
今天小编给大家分享一下怎么使用Python3+pycuda实现执行简单GPU计算任务的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
技术背景
GPU的加速技术在深度学习、量子计算领域都已经被广泛的应用。其适用的计算模型是小内存的密集型计算场景,如果计算的模型内存较大,则需要使用到共享内存,这会直接导致巨大的数据交互的运算量,通信开销较大。因为pycuda的出现,也使得我们可以直接在python内直接使用GPU函数,当然也可以直接在python代码中集成一些C++的代码,用于构建GPU计算的函数。
pycuda环境配置
pycuda的安装环境很大程度上取决约显卡驱动本身是否能够安装成功,除了安装pycuda库本身之外,重点是需要确保如下的指令可以运行成功:
[dechin@dechin-manjaro pycuda]$ nvidia-smi
Sun Mar 21 20:26:43 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 455.45.01 Driver Version: 455.45.01 CUDA Version: 11.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce MX250 Off | 00000000:3C:00.0 Off | N/A |
| N/A 48C P0 N/A / N/A | 0MiB / 2002MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
上述返回的结果是一个没有GPU任务情况下的展示界面,包含有显卡型号、显卡内存等信息。如果存在执行的任务,则显示结果如下案例所示:
[dechin@dechin-manjaro pycuda]$ nvidia-smi
Sun Mar 21 20:56:04 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 455.45.01 Driver Version: 455.45.01 CUDA Version: 11.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce MX250 Off | 00000000:3C:00.0 Off | N/A |
| N/A 47C P0 N/A / N/A | 31MiB / 2002MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 18427 C python3 29MiB |
+-----------------------------------------------------------------------------+
我们发现这里多了一个pid为18427的python的进程正在使用GPU进行计算。在运算过程中,如果任务未能够执行成功,有可能在内存中遗留一个进程,这需要我们自己手动去释放。最简单粗暴的方法就是:直接使用kill -9 pid来杀死残留的进程。我们可以使用pycuda自带的函数接口,也可以自己写C++代码来实现GPU计算的相关功能,当然一般情况下更加推荐使用pycuda自带的函数。以下为一部分已经实现的接口函数,比如gpuarray的函数:
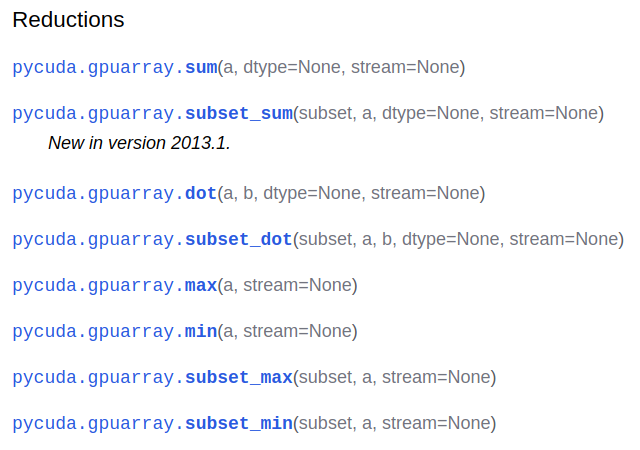
再比如cumath的函数:
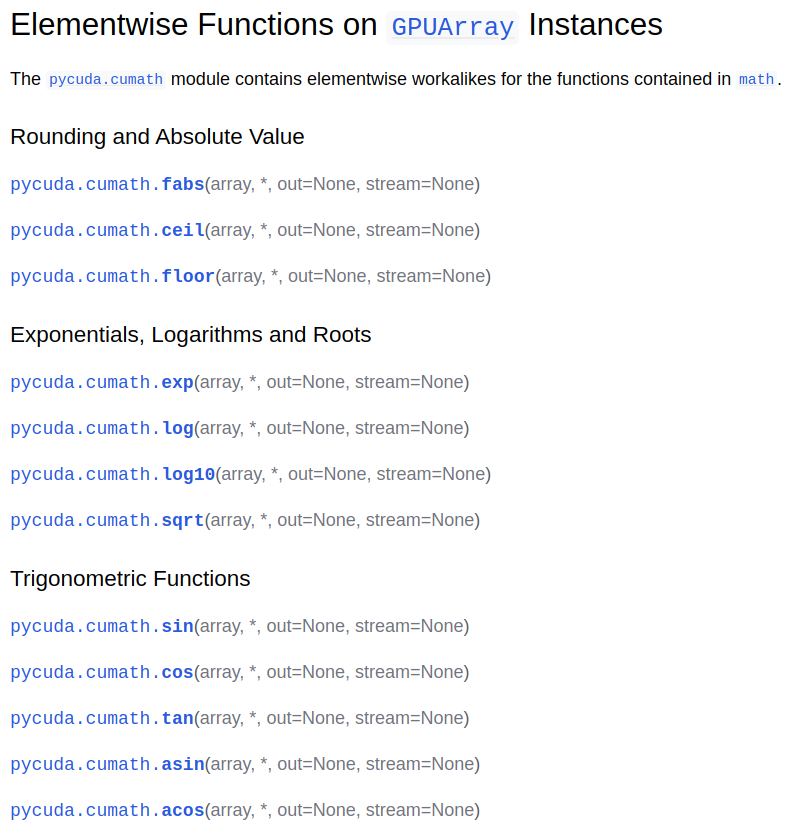
使用GPU计算向量指数
对于一个向量的指数而言,其实就是将每一个的向量元素取指数。当然,这与前面一篇关于量子门操作的博客中介绍的矩阵指数略有区别,这点要注意区分。
在下面的示例中,我们对比了numpy中实现的指数运算和pycuda中实现的指数运算。
