
多元线性回归预测模型
实验目的
通过多元线性回归预测模型,掌握预测模型的建立和应用方法,了解线性回归模型的基本原理
实验内容
多元线性回归预测模型
实验步骤和过程
(1)第一步:学习多元线性回归预测模型相关知识。
一元线性回归模型反映的是单个自变量对因变量的影响,然而实际情况中,影响因变量的自变量往往不止一个,从而需要将一元线性回归模型扩展到多元线性回归模型。
如果构建多元线性回归模型的数据集包含n个观测、p+1个变量(其中p个自变量和1个因变量),则这些数据可以写成下方的矩阵形式:
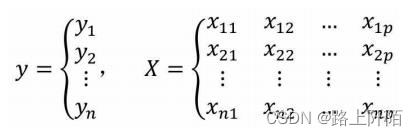
其中,xij代表第个i行的第j个变量值。如果按照一元线性回归模型的逻辑,那么多元线性回归模型应该就是因变量y与自变量X的线性组合,即可以将多元线性回归模型表示成:
y=β0+β1x1+β2x2+…+βpxn+ε
根据线性代数的知识,可以将上式表示成y=Xβ+ε。
其中,
β为p×1的一维向量,代表了多元线性回归模型的偏回归系数;
ε为n×1的一维向量,代表了模型拟合后每一个样本的误差项。
回归模型的参数求解
在多元线性回归模型所涉及的数据中,因变量y是一维向量,而自变量X为二维矩阵,所以对于参数的求解不像一元线性回归模型那样简单,但求解的思路是完全一致的。为了使读者掌握多元线性回归模型参数的求解过程,这里把详细的推导步骤罗列到下方:
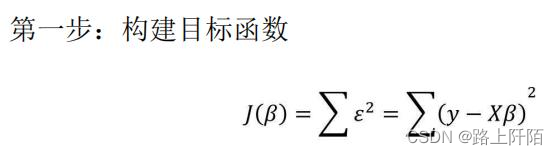
根据线性代数的知识,可以将向量的平方和公式转换为向量的内积,接下来需要对该式进行平方项的展现。


经过如上四步的推导,最终可以得到偏回归系数β与自变量X、因变量y的数学关系。这个求解过程也被成为“最小二乘法”。基于已知的偏回归系数β就可以构造多元线性回归模型。前文也提到,构建模型的最终目的是为了预测,即根据其他已知的自变量X的值预测未知的因变量y的值。
回归模型的预测
如果已经得知某个多元线性回归模型y=β0+β1x1+β2x2+…+βpxn,当有其他新的自变量值时,就可以将这些值带入如上的公式中,最终得到未知的y值。在Python中,实现线性回归模型的预测可以使用predict“方法”,关于该“方法”的参数含义如下:
predict(exog=None, transform=True)
exog:指定用于预测的其他自变量的值。
transform:bool类型参数,预测时是否将原始数据按照模型表达式进行转换,默认为True。
多元线性回归模型是一种统计分析方法,用于研究多个自变量对一个因变量的影响。它是线性回归模型的一种扩展,可以用于解决多个自变量对因变量的影响问题。 在多元线性回归模型中,我们假设因变量 y y y 与 k k k 个自变量 x1 , x2 , . . . , xk x_1, x_2, ..., x_k x1,x2,...,xk 之间存在线性关系,即: y= β 0 + β 1 x 1 + β 2 x 2 +...