
为什么有这篇"杂项"文章
实在是因为python中对象方面的内容太多、太乱、太杂,在写相关文章时比我所学过的几种语言都更让人"糟心",很多内容似独立内容、又似相关内容,放这也可、放那也可、放这也不好、放那也不好。
所以,用一篇单独的文章来收集那些在我其它文章中不好归类的知识点,而且会随时更新。
class、type、object的关系
在python 3.x中,类就是类型,类型就是类,它们变得完全等价。
要理解class、type、object的关系,只需几句话:
- object是所有类的祖先类,包括type类也继承自object
- 所有class自身也是对象,所有类/类型都是type的实例对象,包括object和type自身都是type的实例对象
论证略,网上一大堆。
鸭子模型(duck typing)
Duck typing的概念来源于的诗句"When I see a bird that walks like a duck and swims like a duck and quacks like a duck, I call that bird a duck."。
意思是:如果我看到一只鸟走路像一只鸭子,游泳像一只鸭子,叫起来像一只鸭子,那么我就认为这只鸟是一只鸭子。
在python中,鸭子模型非常容易理解。下面是典型的鸭子模型示例:
class Duck():
def walk(self):
print("duck walk")
def swim(self):
print("duck swim")
def quacks(self):
print("duck quacks")
class Bird():
def walk(self):
print("bird walk")
def swim(self):
print("bird swim")
def quacks(self):
print("bird quacks")对于Python来说,鸭子模型的意思是:只要某个地方需要调用Duck的walk、swim、quacks方法,就可以让Bird也作为Duck,因为它也实现了这3个方法。
Python并不强制检查类型,只要对象实现了某个所需要的方法,就认为这是可以接受的对象。
它还传达一种思想,A类对象能放在一个地方,如果想让B类对象也可以放在这个地方,只需要让B实现这个地方所需要的方法就可以。
鸭子模型贯穿了python中的运算符重载行为,也贯穿了整个Python的类设计理念。例如print()执行的时候需要调用__str__方法,所以只要实现了__str__方法的类,都可以被print()调用。
绑定方法和非绑定方法
绑定之意,在于方法是否与实例对象(或类名)进行了绑定。
当通过实例对象去调用方法时,或者说会自动传递self的方法是绑定方法,其它通过类名调用、手动传递self的方法调用是非绑定方法,在3.x中没有非绑定方法的概念,它直接被当作是普通函数。
例如:
class cls():
def m1(self):
print("m1: ", self)
def m2(arg1):
print("m2: ", arg1)当通过cls类的实例对象去调用m1、m2的时候,是绑定方法:
>>> c = cls()
>>> c.m1
<bound method cls.m1 of <__main__.cls object at 0x000001EE2DA75860>>
>>> c.m1()
m1: <__main__.cls object at 0x000001EE2DA75860>
>>> c.m2
<bound method cls.m2 of <__main__.cls object at 0x000001EE2DA75860>>
>>> c.m2()
m2: <__main__.cls object at 0x000001EE2DA75860>也就是说,绑定方法中是绑定了实例对象的,无需手动去传递实例对象。例如:
>>> cc = c.m1
>>> cc()
m1: <__main__.cls object at 0x000001EE2DA75860>当通过类名去访问的时候,是普通函数(非绑定方法):
>>> cls.m1
<function cls.m1 at 0x000001EE2DA78620>
>>> cls.m2
<function cls.m2 at 0x000001EE2DA786A8>
>>> cls.m1(c)
m1: <__main__.cls object at 0x000001EE2DA75860>
>>> cls.m2(c)
m2: <__main__.cls object at 0x000001EE2DA75860>唯一需要在意的是,并非一定要通过实例对象去调用方法,通过类方法也能的调用,也能手动传递实例对象。此外,类中的方法并非一定要求有self参数。
静态方法和类方法
python的面向对象中有3种类型的方法:普通的实例方法、类方法、静态方法。
- 普通实例方法:通过self参数传递实例对象自身
- 类方法:传递的是类名而非对象
- 静态方法:不通过self传递
从这些方法的简单定义上看,很容易知晓实例方法可以操作类属性、对象属性,而类方法和静态方法只能操作类属性,不能操作对象属性。