# array_exp.py import pycuda.autoinitimport pycuda.gpuarray as gaimport pycuda.cumath as gmimport numpy as npimport sys if sys.argv[1] == '-l': length = int(sys.argv[2]) # 从命令行获取参数值 np.random.seed(1)array = np.random.randn(length).astype(np.float32)array_gpu = ga.to_gpu(array) exp_array = np.exp(array)print (exp_array)exp_array_gpu = gm.exp(array_gpu)gpu_exp_array = exp_array_gpu.get()print (gpu_exp_array)这里面我们计算一个随机向量的指数,向量的维度length是从命令行获取的一个参数,上述代码的执行方式和执行结果如下所示:
[dechin@dechin-manjaro pycuda]$ python3 array_exp.py -l 5
[5.0750957 0.5423974 0.58968204 0.34199178 2.3759744 ]
[5.075096 0.5423974 0.58968204 0.34199178 2.3759747 ]
我们先确保两者计算出来的结果是一致的,这里我们可以观察到,两个计算的结果只保障了7位的有效数字是相等的,这一点在大部分的场景下精度都是有保障的。接下来我们使用timeit来统计和对比两者的性能:
# array_exp.py import pycuda.autoinitimport pycuda.gpuarray as gaimport pycuda.cumath as gmimport numpy as npimport sysimport timeit if sys.argv[1] == '-l': length = int(sys.argv[2]) np.random.seed(1)array = np.random.randn(length).astype(np.float32)array_gpu = ga.to_gpu(array) def npexp(): exp_array = np.exp(array) def gmexp(): exp_array_gpu = gm.exp(array_gpu) # gpu_exp_array = exp_array_gpu.get() if __name__ == '__main__': n = 1000 t1 = timeit.timeit('npexp()', setup='from __main__ import npexp', number=n) print (t1) t2 = timeit.timeit('gmexp()', setup='from __main__ import gmexp', number=n) print (t2)这里也顺便介绍一下timeit的使用方法:这个函数的输入分别是:函数名、函数的导入方式、函数的重复次数。这里需要特别说明的是,如果在函数的导入方式中,不使用__main__函数进行导入,即使是本文件下的python函数,也是无法被导入成功的。在输入的向量达到一定的规模大小时,我们发现在执行时间上相比于numpy有非常大的优势。当然还有一点需要注意的是,由于我们测试的是计算速度,原本使用了get()函数将GPU中计算的结果进行导出,但是这部分其实不应该包含在计算的时间内,因此后来又注释掉了。具体的测试数据如下所示:
[dechin@dechin-manjaro pycuda]$ python3 array_exp.py -l 10000000
26.13127974300005
3.469969915000547
以上就是“怎么使用Python3+pycuda实现执行简单GPU计算任务”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注编程网行业资讯频道。







