
一 背景
随着数据时效性对企业的精细化运营越来越重要,“实时即未来”、“实时数仓”、“数据湖” 成为了近几年炙手可热的词。流计算领域的格局也在这几年发生了巨大的变化,Apache Flink 在流批一体的方向上不断深耕,Apache Spark 的近实时处理有着一定的受众,Apache Kafka 也有了 ksqlDB 高调地进军流计算,而 Apache Storm 却开始逐渐地退出历史的舞台。
每一种引擎有其优势的地方,如何选择适合自己业务的流计算引擎成了一个由来已久的话题。除了比较各个引擎提供的不同的功能矩阵之外,性能是一个无法绕开的评估因素。基准测试(benchmark)就是用来评估系统性能的一个重要和常见的过程。
二 现有流计算基准测试的问题
目前在流计算领域中,还没有一个行业标准的基准测试。目前业界较为人知的流计算 benchmark 是五年前雅虎 Storm 团队发布的 Yahoo Streaming Benchmarks[4]。雅虎的原意是因为业界缺少反映真实场景的 benchmark,模拟了一个简单的广告场景来比较各个流计算框架,后来被广泛引用。具体场景是从 Kafka 消费的广告的点击流,关联 Redis 中的广告所属的 campaign 信息,然后做时间窗口聚合计数。
然而,正是因为雅虎团队太过于追求还原真实的生产环境,导致这些外部系统服务(Kafka, Redis)成为了作业的瓶颈。Ververica 曾在这篇文章[5]中做过一个扩展实验,将数据源从 Kafka 替换成了一个内置的 datagen source,性能提升了 37 倍!由此可见,引入的 Kafka 组件导致了无法准确反映引擎真实的性能。更重要的一个问题是,Yahoo Benchmark 只包含一个非常简单的,类似 “Word Count” 的作业,它无法全面地反映当今复杂的流计算系统和业务。试想,谁会用一个简单的 “Word Count” 去衡量比较各个数据库之间的性能差异呢?正是这些原因使得 Yahoo Benchmark 无法成为一个行业标准的基准测试。这也正是我们想要解决的问题。
因此,我们认为一个行业标准的基准测试应该具备以下几个特点:
可复现性
可复现性是使得 benchmark 被信任的一个重要条件。许多 benchmark 的结果是难以重现的。有的是因为只摆了个 benchmark 结果图,用于生成这些结果的代码并没有公开。有的是因为用于 benchmark 的硬件不容易被别人获取到。有的是因为 benchmark 依赖的服务太多,致使测试结果不稳定。
能代表和覆盖行业真实的业务场景( query 量)
例如数据库领域非常著名的 TPC-H、TPC-DS 涵盖了大量的 query 集合,来捕获查询引擎之间细微的差别。而且这些 query 集合都立于真实业务场景之上(商品零售行业),数据规模大,因此也很受一些大数据系统的青睐。
能调整作业的负载(数据量、数据分布)
在大数据领域,不同的数据规模对于引擎来说可能会是完全不同的事情。例如 Yahoo Benchmark 中使用的 campaign id 只有 100 个,使得状态非常小,内存都可以装的下。这样使得同步 IO 和 checkpoint 等的影响可以忽略不计。而真实的场景往往要面对大状态,面临的挑战要复杂困难的多。像 TPC-DS 的数据生成工具会提供 scalar factor 的参数来控制数据量。其次在数据分布上最好也能贴近真实世界的数据,如有数据倾斜,及调整倾斜比例。从而能全面、综合地反映业务场景和引擎之间地差异。