所以,要实现类方法、静态方法需要合理地定义、传递参数。例如:
class cls():
def m1(self, arg1):
print("m1: ", self, arg1)
def m2(arg1, arg2):
print("m2: ", arg1)显然这里m2()是静态方法,m1根据调用方式可以是类方法,也可以是实例方法,甚至是静态方法。例如:
# m1作为实例方法
>>> c.m1("hello")
m1: <__main__.cls object at 0x000001EE2DA75BA8> hello
# m1作为类方法,通过类名调用,并传递类名作为self参数
>>> cls.m1(cls,"hello")
m1: <class '__main__.cls'> hello
# m1作为静态方法,通过类名调用,随意处置self参数
>>> cls.m1("asdfas","hello")
m1: asdfas hello这样的调用方式并没有什么问题,python是允许这样做的,很自由,但很容易犯错。比如想要通过对象名去调用上面的m2,arg1就必须当作self一样解释成对象自身,换句话说只能传递一个参数c.m2("arg2"),这显然有悖静态方法的编码方式。
在python中,要定义严格的类方法、静态方法,需要使用内置的装饰器函数classmethod()、staticmethod()来装饰,装饰后无论使用对象名去调用还是使用类名去调用,都可以。
例如:
class cls():
def m1(self,arg1):
print("m1: ", self, arg1)
@classmethod
def m2(self,arg1):
print("m2: ", self, arg1)
@staticmethod
def m3(arg1, arg2):
print("m3: ", arg1, arg2)上面定义了普通方法、类方法和静态方法。如果尚不了解装饰器的用法,暂时只需知道上面的@xxx将它下面的函数(方法)扩展成了类方法、静态方法即可。
调用实例方法:
>>> c = cls()
>>> c.m1("hello")
m1: <__main__.cls object at 0x000001EE2DA840B8> hello注意输出的self是"...object...",和下面的类方法调用注意区分比较。
调用类方法。因为@classmethod已经将m2包装成了类方法,所以m2的第一个self参数将总是代表类名,而无论是使用对象去调用m2还是使用类名去调用m2。
>>> c.m2("hello")
m2: <class '__main__.cls'> hello
>>> cls.m2("hello")
m2: <class '__main__.cls'> hello如果输出m2方法,会发现它已经是绑定方法,也就是说和类名进行了绑定(这里不是和对象名进行绑定)。
>>> c.m2
<bound method cls.m2 of <class '__main__.cls'>>
>>> cls.m2
<bound method cls.m2 of <class '__main__.cls'>>调用静态方法。
>>> c.m3("hello","world")
m3: hello world
>>> cls.m3("hello","world")
m3: hello world静态方法都是未绑定的函数:
>>> c.m3
<function cls.m3 at 0x000001EE2DA789D8>
>>> cls.m3
<function cls.m3 at 0x000001EE2DA789D8>一般来说,类方法用于在类中操作/返回和类名有关的内容,静态方法用于在类中做和类或对象完全无关的操作。一个比较好理解的例子是,一个Employee类,要检查员工的年龄范围在16-35,如果年龄在这范围内,就返回一个员工对象,可以将这个逻辑定义为类方法。如果只是检查年龄范围来决定True或False这样和类/对象无关的操作,则定义为静态方法。
class Employee:
@staticmethod
def age_ok(age):
if 16<age<35:
return True
else:
return False
@classmethod
def age_check(cls, age):
if 16<age<35:
return cls(...)私有属性
python没有private关键字来修饰属性使其变成私有属性,但是带上双下划线前缀的属性且没有后缀下划线的属性(__X)可以认为是私有属性。它仅仅只是约定性的私有属性,不代表外界真的不能访问。
实际上,使用__X这样的属性,在类的内部访问时会自动进行扩展为_clsname__X,也就是加个前缀下划线,再加个类名。因为扩展时加上了类名,使得这个属性在名称上是独属于这个类的。
例如:
class cls():
__X = 12
def m1(self,y):
self.__Y = y
print(self.__X)
print(self.__Y)
>>> print(cls.__dict__.keys())
dict_keys([..., '_cls__X', 'm1', ....])