+ β k x k +ϵ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + ... + \beta_k x_k + \epsilon y=β0+β1x1+β2x2+...+βkxk+ϵ 其中 β0 , β1 , β2 , . . . , βk \beta_0, \beta_1, \beta_2, ..., \beta_k β0,β1,β2,...,βk 是模型的系数, ϵ \epsilon ϵ 是随机误差项。我们的目标是通过样本数据来估计模型的系数,从而建立预测模型。 多元线性回归模型的建立可以分为以下几个步骤:
收集数据:收集 n n n 组样本数据,每组数据包括因变量 y y y 和 k k k 个自变量 x1 , x2 , . . . , xk x_1, x_2, ..., x_k x1,x2,...,xk 的取值。
数据预处理:对数据进行清洗、缺失值处理、异常值处理等预处理工作,以保证数据的质量。
模型建立:利用最小二乘法等方法,对样本数据进行拟合,求出模型的系数 β0 , β1 , β2 , . . . , βk \beta_0, \beta_1, \beta_2, ..., \beta_k β0,β1,β2,...,βk。
模型评估:通过各种统计指标,如 R2 R^2 R2、均方误差等,对模型进行评估,判断模型的拟合效果。
模型应用:利用建立好的模型进行预测或分析,得出实际应用价值。 总之,多元线性回归模型是一种重要的统计分析方法,可以用于解决多个自变量对因变量的影响问题,是各种实际问题中常用的建模方法之一。
(2)第二步:数据准备,数据来源于课本例题。

序号 x1 年份 水路客运量y 市人口数x1 城市GDPx2
1 1991 342 520 211.9
2 1992 466 522.9 244.6
3 1993 492 527.1 325.1
4 1994 483 531.5 528.1
5 1995 530 534.7 645.1
6 1996 553 537.4 733.1
7 1997 581.5 540.4 829.7
8 1998 634.8 543.2 926.3
9 1999 656.1 545.3 1003.1
10 2000 664.4 551.5 1110.8
11 2001 688.3 554.6 1235.6
12 2002 684.4 557.93 1406
(3)第三步:使用 Python 编写实验代码并做图。
import pandas as pdimport numpy as npfrom sklearn.linear_model import LinearRegressionimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3D# 设置中文字体plt.rcParams['font.sans-serif'] = ['SimHei']# 读取Excel文件data = pd.read_excel('E:\\File\\class\\数据挖掘\\test2.xlsx')X = data[['市人口数x1', '城市GDPx2']]y = data['水路客运量y']# 训练模型model = LinearRegression()model.fit(X, y)# 预测未来水路客运量x_new = [[560, 1546]]y_pred = model.predict(x_new)print("预测未来水路客运量为:", y_pred[0])print(X)print(X['市人口数x1'])# 绘制图像fig = plt.figure()ax = fig.add_subplot(projection='3d')# ax.scatter(X[:, 0], X[:, 1], y)ax.scatter(X['市人口数x1'], X['城市GDPx2'], y)# x1, x2 = np.meshgrid(X[:, 0], X[:, 1])x1, x2 = np.meshgrid(X['市人口数x1'], X['城市GDPx2'])y_pred = model.predict(np.array([x1.flatten(), x2.flatten()]).T).reshape(x1.shape)ax.plot_surface(x1, x2, y_pred, alpha=0.5, cmap='viridis')ax.set_xlabel('市人口数x1')ax.set_ylabel('城市GDPx2')ax.set_zlabel('水路客运量y')plt.title('多元线性回归预测模型案例')plt.show()代码解释:
上面代码使用了Python中的pandas、numpy、scikit-learn和matplotlib库,实现了一个多元线性回归预测模型的案例。代码的主要功能是读取一个Excel文件中的数据,利用多元线性回归模型对数据进行拟合和预测,最后可视化结果。 具体代码解释如下:
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
首先导入所需的库,包括pandas、numpy、scikit-learn和matplotlib库。其中,LinearRegression类用于实现多元线性回归模型,Axes3D类用于绘制三维图形。
#读取Excel文件
data = pd.read_excel(‘E:\File\class\数据挖掘\test2.xlsx’)
利用pandas库中的read_excel方法读取Excel文件中的数据。
X = data[[‘市人口数x1’, ‘城市GDPx2’]]
y = data[‘水路客运量y’]
将读取到的数据按照自变量和因变量的关系进行划分,X表示自变量,y表示因变量。
#训练模型
model = LinearRegression()
model.fit(X, y)
利用scikit-learn库中的LinearRegression类进行多元线性回归模型的训练,fit方法用于拟合数据。
#预测未来水路客运量
x_new = [[560, 1546]]
y_pred = model.predict(x_new)
