
这篇文章主要介绍“Python怎么实现RGB等图片的图像插值算法”,在日常操作中,相信很多人在Python怎么实现RGB等图片的图像插值算法问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python怎么实现RGB等图片的图像插值算法”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
RGB彩色图像和数组理解
对于这个图片读取到数组中形成的三维数组,我刚理解了很久,在网上找大佬的资料自己看等等,然后慢慢的才形成了自己的理解,大佬们都是纵说纷纭,自己走了很多弯路,这里吧我的理解写下来,第一,方便自以后学习查看;第二,方便和我一样的初学者理解。
先话不多说,直接上一个图:
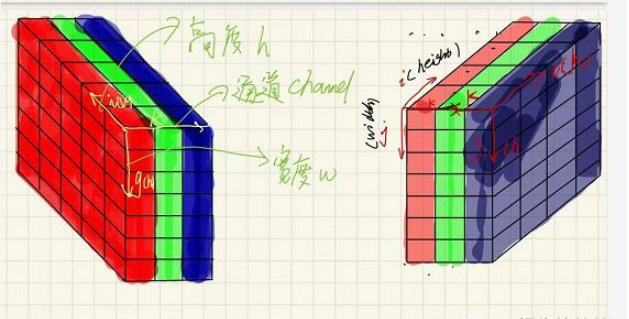
这里我直接把彩色图片的三个通道数画成了三位图片显示出来方面自己理解。彩色图片是三通道的,分别为R、G、B,这三个通道的重叠,通过调节每个通道数灰度值的亮度,从而构成了五颜六色的彩色世界!!
红色区域为第0通道(R),以此类推,第1通道(G)、第2通道(B)。读取回来的数组是一个三维数组,这个三维数组又分为了很多二维矩阵,每个二维矩阵有三个列(三个通道)。上图中有多少个i(高h),就表示三维数组中有多少个二维数组,有多少个j(宽h),就表示二维数组有多少个行,通道数k表示通道数,彩色图像有三个通道,所以 k 是个固定值 3。
数组中的值怎么理解欸?
下面插入我这个灵魂画师的一张图示来说明吧哈哈哈哈哈哈(不禁默默的流下了眼泪)
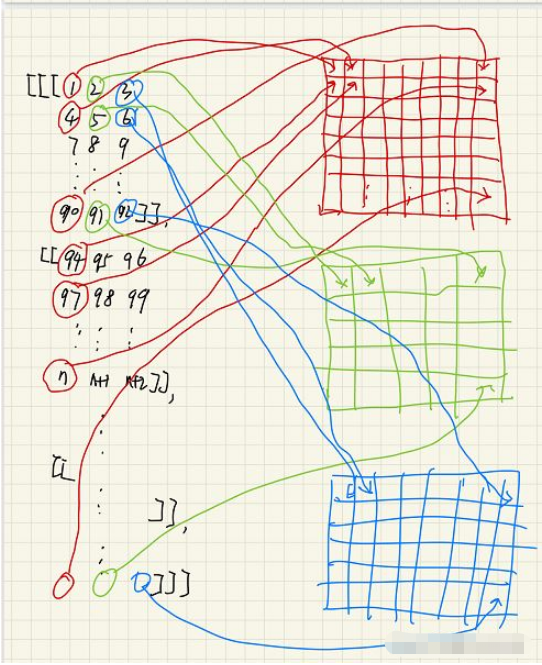
上图中左边给出了一个图片读入到数组(假设)中的样子,不同颜色的线条表示组成的不同通道图片,然后再把这三个通道里面的图片按照上上图片一样堆叠起来,就构成了这个三维空间图了。
RGB图像的理解就说到这里吧,希望能帮助到和我一样的初学者少走弯路。
图片坐标对其
要问这公式怎么来的,第一个可以根据放大后像素点的位置成比例算出来,第二个公式暂时还没想出来咋个算出来的,要是有大佬给我指出来就好了。
在代码中有传入参数指定使用哪一种对齐方式align = left,该参数默认是居中对其center。
左对齐
src_X = dst_X*(src_Width/dst_Width)src_Y = dst_Y*(src_Height/dst_Height)这里的src_X 就是目标图像上的点映射到原图像上的x坐标点,同理src_Y 就是映射到原图像上的y坐标点。
dst_X表示目标图像的x坐标,dst_Y表示目标图像的y坐标。
中心对齐
src_X = (dst_X+0.5)*(src_Width/dst_Width) - 0.5src_Y = (dst_Y+0.5)*(src_Height/dst_Height) - 0.5这里的src_X 就是目标图像上的点映射到原图像上的x坐标点,同理src_Y 就是映射到原图像上的y坐 标点。
dst_X表示目标图像的x坐标,dst_Y表示目标图像的y坐标。
临近插值算法
最邻近插值算法是最简单的,我们算出来的坐标点:i ,j,使用round函数对其进行四舍五入,就可以得到img[i,j]这个像素点的临近值了(是一个像素值)。
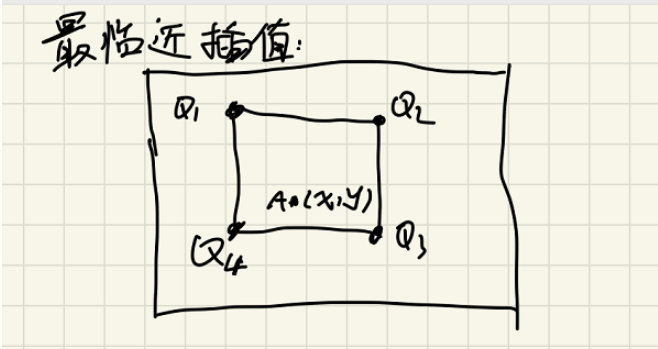
这个图片中就能看出,A点是目标图像映射到原图像上面的位置,整个背景是原图像,图中的Q1、Q2、Q3、Q4四个点就是A点的最邻近的四个像素点。
最邻近插值算法的代码是最简单的,但是放大后的图片效果是最差的,下面看代码实现:
