
这篇文章将为大家详细讲解有关如何使用python爬虫爬取大学排名信息,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。

这次爬取的网址请搜索“阿凡题”(纯技术讨论)
“阿凡题”(纯技术讨论)
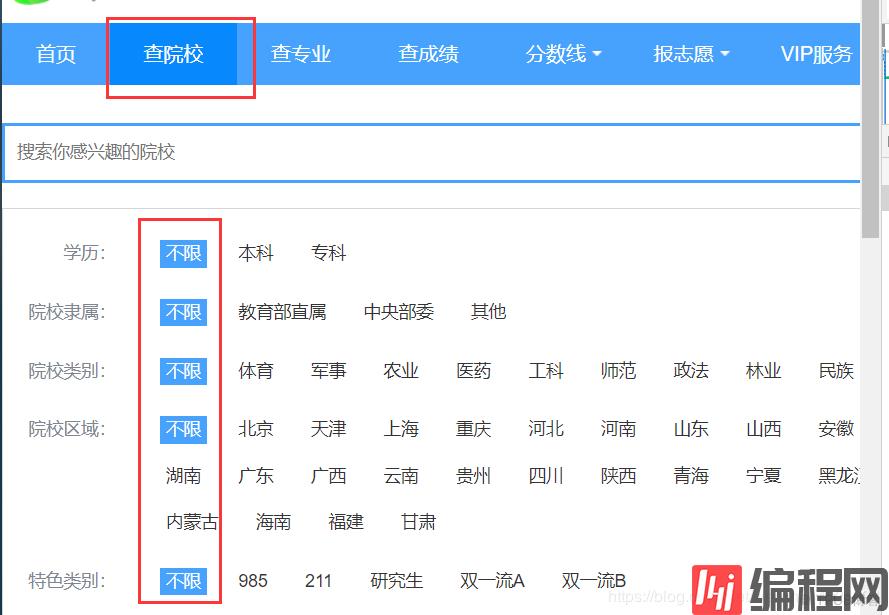
在该网址选择查院校,其他都是默认
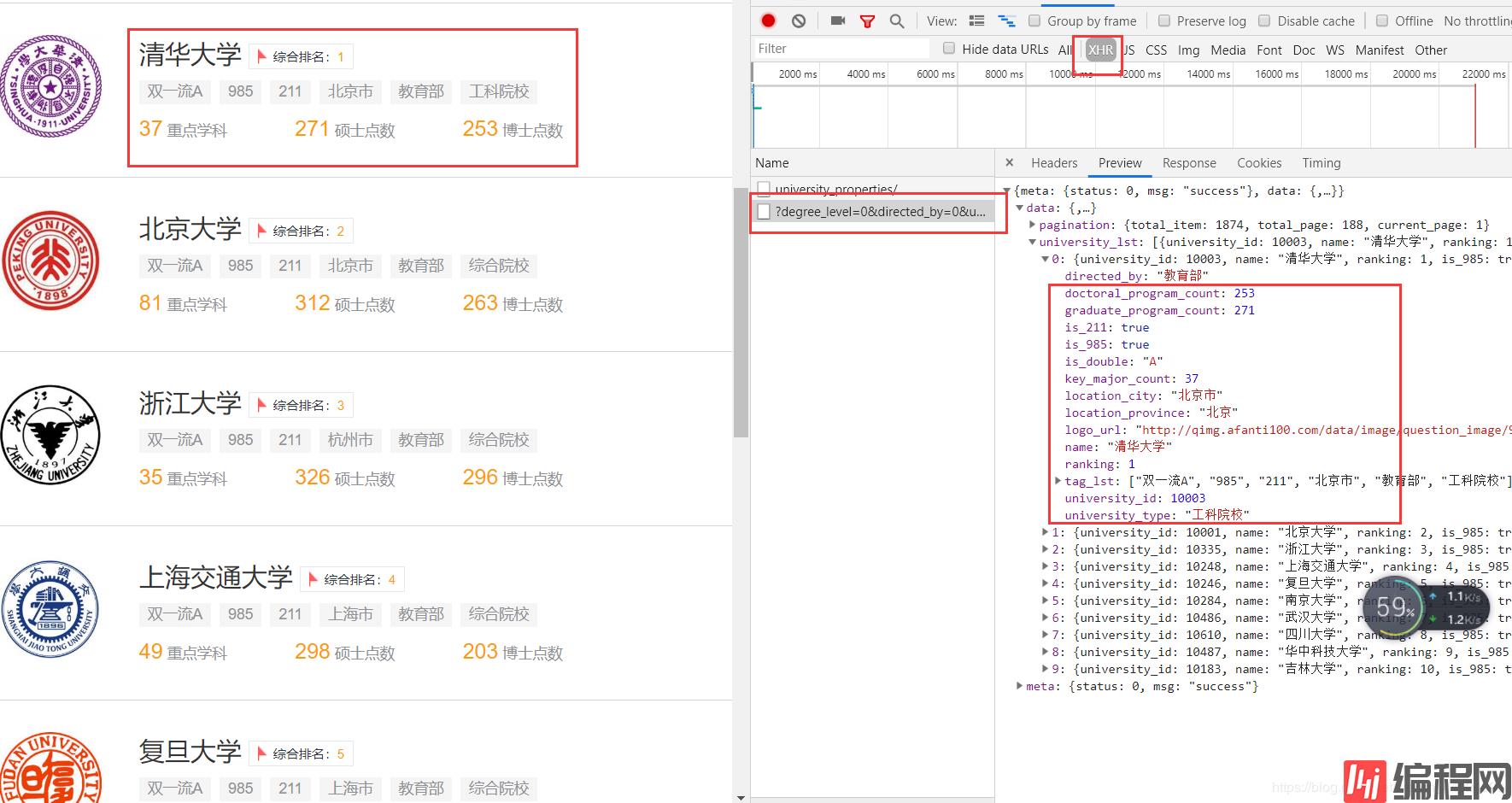
 4. 这次爬取的信息主要是下图红框的内容,在浏览器开发者中,点击XHR就可以发现这个接口,接口的内容都有我们需要的信息。
4. 这次爬取的信息主要是下图红框的内容,在浏览器开发者中,点击XHR就可以发现这个接口,接口的内容都有我们需要的信息。
先构建请求头,请求头直接复制过来了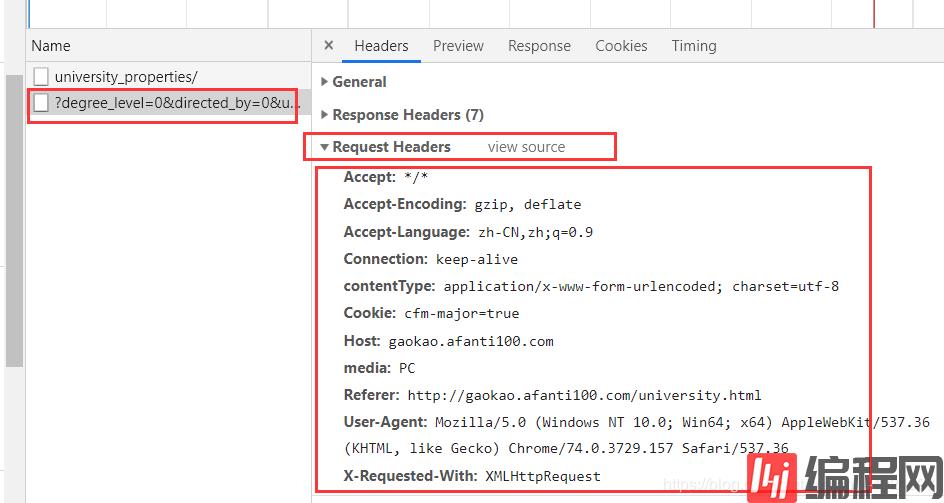
# 构建请求头
headers = {
'Accept': '**',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'contentType': 'application/x-www-form-urlencoded; charset=utf-8',
'Cookie': 'cfm-major=true',
'Host': 'gaokao.afanti100.com',
'media': 'PC',
'Referer': 'http://gaokao.afanti100.com/university.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
# 声明一个列表存储字典
data_list = []
def get_index():
page = 1
while True:
if page > 188:
break
url = 'http://gaokao.afanti100.com/api/v1/universities/?degree_level=0&directed_by=0' \
'&university_type=0&location_province=0&speciality=0&page={}'.format(page)
# page自增一实现翻页
page += 1
# 请求url并返回的是json格式
resp = requests.get(url, headers=headers).json()
# 取出大学所在的键值对
university_lsts = resp.get('data').get('university_lst')
if university_lsts:
get_info(university_lsts)
else:
continue
def get_info(university_lsts):
# 判断列表是否不为空
if university_lsts:
# 遍历列表取出每个大学的信息
for university_lst in university_lsts:
