
链路状态算法以图论作为理论基础,用图来表示网络拓扑结构,并利用图论中的最短路径算法来计算网络间的最佳路由,因此链路状态算法又被称作最短路径优先算法SPF。链路状态算法的思想是要求网络中所有参与链路状态路由协议的路由器都掌握网络的全部拓扑结构信息,并记录在路由数据库中。链路状态算法中路由数据库实质上是一个网络结构的拓扑图,该拓扑图由一个节点的集合和一个边的集合构成。在网络拓扑图中,结点代表网络中路由器,边代表路由器之间的物理链路。在网络拓扑结构图中,每一条链路上可以附加不同的属性,例如链路的状态、距离或费用等。如果没一个路由器所保存的网络拓扑结构图都是一致的,那么个路由器生成的路由表也是最佳的,不存在错误路由或循环路由。
1979年以前ARPANET(AdvancedResearchProjectAgency)一直使用的是距离矢量路由算法,但是在此之后便改为使用链路状态路由算法。当今,链路状态路由算法的变种算法——IS-IS(IntermediateSystem-IntermediateSystem)还有OSPF成为了使用最为广泛的路由算法。
链路路由算法分为下列5步:
(1)每个路由器发现它的邻居节点,并了解邻居节点的网络地址
(2)设置到每个邻居节点的距离或者成本度量值
(3)构造一个包含所有获得的链路向信息包
(4)将这个链路信息包发送给网络中其他路由器,同时也接受其他路由器发送过来的链路信息包
(5)计算出到其他路由器的最短路径(这一步就会使用到核心算法Dijkstra算法)
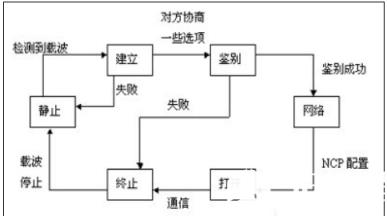
链路状态算法的优点:
具有更快的收敛速度
具有更好的功能扩展能力
具有在更好的在规模上的可升级性
链路状态算法的缺点:
每个路由器需要有较大的存储空间,用以存储所收到的每一个节点的链路状态分组;
计算工作量大,每次都必须计算最短路径。
链路状态选路算法的工作原理如下[2]
(1)在参与链路状态选路的路由器集合中,每个路由器都需要通过某种机制来了解自己所连接的链路及其状态。
(2)各路由器都能够将其所连接的链路的状态信息通知给网络中的所有其他路由器,这些链路信息包括链路状态、费用以及链路两端的路由器等。
(3)链路状态信息的通过链路状态分组(LSP)来向整个网络发布。一个LSP通常包含源路由器的标识符、相邻路由器的标识符,以及而知之间链路的费用。每一个LSP都将被网络中的所有的路由器接收,并用于建立网络整体的统一拓扑数据库。由于网络中所有的路由器都发送LSP,经过一段时间以后,每一个路由器都保持了一张完整的网络拓扑图,再在这个拓扑图上,利用最短通路算法(例如Dijkstra算法等),路由器就可以计算出从任何源点到任何目的地的最佳通路。
这样,每一个路由器都能够利用通路最短的原则建立一个以本路由器为根、分支到所有其他路由器的生成树,依据这个生成树就可以很容易地计算出本路由器的路由表。
算法特征
链路状态路由算法有三个特征:
1.向本自治系统中的所有路由器发送信息。这里使用的方法是洪泛法(Flooding),即路由器通过所有的输出端口向所有的相邻路由器发送信息。而每一个路由器又将此信息发往其所有的相邻的路由器(但不包括刚刚发来信息的那个路由器)。
2.发送的信息就是本路由器相邻的所有路由器的链路状态,但这只是路由器所知道的部分信息。所谓“链路状态”就是说明本路由器和那些路由器相邻,以及该链路的“度量”(Metric)。对于OSPF,链路状态的“度量”主要用来表示费用、距离、时延、带宽等。
3.只有当链路状态发生改变时,路由器才用洪泛法向所有路由器发送此信息。
用途及算法
由于一个路由器的链路状态只涉及与相邻的路由器的联通状态,因而与整个互联网的规模并无直接关系,因此链路状态路由算法可以用于大型的或路由信息变化剧烈的互联网环境。
