
这篇文章主要介绍“怎么在Python调试过程中设置不中断的断点”,在日常操作中,相信很多人在怎么在Python调试过程中设置不中断的断点问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么在Python调试过程中设置不中断的断点”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
Python 调试器的心脏:sys.set_trace
在诸多可选的 Python 调试器中,使用最广泛的三个是:
pdb,它是 Python 标准库的一部分
PyDev,它是内嵌在 Eclipse 和 Pycharm 等 IDE 中的调试器
ipdb,它是 IPython 的调试器
Python 调试器的选择虽多,但它们几乎都基于同一个函数:sys.settrace。 值得一提的是, sys.settrace 可能也是 Python 标准库中最复杂的函数。

简单来讲,settrace 的作用是为解释器注册一个跟踪函数,它在下列四种情形发生时被调用:
函数调用
语句执行
函数返回
异常抛出
一个简单的跟踪函数看上去大概是这样:
def simple_tracer(frame, event, arg): co = frame.f_code func_name = co.co_name line_no = frame.f_lineno print("{e} {f} {l}".format(e=event, f=func_name, l=line_no)) return simple_tracer在分析函数时我们首先关注的是参数和返回值,该跟踪函数的参数分别是:
frame,当前堆栈帧,它是包含当前函数执行时解释器里完整状态的对象event,事件,它是一个值可能为call、line、return或exception的字符串arg,参数,它的取值基于event的类型,是一个可选项
该跟踪函数的返回值是它自身,这是由于解释器需要持续跟踪两类跟踪函数:
全局跟踪函数(每线程):该跟踪函数由当前线程调用
sys.settrace来设置,并在解释器创建一个新的堆栈帧时被调用(即代码中发生函数调用时)。虽然没有现成的方式来为不同的线程设置跟踪函数,但你可以调用threading.settrace来为所有新创建的threading模块线程设置跟踪函数。局部跟踪函数(每一帧):解释器将该跟踪函数的值设置为全局跟踪函数创建帧时的返回值。同样也没有现成的方法能够在帧被创建时自动设置局部跟踪函数。
该机制的目的是让调试器对被跟踪的帧有更精确的把握,以减少对性能的影响。
简单三步构建调试器 (我们最初的设想)
仅仅依靠上文提到的内容,用自制的跟踪函数来构建一个真正的调试器似乎有些不切实际。幸运的是,Python 的标准调试器 pdb 是基于 Bdb 构建的,后者是 Python 标准库中专门用于构建调试器的基类。
基于 Bdb 的简易断点调试器看上去是这样的:
import bdbimport inspect class Debugger(bdb.Bdb): def __init__(self): Bdb.__init__(self) self.breakpoints = dict() self.set_trace() def set_breakpoint(self, filename, lineno, method): self.set_break(filename, lineno) try : self.breakpoints[(filename, lineno)].add(method) except KeyError: self.breakpoints[(filename, lineno)] = [method] def user_line(self, frame): if not self.break_here(frame): return # Get filename and lineno from frame (filename, lineno, _, _, _) = inspect.getframeinfo(frame) methods = self.breakpoints[(filename, lineno)] for method in methods: method(frame)这个调试器类的全部构成是:
继承
Bdb,定义一个简单的构造函数来初始化基类,并开始跟踪。添加
set_breakpoint方法,它使用Bdb来设置断点,并跟踪这些断点。重载
Bdb在当前用户行调用的user_line方法,该方法一定被一个断点调用,之后获取该断点的源位置,并调用已注册的断点。
这个简易的 Bdb 调试器效率如何呢?
Rookout 的目标是在生产级性能的使用场景下提供接近普通调试器的使用体验。那么,让我们来看看先前构建出来的简易调试器表现的如何。
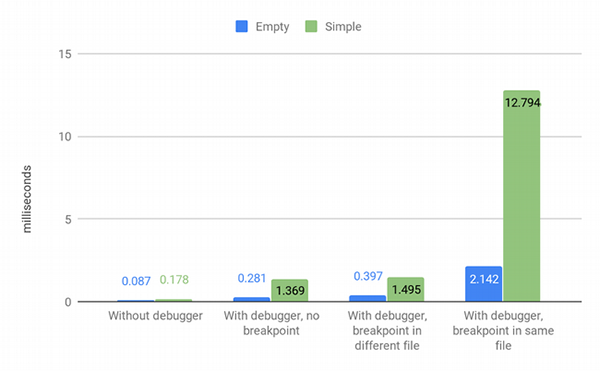
为了衡量调试器的整体性能开销,我们使用如下两个简单的函数来进行测试,它们分别在不同的情景下执行了 1600 万次。请注意,在所有情景下断点都不会被执行。
def empty_method(): pass def simple_method(): a = 1 b = 2 c = 3 d = 4 e = 5 f = 6 g = 7 h = 8 i = 9 j = 10在使用调试器的情况下需要大量的时间才能完成测试。糟糕的结果指明了,这个简陋 Bdb 调试器的性能还远不足以在生产环境中使用。

对调试器进行优化
降低调试器的额外开销主要有三种方法:
尽可能的限制局部跟踪:由于每一行代码都可能包含大量事件,局部跟踪比全局跟踪的开销要大得多。
优化
call事件并尽快将控制权还给解释器:在call事件发生时调试器的主要工作是判断是否需要对该事件进行跟踪。优化
line事件并尽快将控制权还给解释器:在line事件发生时调试器的主要工作是判断我们在此处是否需要设置一个断点。
于是我们复刻了 Bdb 项目,精简特征、简化代码,针对使用场景进行优化。这些工作虽然得到了一些效果,但仍无法满足我们的需求。因此我们又继续进行了其它的尝试,将代码优化并迁移至 .pyx 使用 Cython 进行编译,可惜结果(如下图所示)依旧不够理想。最终,我们在深入了解 CPython 源码之后意识到,让跟踪过程快到满足生产需求是不可能的。
放弃 Bdb 转而尝试字节码操作
熬过先前对标准调试方法进行的试验-失败-再试验循环所带来的失望,我们将目光转向另一种选择:字节码操作。
Python 解释器的工作主要分为两个阶段:
将 Python 源码编译成 Python 字节码:这种(对人类而言)不可读的格式专为执行的效率而优化,它们通常缓存在我们熟知的
.pyc文件当中。遍历 解释器循环中的字节码: 在这一步中解释器会逐条的执行指令。
我们选择的模式是:使用字节码操作来设置没有全局额外开销的不中断断点。这种方式的实现首先需要在内存中的字节码里找到我们感兴趣的部分,然后在该部分的相关机器指令前插入一个函数调用。如此一来,解释器无需任何额外的工作即可实现我们的不中断断点。
这种方法并不依靠魔法来实现,让我们简要地举个例子。
首先定义一个简单的函数:
def multiply(a, b): result = a * b return result在 inspect 模块(其包含了许多实用的单元)的文档里,我们得知可以通过访问 multiply.func_code.co_code 来获取函数的字节码:
'|\x00\x00|\x01\x00\x14}\x02\x00|\x02\x00S'使用 Python 标准库中的 dis 模块可以翻译这些不可读的字符串。调用 dis.dis(multiply.func_code.co_code) 之后,我们就可以得到:
4 0 LOAD_FAST 0 (a) 3 LOAD_FAST 1 (b) 6 BINARY_MULTIPLY 7 STORE_FAST 2 (result) 5 10 LOAD_FAST 2 (result) 13 RETURN_VALUE到此,关于“怎么在Python调试过程中设置不中断的断点”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!