def nearest_inter(self): """最邻近插值法""" new_img = np.zeros((self.goal_h, self.goal_w, self.goal_channel), dtype=np.uint8) for i in range(0, new_img.shape[0]): for j in range(0, new_img.shape[1]): src_i, src_j = self.convert2src_axes(i, j) new_img[i, j] = self.img[round(src_i), round(src_j)] return new_img线性插值法
线性插值公式说白了就是,咱们数学中的直线的参数方程形式。我们知道两点可以确定一条直线,但是在确定好的这条直线中我们怎么确定直线中的某个点呢,这样我们就可以根据两条平行线之间的关系来建立该两点确定的直线方程。看下面的图

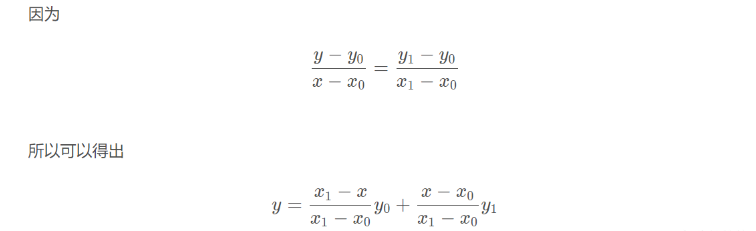
所以这样就能得该直线方程了。
这里给出线性插值算法的代码:
def linear_inter(self): """线性插值算法""" new_img = np.zeros((self.goal_h, self.goal_w, self.goal_channel), dtype=np.uint8) for i in range(0, new_img.shape[0]): for j in range(0, new_img.shape[1]): src_i, src_j = self.convert2src_axes(i, j) if ((src_j - int(src_j)) == 0 and (src_i - int(src_i)) == 0) \ or ((src_i - int(src_i)) == 0) \ or ( (src_j - int(src_j)) == 0): # 表明border_src_j是一个整数 如果是整数,直接将原图的灰度值付给目标图像即可 new_img[i, j] = self.img[round(src_i), round(src_j)] # 直接将原图的灰度值赋值给目标图像即可 else: """否则进行向上和向下取整,然后进行(一维)线性插值算法""" src_i, src_j = self.convert2src_axes(i, j) j1 = int(src_j) # 向下取整 j2 = math.ceil(src_j) # 向上取整 new_img[i, j] = (j2 - src_j)*self.img[round(src_i), j1] + (src_j-j1)*self.img[round(src_i), j2] return new_img双线性插值
双线性插值算法实现起来就比线性插值算法要难一些,本质上还是和线性插值算法一样,都是为了去找更目标图像映射到原图像上的点,把这个点周围尽像素尽可能多的信息传递到这个点中。线性插值使用到了周围的两个点,这里的双线性就是使用到了周围的四个点的像素值信息,所以理论上来说,采用双线线性插值算法的效果会明显优于线性插值算法(单线性插值算法)。更具体的图示我这里就不画出来了,就使用我自己手绘的简化版(因为懒),网上其他帖子讲得更加明白,这里只贴出我自己的理解,这样以后来看的时候也能一目了然。
图中的x就是图片的高h,y就是图片的宽度w,因为我们读出来的图片是彩色图片,所以这样操作的同时,图片的三个通道也会同步更新这样的操作。
下面给出双线性插值算法的python代码:
