordcount/output


3)Yarn的常用命令
使用语法:yarn application [options] #打印报告,申请和杀死任务
-appStates #与-list一起使用,可根据输入的逗号分隔的应用程序状态列表来过滤应用程序。有效的应用程序状态可以是以下之一:ALL,NEW,NEW_SAVING,SUBMITTED,ACCEPTED,RUNNING,FINISHED,FAILED,KILLED
-appTypes #与-list一起使用,可以根据输入的逗号分隔的应用程序类型列表来过滤应用程序。
-list #列出RM中的应用程序。支持使用-appTypes来根据应用程序类型过滤应用程序,并支持使用-appStates来根据应用程序状态过滤应用程序。
-kill #终止应用程序。
-status #打印应用程序的状态。
简单示例
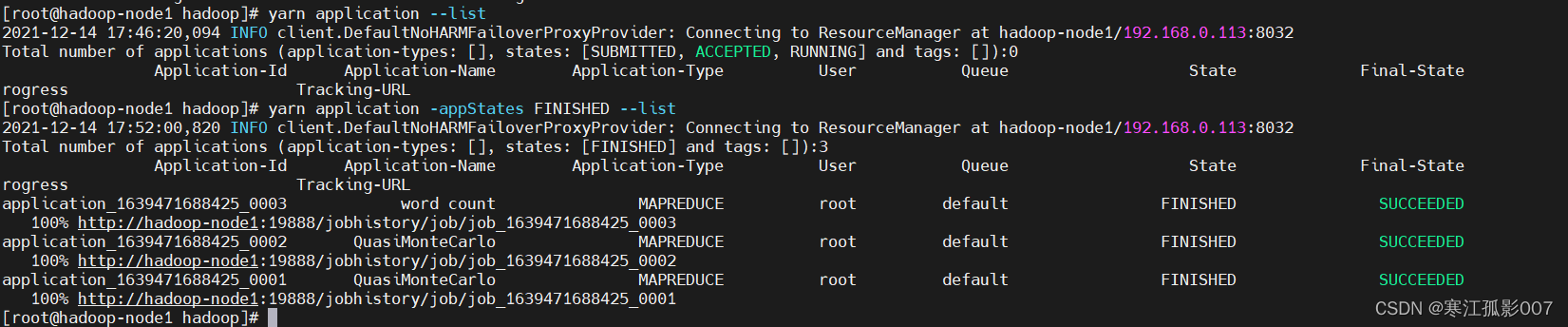
# 列出在运行的应用程序
$ yarn application --list
# 列出FINISHED的应用程序
$ yarn application -appStates FINISHED --list
更多操作命令,可以自行查看帮助
$ yarn -help
[root@hadoop-node1 hadoop]# yarn -help
Usage: yarn [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or yarn [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
--buildpaths attempt to add class files from build tree
--config dir Hadoop config directory
--daemon (start|status|stop) operate on a daemon
--debug turn on shell script debug mode
--help usage information
--hostnames list[,of,host,names] hosts to use in worker mode
--hosts filename list of hosts to use in worker mode
--loglevel level set the log4j level for this command
--workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
daemonlog get/set the log level for each daemon
node prints node report(s)
rmadmin admin tools
scmadmin SharedCacheManager admin tools
Client Commands:
app|application prints application(s) report/kill application/manage long running application
applicationattempt prints applicationattempt(s) report
classpath prints the class path needed to get the hadoop jar and the required libraries
cluster prints cluster information
container prints container(s) report
envvars display computed Hadoop environment variables
fs2cs converts Fair Scheduler configuration to Capacity Scheduler (EXPERIMENTAL)
jar run a jar file
logs dump container logs
nodeattributes node attributes cli client
queue prints queue information
schedulerconf Updates scheduler configuration
timelinereader run the timeline reader server
top view cluster information
version print the version
Daemon Commands:
nodemanager run a nodemanager on each worker
proxyserver run the web app proxy server
registrydns run the registry DNS server
resourcemanager run the ResourceManager
router run the Router daemon
sharedcachemanager run the SharedCacheManager daemon
timelineserver run the timeline server
SUBCOMMAND may print help when invoked w/o parameters or with -h.
这里只是简单的dmeo案例演示操作,后面会有企业级的案例+实战操作分享,请耐心等待……
原文地址:https://www.cnblogs.com/liugp/archive/2022/04/05/16101242.html