有统一的性能衡量指标和采集汇总工具
基准测试的性能指标的定义需要清晰、一致,且能适用于各种计算引擎。然而流计算的性能指标要比传统批处理的更难定义、更难采集。是流计算 benchmark 最具挑战性的一个问题,这也会在下文展开描述。
我们也研究了很多其他的流计算相关的基准测试,包括:StreamBench、HiBench、BigDataBench,但是它们都在上述几个基本面有所欠缺。基准测试的行业标杆无疑是 TPC 发布的一系列 benchmark,如 TPC-H,TPC-DS。然而这些 benchmark 是面向传统数据库、传统数仓而设计的,并不适用于今天的流计算系统。例如 benchmark 中没有考虑事件时间、数据的乱序、窗口等流计算中常见的场景。因此我们不得不考虑重新设计并开源一个流计算基准测试框架——Nexmark。
地址:https://github.com/nexmark/nexmark。
三 Nexmark 基准测试框架的设计
为了提供一个满足以上几个基本面的流计算基准测试,我们设计和开发了 Nexmark 基准测试框架,并努力让其成为流计算领域的标准 benchmark 。
Nexmark 基准测试框架来源于 NEXMark 研究论文[1],以及 Apache Beam Nexmark Suite[6],并在其之上进行了扩展和完善。Nexmark 基准测试框架不依赖任何第三方服务,只需要部署好引擎和 Nexmark,通过脚本 nexmark/bin/run_query.sh all 即可等待并获得所有 query 下的 benchmark 结果。下面我们将探讨 Nexmark 基准测试在设计上的一些决策。
1 移除外部 source、sink 依赖
如上所述,Yahoo Benchmark 使用了 Kafka 数据源,却使得最终结果无法准确反映引擎的真实性能。此外,我们还发现,在 benchmark 快慢流双流 JOIN 的场景时,如果使用了 Kafka 数据源,慢流会超前消费(快流易被反压),导致 JOIN 节点的状态会缓存大量超前的数据。这其实不能反映真实的场景,因为在真实的场景下,慢流是无法被超前消费的(数据还未产生)。所以我们在 Nexmark 中使用了 datagen source,数据直接在内存中生成,数据不落地,直接向下游节点发送。多个事件流都由单一的数据生成器生成,所以当快流被反压时,也能抑制慢流的生成,较好地反映了真实场景。
与之类似的,我们也移除了外部 sink 的依赖,不再输出到 Kafka/Redis,而是输出到一个空 sink 中,即 sink 会丢弃收到的所有数据。
通过这种方式,我们保证了瓶颈只会在引擎自身,从而能精确地测量出引擎之间细微的差异。
2 Metrics
批处理系统 benchmark 的 metric 通常采用总体耗时来衡量。然而流计算系统处理的数据是源源不断的,无法统计 query 耗时。因此,我们提出三个主要的 metric:吞吐、延迟、CPU。Nexmark 测试框架会自动帮我们采集 metric,并做汇总,不需要部署任何第三方的 metric 服务。
吞吐