>>> c = cls()
>>> c.m1(22)
12
22
>>> print(c.__dict__.keys())
dict_keys(['_cls__Y'])因为已经扩展了属性的名称,所以无法在类的外界通过直接的名称__X去访问对应的属性。
>>> c.__Y
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'cls' object has no attribute
'__Y'
>>> c.__X
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'cls' object has no attribute
'__X'
>>> cls.__X
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: type object 'cls' has no attribute '__X'前面说了,这种加双下划线前缀的属性仅仅只是一个约定形式,虽然在外界无法直接通过名称去访问,但是仍有不少方法去访问。例如通过扩展后的名称、通过字典__dict__:
>>> cls._cls__X
12
>>> c._cls__Y
22
>>> c.__dict__['_cls__Y']
22要想严格地声明属性的私有性,可以编写装饰器类,在装饰器类中完成属性的判断。
方法的默认可变参数陷阱
如果一个方法的参数给了默认参数,且这个默认参数是一个可变类型,那么这里有一个陷阱:使用这个默认参数的时候各对象会共享这个可变默认值。
例如:
class A:
def __init__(self, arg=[]):
self.data = arg
def add(self, value):
self.data.append(value)
# 两个不同对象,且都使用参数arg的默认值
a1 = A()
a2 = A()
# 向两个对象中添加元素
a1.add("a1")
a2.add("a2")
print(a1.data)
print(a2.data)执行结果:
['a1', 'a2']
['a1', 'a2']发现a1和a2这两个不同的对象中的data竟然是相同的数据,如果输出下它们的data属性,会发现是同一个对象:
>>> a1.data is a2.data
True这是因为参数的默认值是在申请变量之前就先评估好的,也就是在赋值给参数变量arg之前,这个空列表就已经存在了。然后使用默认值来构造对象时,这些对象都使用同一个空列表,而这个空列表是可变的类型,所以无论谁修改这个列表都会影响其它对象。
如果不使用默认值,那么每个对象的列表就是独占的,不会被其它对象修改。
a3 = A([])
a3.add("a3")
print(a3.data)结果:
['a3']MethodType:添加外部函数作为方法
python的types模块中提供了一个MethodType(funcName, instance)函数,它可以将类外部定义的函数funcName链接到实例对象或类上。
例如连接到实例对象上:
# 注意外部函数上加了self参数
def func(self, age):
print(age)
class cls:
pass
>>> c = cls
>>> import types
>>> c.printage = types.MethodType(func, c)
>>> c.printage(22)
22type.MethodType()是将某个可调用对象(这里的func)动态地链接到实例对象或类上,使其临时作为对象或类的方法属性,只有在被调用的时候才会进行属性的添加。
需要注意的是,当外部函数链接到实例对象上时,这个链接只对这个实例对象有效,其它对象是不具备这个属性的。如果链接到类上,那么所有对象都可以访问这个链接的方法。
__call__
正常情况下定义了一个类,调用这个类表示创建一个对象。
class cls:
pass
c = cls()但是,对象c不再是可调用的对象,也就是说,它不能再被执行。
>>> callable(c)
Falsepython对象的__call__可以让实例对象也变成可调用类型,就像函数一样。
class cls:
def __call__(self, *args, **kwargs):
print('__call__: ', args, kwargs)
>>> c = cls()
>>> c(1,2,3,x=4,y=5)
__call__: (1, 2, 3) {'x': 4, 'y': 5}
>>> callable(c)
True将类定义为一个可调用对象是非常有用的,它可以像函数一样去修饰、扩展其它内容的功能,特别是编写装饰器类的时候。
例如,正常情况下写装饰器总要返回一个新装饰器函数,但是想要直接使用类作为装饰器,就需要在这个类中定义__call__,将__call__作为函数装饰器中的装饰器函数wrapped()。下面是一个示例:
import types
from functools import wraps
class DecoratorClass():
def __init__(self, func):
wraps(func)(self)
self.callcount = 0
def __call__(self, *args, **kwargs):
self.callcount += 1
return self.__wrapped__(*args, **kwargs)
def __get__(self, instance, cls):
if instance is None:
return self
else:
return types.MethodType(self, instance)上面是装饰器类,可以像函数装饰器一样去装饰其它函数。
@DecoratorClass
