
对于读操作来说,就涉及到我们的数据库共享缓冲池如何设计的问题了。比较新的MySQL版本在支持DIO的操作系统上默认使用DIO读取文件,因此设置一个足够大的innodb buffer就可以了,采用默认的配置就不存在PG类似Double Buffering的问题。PG数据库使用者对此争论较多,PG官方文档也是建议shared_buffers不用太大,给OS留下足够的内存用于优化IO。
昨天的案例讲了因为PG的DOUBLE BUFFERING导致的SQL执行忽快忽慢的问题,有些朋友在问是不是Oracle之外的很多数据库都是用类似的方式读取文件,这种Double Buffering技术是不是很落后,是不是必须加以改进。实际上,只要是使用文件系统,并且在读数据时没有采用DIO的数据库都会存在DOUBLE BUFFERING的问题,早期的Oracle也存在类似问题。
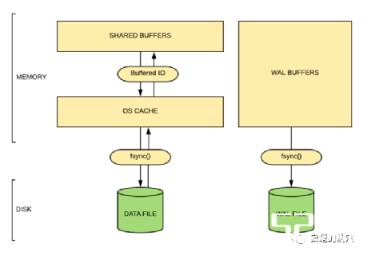
上图比较清晰的说明了DOUBLE BUFFERING问题,对于写的情况,因为先写入CACHE,再由OS把CACHE写入磁盘,中间会有一些性能损失,不过对于现代的数据库来说,只有REDO/WAL是需要强一致性写入的,数据文件的写入不会阻塞数据库的读写访问,因此这种性能损失是可以接受的。并且现代硬件上,IO延时已经极大的降低了,这点损失也没有太大的问题。
对于读操作来说,就涉及到我们的数据库共享缓冲池如何设计的问题了。比较新的MySQL版本在支持DIO的操作系统上默认使用DIO读取文件,因此设置一个足够大的innodb buffer就可以了,采用默认的配置就不存在PG类似Double Buffering的问题。PG数据库使用者对此争论较多,PG官方文档也是建议shared_buffers不用太大,给OS留下足够的内存用于优化IO。
为什么PG还会坚持这样模式来实现数据库缓冲呢?实际上维护一个极大的共享缓冲区,保持并发读写性能也是十分难做好的。对于不同的应用场景,缓冲的策略也会不同。如果经常由一些大表的扫描访问,往往数据不会重复被访问,这种情况如果加载到共享缓冲中再去访问,会加大共享缓冲的闩锁(对于PG来说就是轻量级锁)争用,引起数据库的性能问题,加大热块冲突的延时,这样就得不偿失了。Oracle在对待此类问题,也采用了直接路径读这样的方式来解决。
目前使用MySQL的大型数据库比较少,即使有些MySQL库的总容量也达到数个TB,但是实际上被经常访问的数据也不过几百M,因此不太容易碰到共享缓冲性能带来的总体性能问题。而在一些比较大的PG数据库上,并发读写较高场景下,我们已经遇到过不少LWLOCK带来的性能问题,我以前的文章中也提到过从算法上看,PG的shared buffers算法效率会略低于Oracle的DB CACHE,这些现象似乎也是对此的一种佐证。
在某些场景下,不把shared buffers设置的过大,使用OS FILE CACHE来作为辅助,也是一种优化策略,就像前几天讨论过的数据库可以把一些复杂的不太容易做好的事情交给OS去做。有些应用系统中给shared buffer配置了绝大多数的OS内存效果也不错,但是这种模式下访问冷数据的性能会打折扣。通过pgfincore这样的工具来做预热可以大幅度提升某些定期的分析任务对大表扫描的执行效率。
今天不讨论shared buffer配置策略的问题,这方面我以前已经写过几篇文章探讨了,有兴趣的朋友可以去公众号上搜索一下。今天我们讨论一个因为double buffering机制导致的几个PG指标指示性失效的问题。在PG的shared buffer的不同配置策略下,有些情况下的物理读可能并不是真正的物理读,而是“假物理读”,因此针对PG数据库,共享缓冲池命中率和物理读这两个指标是会存在比较严重的误解的。
在Oracle数据库中,我们会针对物理读的突然增加产生一个性能告警。因为这可能意味着某些SQL执行存在异常,或者IO负载突然增加,可能会引发一些不确定的数据库性能问题。

这个故障模型在D-SMART里也被拷贝到了PG数据库中,但是这个故障模型的告警,在PG数据库中可能没有在Oracle上那么有效。因为不同的shared buffers配置策略可能会导致某些时候产生的物理读实际上并不是真正的从存储设备上读取数据,而是从FILE CACHE中读取数据。很可能这种突发的物理读增加并不是一个需要告警的故障,而是一种被预先设计好的正常现象,如果不分青红皂白的去告警就会不准确了。作为一个通用的运维工具产品,我们又无法预知用户的应用场景与设计理念,因此这个故障模型必须做改造。
数据库缓冲命中率指标也存在类似问题,某些场景中,数据库缓冲命中率低有可能是PG数据库设定好的场景,无需告警。我们如果还是模仿Oracle的方式来预警则可能会产生大量的误报。如果新增的“数据库物理读”大部分都产生了操作系统的物理读,那么才需要进行告警,而如果新增的“数据库物理读”并没有大幅增加OS的物理IO,那么这种现象可能是数据库参数配置的正常现象,应该被自动排除。
针对数据库缓冲区命中率的理解也是如此,当数据库缓冲区命中率较低的时候,我们没有必要直接报警,而是要看操作系统IO总量是否大幅度增加,如果操作系统IO总量没有明显增加,那么这种数据库缓冲命中率的下降应该是正常的。
这两个在Oracle中可以使用的故障模型必须进行优化,加入实际物理读大幅增加的条件。但是如何描述大幅增加呢?这里就需要用到异常检测算法了。
在D-SMART中,1000105这个指标的含义是关键指标异常,这是一个复合指标,是针对基础指标进行异常检测生成的。比如30000100是操作系统的IOPS指标,当这个指标出现大幅上升的时候,就意味着IO异常增长。因此在那两个故障模型中,可以加入1000105[30000100]=4这个规则,从而让告警更为精准。
来源: 白鳝的洞穴
>>>>>>点击进入系统运维专题