吞吐(throughput)也常被称作 TPS,描述流计算系统每秒能处理多少条数据。由于我们有多个事件流,所有事件流都由一个数据生成器生成,为了统一观测角度,我们采用数据生成器的 TPS,而非单一事件流的 TPS。我们将一个 query 能达到的最大吞吐,作为其吞吐指标。例如,针对 Flink 引擎,我们通过 Flink REST API 暴露的.numRecordsOutPerSecond metric 来获取当前吞吐量。
延迟
延迟(Latency)描述了从数据进入流计算系统,到它的结果被输出的时间间隔。对于窗口聚合,Yahoo Benchmark 中使用 output_system_time - window_end 作为延迟指标,这其实并没有考虑数据在窗口输出前的等待时间,这种计算结果也会极大地受到反压的影响,所以其计算结果是不准确的。一种更准确的计算方式应为 output_system_time - max(ingest_time)。然而在非窗口聚合,或双流 JOIN 中,延迟又会有不同的计算方式。
所以延迟的定义和采集在流计算系统中有很多现实存在的问题,需要根据具体 query 具体分析,这在参考文献[2]中有详细的讨论,这也是我们目前还未在 Nexmark 中实现延迟 metric 的原因。
CPU
资源使用率是很多流计算 benchmark 中忽视的一个指标。由于在真实生产环境,我们并不会限制流计算引擎所能使用的核数,从而给系统更大的弹性。所以我们引入了 CPU 使用率,作为辅助指标,即作业一共消耗了多少核。通过吞吐/cores,可以计算出平均每个核对于吞吐的贡献。对于进程的 CPU 使用率的采集,我们没有使用 JVM CPU load,而是借鉴了 YARN 中的实现,通过采样/proc/ /stat 并计算获得,该方式可以获得较为真实的进程 CPU 使用率。因此我们的 Nexmark 测试框架需要在测试开始前,先在每台机器上部署 CPU 采集进程。
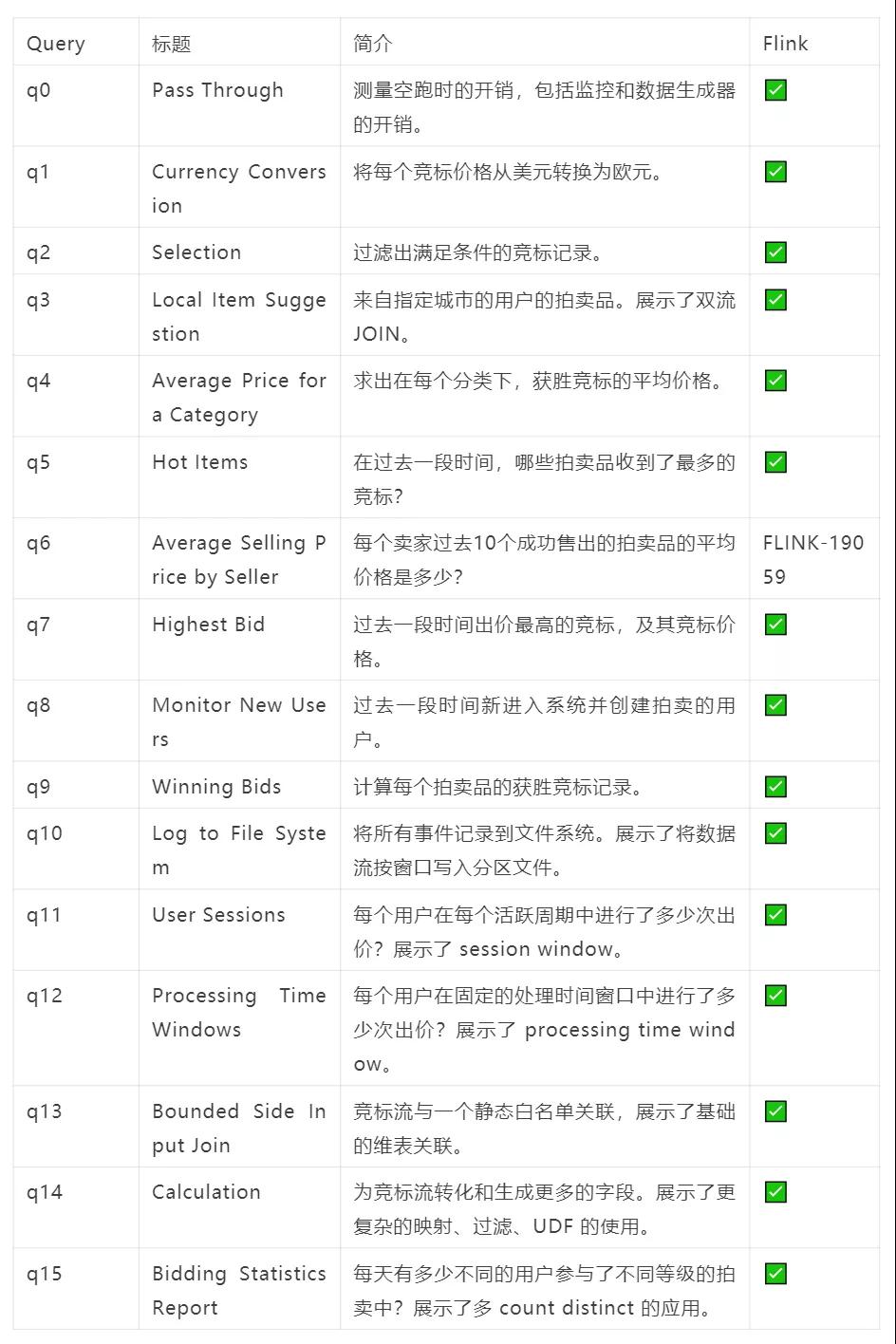
3 Query 与 Schema
Nexmark 的业务模型基于一个真实的在线拍卖系统。所有的 query 都基于相同的三个数据流,三个数据流会有一个数据生成器生成,来控制他们之间的比例、数据偏斜、关联关系等等。这三个数据流分别是:
- 用户(Person):代表一个提交拍卖,或参与竞标的用户。
- 拍卖(Auction):代表一个拍卖品。
- 竞标(Bid):代表一个对拍卖品的出价。
我们一共定义了 16 个 query,所有的 query 都使用 ANSI SQL 标准语法。基于 SQL ,我们可以更容易地扩展 query 测试集,支持更多的引擎。然而,由于 Spark 在流计算功能上的限制,大部分的 query 都无法通过 Structured Streaming 来实现。因此我们目前只支持测试 Flink SQL 引擎。
4 作业负载的配置化
我们也支持配置调整作业的负载,包括数据生成器的吞吐量以及吞吐曲线、各个数据流之间的数据量比例、每个数据流的数据平均大小以及数据倾斜比例等等。具体的可以参考 Source DDL 参数。
四 实验结果
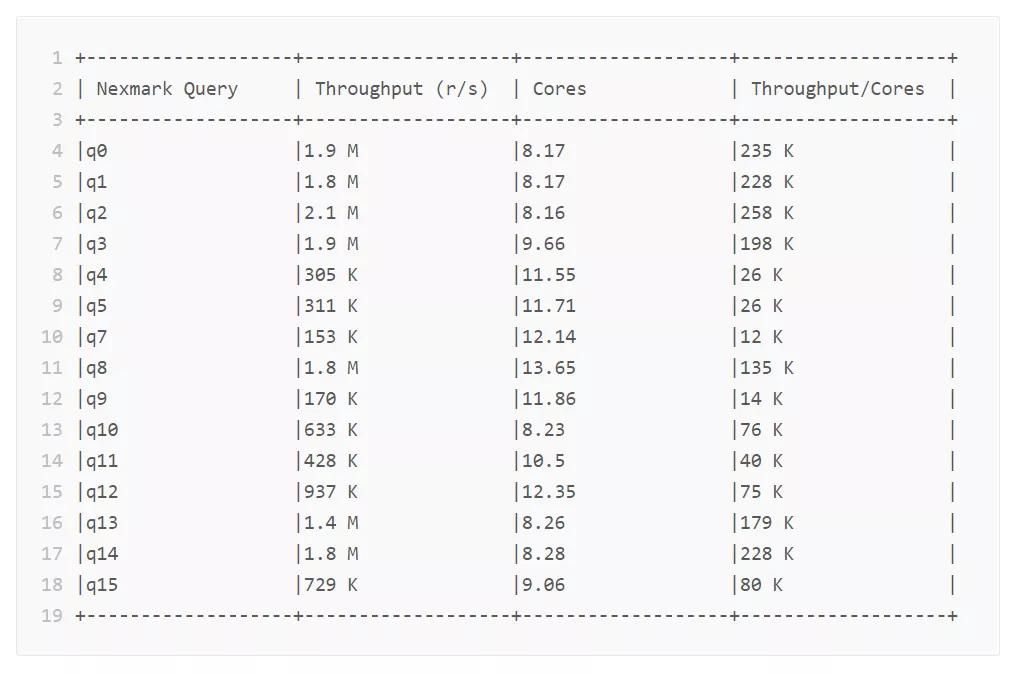