def add(x, y):
return x + y
>>> add(2,3)
5
>>> add(3,4)
7
>>> add.callcount
2判断对象是否可调用的几种方式
根据前面的说明可知,判断一个对象是否是可调用的依据有2种方式:
- 使用内置函数callable(X),X可调用则返回True,否则False
- 注:返回False一定表示不可调用,但返回True不代表一定可调用
- 注:返回False一定表示不可调用,但返回True不代表一定可调用
- 判断是否定义了
__call__方法。使用hasattr(obj,'__call__')即可判断
>>> callable(c)
True
>>> hasattr(c,'__call__')
True__slots__
python是一门动态语言,而且是极其开放的动态语言。在面向对象上,它允许我们随意地、任意时间地添加属性。例如:
class cls():
attr1 = 111 # 在类中添加属性
def __init__(self):
self.attr2 = 222 # 添加实例对象的属性
>>> c = cls()
>>> c.attr3 = 333 # 在类的外部添加属性
>>> c.__dict__.keys()
dict_keys(['attr2', 'attr3'])如果想要限定对象只能拥有某些属性,可以使用__slots__来限定,__slots__可以指定为一个元组、列表、集合等。
例如:
class cls():
__slots__ = ['a', 'b']
>>> c = cls()
>>> c.a=13
>>> c.b=14
>>> c.cc=15 # 报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'cls' object has no attribute
'cc'但注意:
-
__slots__定义在类级别上,它仅仅只限定实例对象属性,不会限制类属性
-
__slots__不会被子类继承
-
__slots__定义后,对象默认就没有了__dict__属性- 但可以将
__dict__放进__slots__的范围内来允许__dict__
- 但可以将
- 还有几个注意点在下面的示例中解释
例如:
class cls():
__slots__ = ['a', 'b']
x = 13 # 允许定义类属性
c = cls()
c.a = 14
c.b = 15
cls.y = 16 # 允许定义类属性
print(c.x, c.a, c.b, c.y)
print(cls.__dict__.keys()) # 类有__dict__属性
print(c.__dict__.keys()) # 报错,对象没有__dict__属性可以将__dict__放进__slots__中,使得对象可以带有属性字典。但这会让__slots__的限定失效:实例对象可以继续添加任意属性,那些不在__slots__中的属性会加入到__dict__中。
class cls1():
__slots__ = ['a', 'b', '__dict__']
cc = cls1()
cc.a = 14
cc.b = 15
cc.c = 16
cc.d = 17
print(cc.__slots__)
print(cc.__dict__.keys())输出结果:
['a', 'b', '__dict__']
dict_keys(['c', 'd'])因为子类不会继承父类的__slots__,所以如果父类中没有定义__slots__的话,因为子类可以访问父类的__dict__,这会使得子类自身定义的__slots__的属性限定功能失效。
class cls1():
pass
class cls2(cls1):
__slots__ = ['a', 'b']
ccc = cls2()
ccc.a=13
ccc.b=14
ccc.ddd=15
print(ccc.__slots__)
print(ccc.__dict__.keys())结果:
['a', 'b']
dict_keys(['ddd'])多重继承和__mro__和super()
python支持多重继承,只需将需要继承的父类放进子类定义的括号中即可。
class cls1():
...
class cls2():
...
class cls3(cls1,cls2):
...上面cls3继承了cls1和cls2,它的名称空间将连接到两个父类名称空间,也就是说只要cls1或cls2拥有的属性,cls3构造的对象就拥有(注意,cls3类是不拥有的,只有cls3类的对象才拥有)。
但多重继承时,如果cls1和cls2都具有同一个属性,比如cls1.x和cls2.x,那么cls3的对象c3.x取哪一个?会取cls1中的属性x,因为规则是按照(括号中)从左向右的方式搜索父类。
再考虑一个问题,如果cls1中没有属性x,但它继承自cls0,而cls0有x属性,那么,c3.x取哪个属性。
这在python 3.x中是一个比较复杂的问题,它根据MRO(Method Resolution Order)算法来决定多重继承时的访问顺序,这个算法的规则可以总结为:先左后右,先深度再广度,但必须遵循共同的超类最后搜索。
下面是一个访问顺序图示:
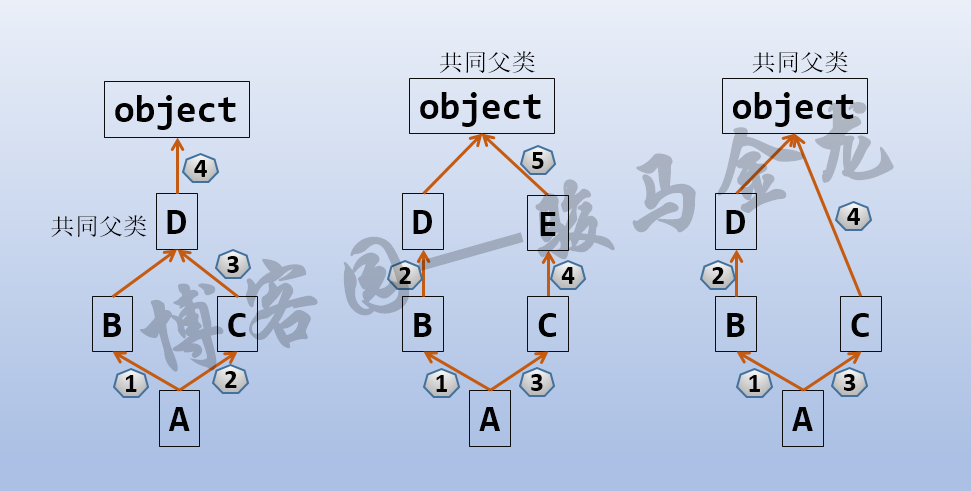
每个类都有一个__mro__属性,这个属性是一个元组,从左向右的元素顺序代表的是属性搜索顺序。
class D():
pass
class C(D):
pass
class B(D):
pass
class A(B, C):
pass
>>> A.__mro__
(<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class 'object'>)