典型的链路状态路由算法是OSPF算法。
算法的优缺点
优点
(1)与距离向量算法相比,链路状态算法具有更快的收敛速度。由于LSP的发布是面向整个网络,使所有路由器都能够利用LSP来迅速建立整个网络拓扑的一个准确视图。这可以有效防止无限技术问题的出现。其次,链路状态路由算法还具有更小的网络开销。LSP只有在网络拓扑发生变化时才发布,LSP的发布反应的是网络的变化,而不是对整个路由数据库的发布和传输。LSP仅携带与本路由器直接相连的链路,报文长度都很小,且与互联网中的网络数无关,可见链路状态算法更适于大规模互联网。[1]
(2)链路状态算法具有更好的功能扩展能力,很容易地在链路状态中加入新的属性和参数,而无需改变路由交换的规则,是路由计算中能够引用不同的参数来实现新的功能。在链路状态算法中,各路由器使用相同的路由数据库来独立计算路由,而不依赖于其他的路由器,相比距离向量具有更好的防止错误传播的能力。由于LSP在传输过程中不会被其他路由器修改,易于调试。路由器在本地计算路由,也确保了路由算法的收敛性。
(3)路由状态算法还提供了更好的在规模上的可升级性,链路状态算法允许在一个大型网络中划分选路层次。例如,可以将网络中的路由器划分成若干组,在同一组中的路由器之间相互交换LSP,并建立一个该组统一的拓扑数据库。为了在不同的组之间交换拓扑信息,组内的一个特殊路由器的子集首先总结出该组的拓扑数据库,然后将这些总结性的拓扑数据库在一个LSP钟发送给邻近组中的特定路由器。通过这种方式,减少网络中路由信息交换的开销,同时也将组内拓扑结构的变化对其他族中的路由器隐藏起来。分级的概念是在链路状态路由协议(如OSPF)实现过程中的一个十分重要的概念。
下面将具体介绍每一步的细节:
1、发现邻居:
当一个路由器启动时,路由器会找出哪些路由器是它的邻居。实现这个的方法就是在每一条点到点线路上发送一个特殊的HELLO数据包。然后线路的另外一个路由器做出一个答复。
2、设置链路成本:
一种常用的方法就是使成本和链路带宽成反比,越高带宽的成本越低,这样可以使高容量的路径成为路由器更好的选择。如果网络是在地理上分散的,那么可以将延迟作为成本的组成部分,延迟高的成本也高,这样可以找出延迟最低的路径。接下来,是老师为大家随机搭配的一个路由成本!请看下图:

3、构造链路状态包:
状态包中包括了这些内容:发送方的标识符,序号,年龄,邻居列表。
4、分发链路状态包:
路由器将会进行记录,如果是个新的数据包,那么就转发它,如果是个重复的数据包,就丢弃,如果数据报的序号小于当前所看到的最大的序号,那么就当做过时的数据包而拒绝接受。
5、计算新路由:
每条链路可能被表示了两次,每个方向可能不同。也就是说实际情况中,A到B的和B到A的最短路径可能是不同的。这里将要详细介绍下当每个路由器收到了链路状态包之后怎么去计算到网络中其他路由器的最短路径(Dijkstra算法)。下面请看图:
Dijkstra算法是一种迭代算法,它的性质是经过算法的第K次迭代之后,可以知道到K个目的结点的最低费用路径。我们先定义下列符号,目的是为了更好地理解算法的内容:
D(v):到算法的本次迭代,从源节点到目的结点v的最低费用路径的费用
p(v):从源结点到目的结点v的最短路径中倒数第二个结点(也就是v结点之前的结点)
N':结点子集,如果从源节点到某个结点的最低费用路径已经确认,那么这个结点就应该添加到N'中
老师在结尾来总结一下,链路状态路由算法有三个特征:向本自治系统中的所有路由器发送信息;发送的信息就是本路由器相邻的所有路由器的链路状态;只有当链路状态发生改变时,路由器才用洪泛法向所有路由器发送此信息。
还有更多详细知识,尽在编程学习网教育,我们等待您的咨询!