我们在阿里云的三台机器上进行了 Nexmark 针对 Flink 的基准测试。每台机器均为 ecs.i2g.2xlarge 规格,配有 Xeon 2.5 GHz CPU (8 vCores) 以及 32 GB 内存,800 GB SSD 本地磁盘。机器之间的带宽为 2 Gbps。
测试了 flink-1.11 版本,我们在这 3 台机器上部署了 Flink standalone 集群,由 1 个 JobManager,8 个 TaskManager (每个只有 1 slot)组成,都是 4 GB内存。集群默认并行度为 8。开启 checkpoint 以及 exactly once 模式,checkpoint 间隔 3 分钟。使用 RocksDB 状态后端。测试发现,对于有状态的 query,每次 checkpoint 的大小在 GB 级以上,所以有效地测试的大状态的场景。
Datagen source 保持 1000 万每秒的速率生成数据,三个数据流的数据比例分别是 Bid: 92%,Auction: 6%,Person: 2%。每个 query 都先运行 3 分钟热身,之后 3 分钟采集性能指标。
运行 nexmark/bin/run_query.sh all 后,打印测试结果如下:
五 总结
我们开发和设计 Nexmark 的初衷是为了推出一套标准的流计算 benchmark 测试集,以及测试流程。虽然目前仅支持了 Flink 引擎,但在当前也具有一定的意义,例如:
推动流计算 benchmark 的发展和标准化。
作为 Flink 引擎版本迭代之间的性能测试工具,甚至是日常回归工具,及时发现性能回退的问题。
在开发 Flink 性能优化的功能时,可以用来验证性能优化的效果。
部分公司可能会有 Flink 的内部版本,可以用作内部版本与开源版本之间的性能对比工具。
当然,我们也计划持续改进和完善 Nexmark 测试框架,例如支持 Latency metric,支持更多的引擎,如 Spark Structured Streaming, Spark Streaming, ksqlDB, Flink DataStream 等等。也欢迎有志之士一起加入贡献和扩展。
参考及引用
[1]Pete Tucker and Kristin Tufte. "NEXMark – A Benchmark for Queries over Data Streams". June 2010.[2]Jeyhun Karimov and Tilmann Rabl. "Benchmarking Distributed Stream Data Processing Systems". arXiv:1802.08496v2 [cs.DB] Jun 2019[3]Yangjun Wang. "Stream Processing Systems Benchmark: StreamBench". May 2016.[4]https://github.com/yahoo/streaming-benchmarks[5]https://www.ververica.com/blog/extending-the-yahoo-streaming-benchmark[6]https://beam.apache.org/documentation/sdks/java/testing/nexmark/








{kind=link}
{kind=link}