>>> D.__mro__
(<class '__main__.D'>, <class 'object'>)不仅多重继承时是按照MRO顺序进行属性搜索的,super()引用的时候也一样是按照mro算法来引用属性的,所以super并不一定总是引用父类属性。
例如:
class D():
def __init__(self):
print("D")
class C(D):
def __init__(self):
print("C")
super().__init__()
class B(D):
def __init__(self):
print("B")
super().__init__() # 调用的不是父类D的构造方法
class A(B, C):
def __init__(self):
print("A")
super().__init__()
a = A()输出结果为:
A
B
C
D面向对象中,一般不推荐使用多重继承,因为很容易出现属性引用混乱的问题,而且有些面向对象的语言根本就不支持多重继承。但在Python中,使用多重继承的情况也非常多,如果真的要使用多重继承,一定要设计好类。一种更好的方式是使用Mixin类,见下文。
关于Mixin
Mixin的wiki页:https://en.wikipedia.org/wiki/Mixin
对于那些想要从多个类中继承的方法,如果想要避免多重继承可能引起的属性混乱,可以将这些方法单独编写到一个类中,而这个功能/方法相对单一的类称为Mixin类。
Mixin类通过特殊的多重继承方法来扩展主类的功能,却又很安全,不会出现多重继承时属性混乱的问题。
例如:
class Mixin1():
def test1(self):
print("test1 method provided by Mixin1")
class Mixin2():
def test2(self):
print("test2 method provided by Mixin1")
class Base():
def mymethod(self):
print("mymethod is the base method")
class Myclass(Mixin1, Mixin2, Base):
pass上面的Mixin1和Mixin2是Mixin类,它们都只有一个方法,功能非常单一,它们可以看作是Base类的功能扩充类,也可以认为Mixin类是主类Include的类。
例如wiki页中给的一个例子,class TCPServer中提供了UDP/TCP server的功能,这时每个连接都通过一个相同的进程进行处理。但是可以将class ThreadingMixIn通过Mixin的方法对TCPServer进行扩充:
class ThreadingTCPServer(ThreadMixIn, TCPServer):
pass这相当于将ThreadingMixIn类中的方法添加到了TCPServer类中,使得每个新连接都会创建一个新的线程,这个功能是ThreadMixIn提供的,但看上去作用在TCPServer上。
关于Mixin类,有几个编码规范需要遵守:
- 类名使用Mixin结尾,例如ListMixin、AbcMixin
- 多重继承时Mixin类放在主类的前面,或者说主类放在最后面,避免主类有和Mixin类中重名函数而使得Mixin类失效
- Mixin类中不规定只能定义一个方法,而是少定义一点,让功能尽量单一、独立
抽象类
抽象类是指:这个类的子类必须重写这个类中的方法,且这个类没法进行实例化产生对象。
先说明在Python中如何定义抽象类。Python中的abc模块(Abstract Base Classes)专门用来实现抽象类、接口。
例如,在设计某个程序的缓存接口时,想要让它未来既可以使用普通的cache,也可以使用redis缓存。那么只需要定义一个抽象的类Cache,里面实现两个抽象方法get()和set(),以后无论使用普通的cache还是redis缓存,都只需让这两种缓存类型实现且必须实现get()和set()即可。
import abc
class Cache(metaclass=abc.ABCMeta):
@abc.abstractmethod
def get(self, key):
pass
@abc.abstractmethod
def get(self, key, value):
pass
# 子类继承时,必须实现这两个方法
class CacheBase(Cache):
def get(self, key):
pass
def set(self, key, value):
pass
class Redis(Cache):
def get(self, key):
pass
def set(self, key, value):
pass如果子类没有实现或者少实现了抽象类中的方法,在构造子类实例化对象的时候就会立即报错。
在Python中大多数时候不建议直接定义抽象类,这可能会造成过度封装/过度抽象的问题。如果想要让子类必须实现父类的某个方法,可以在父类方法中加上raise来抛出异常NotImplementedError,这时如果子类对象没有实现该方法,就会查找到父类的这个方法,从而抛出异常。
class Cache():
def get(self, key):
raise NotImplementedError("must define get method")
def set(self, key):
raise NotImplementedError("must define set method")使用raise NotImplementedError的方式来模拟抽象类,它只有在调用到set/get的时候才会抛异常,在实例化对象的时候或者没有调用到这两个方法的时候不会报错。