# 声明一个字典存储数据
data_dict = {}
# 大学名字
data_dict['name'] = university_lst.get('name')
# 大学排名
data_dict['ranking'] = university_lst.get('ranking')
# 大学标签
data_dict['tag_lst'] = university_lst.get('tag_lst')
# 大学重点学科
data_dict['key_major_count'] = university_lst.get('key_major_count')
# 硕士点数
data_dict['graduate_program_count'] = university_lst.get('graduate_program_count')
# 博士点数
data_dict['doctoral_program_count'] = university_lst.get('doctoral_program_count')
# 是否211
data_dict['is_211'] = university_lst.get('is_211')
# 是否985
data_dict['is_985'] = university_lst.get('is_985')
# 哪个省
data_dict['location_province'] = university_lst.get('location_province')
# 哪个城市
data_dict['location_city'] = university_lst.get('location_city')
# 大学类型
data_dict['university_type'] = university_lst.get('university_type')
data_list.append(data_dict)
print(data_dict)
def save_file():
# 将数据存储为json文件
with open('大学排名信息.json', 'w', encoding='utf-8') as f:
json.dump(data_list, f, ensure_ascii=False, indent=4)
print('json文件保存成功')
# 将数据存储为csv文件
# 表头
title = data_list[0].keys()
with open('大学排名信息.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 写入数据
writer.writerows(data_list)
print('csv文件保存成功')
def main():
get_index()
save_file()
if __name__ == '__main__':
main()
关于“如何使用python爬虫爬取大学排名信息”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。