print(“预测未来水路客运量为:”, y_pred[0])
利用训练好的模型对新的数据进行预测,predict方法用于预测。输出预测结果。
print(X)
print(X[‘市人口数x1’])
输出自变量的数据。
#绘制图像
fig = plt.figure()
ax = fig.add_subplot(projection=‘3d’)
#ax.scatter(X[:, 0], X[:, 1], y)
ax.scatter(X[‘市人口数x1’], X[‘城市GDPx2’], y)
#x1, x2 = np.meshgrid(X[:, 0], X[:, 1])
x1, x2 = np.meshgrid(X[‘市人口数x1’], X[‘城市GDPx2’])
y_pred = model.predict(np.array([x1.flatten(), x2.flatten()]).T).reshape(x1.shape)
ax.plot_surface(x1, x2, y_pred, alpha=0.5, cmap=‘viridis’)
ax.set_xlabel(‘市人口数x1’)
ax.set_ylabel(‘城市GDPx2’)
ax.set_zlabel(‘水路客运量y’)
plt.title(‘多元线性回归预测模型案例’)
plt.show()
这一部分是绘制一个三维图形,其中fig是一个Figure对象,ax是一个Axes3D对象。首先用scatter方法绘制出原始数据点的三维散点图,然后用meshgrid方法将自变量的取值进行网格化,用predict方法预测出因变量的取值,最后用plot_surface方法绘制出三维图形。常用的参数有:alpha表示透明度,cmap表示颜色映射,set_xlabel、set_ylabel和set_zlabel分别表示三个坐标轴的标签,title表示图形的。最后调用show方法显示图形。
(4)第四步:实验结果。
绘图和预测当市人口数x1为560以及城市GDPx2为1546时的水路客运量y。
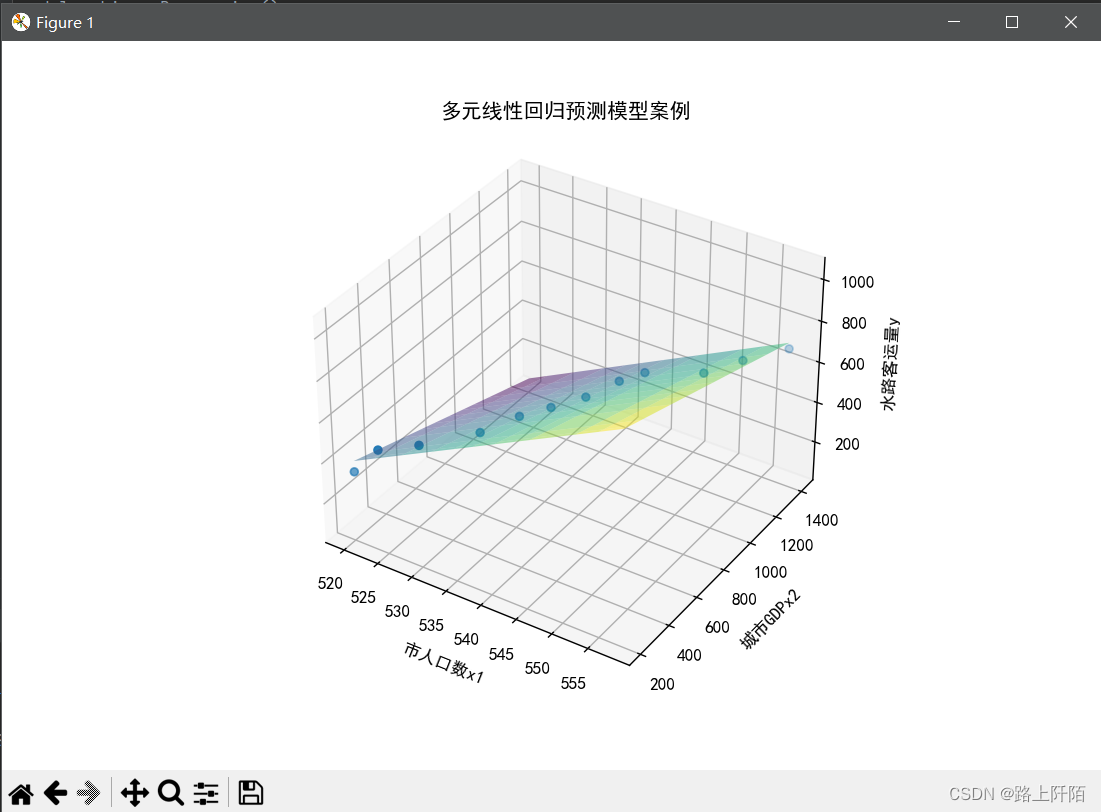
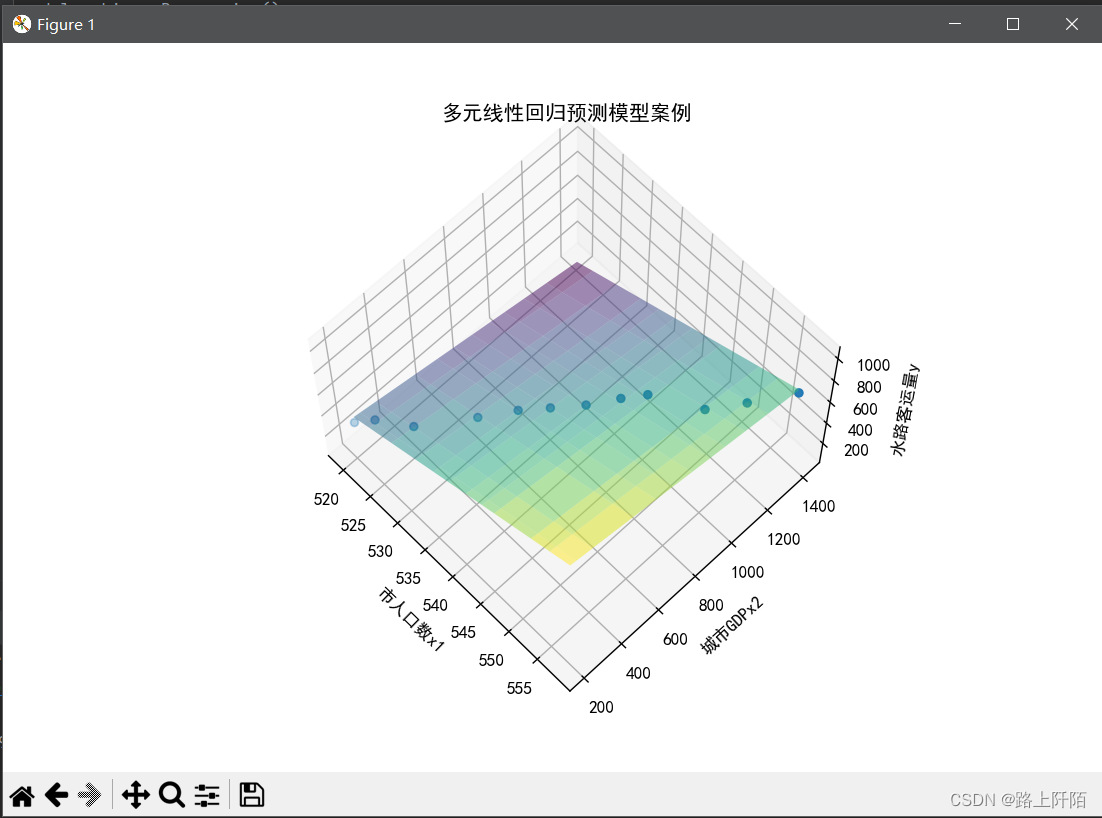

这里的预测结果为:711.2940429652463
实验总结
通过本次实验,我学习了多元线性回归预测模型的基本原理和建立方法,了解了如何使用Python编程实现预测模型。同时,我们也使用水路客运量预测实例,对线性回归模型进行了实际应用和分析。在实验中,我掌握了数据预处理、模型训练和结果评估等关键技术,对于今后的数据分析和预测工作将有很大的帮助。同时在这个过程之中也出现了一些问题,但通过查阅相关资料最终这些问题都得以解决。在这个过程中我的动手实践能力的到提升,也让我明白了实际动手操作的重要性,在实际操作中可以发现很多平时发现不了的问题,通过实践最终都得以解决。
来源地址:https://blog.csdn.net/m0_51431003/article/details/130461033