def double_linear_inter(self): new_img = np.zeros((self.goal_h-2, self.goal_w-2, self.goal_channel), dtype=np.uint8) # 这里减的目的就是为了可以进行向上向下取整 for i in range(0, new_img.shape[0]): # 减1的目的就是为了可以进行向上向下取整数 for j in range(0, new_img.shape[1]): inner_src_i, inner_src_j = self.convert2src_axes(i, j) # 将取得到的变量参数坐标映射到原图中,并且返回映射到原图中的坐标 inner_i1 = int(inner_src_i) # 对行进行向上向下取整数 inner_i2 = math.ceil(inner_src_i) inner_j1 = int(inner_src_j) # 对列进行向上向下取整数 inner_j2 = math.ceil(inner_src_j) Q1 = (inner_j2 - inner_src_j) * self.img[inner_i1, inner_j1] + \ (inner_src_j - inner_j1) * self.img[inner_i1, inner_j2] Q2 = (inner_j2 - inner_src_j) * self.img[inner_i2, inner_j1] + \ (inner_src_j - inner_j1) * self.img[inner_i2, inner_j2] new_img[i, j] = (inner_i2 - inner_src_i) * Q1 + (inner_src_i - inner_i1) * Q2 return new_img三种插值算法的综合使用
在进行图片处理的时候,对于图片的四个角,没有四个或者两个邻域,所以四个角就采用最邻近插值算法实现,二上下,左右这几行,没有四个邻域,所以采用线性插值算法,其余中心部分每个点都有四个邻域,所以采用双线性插值算法来实现,这样的图片效果会更好,以下是这三种算法的具体实现:
def all_transform(self): # source_h, source_w, source_channel = self.img.shape # 获得原图像的高度,宽度和通道量 # goal_h, goal_w = round(source_h*self.h_rate), round(source_w*self.w_rate) # 将原图像的size进行按照传入进来的rate参数等比的放大 # goal_channel = source_channel """进行图像转换了""" new_img = np.zeros((self.goal_h-1, self.goal_w-1, self.goal_channel), dtype=np.uint8) # 得到一个空的数组用来存放转换后的值,即为新的图片 """边界使用线性插值算法""" temp_row = [0, new_img.shape[0]-1] # 上下两行进行线性插值 for i in temp_row: # i -> h -> x # j -> w -> y for j in range(0, new_img.shape[1]): """边界线(除了四个角落)采用线性插值法""" t_border_src_i, t_border_src_j = self.convert2src_axes(i, j) if ((t_border_src_j - int(t_border_src_j)) == 0 and (t_border_src_i - int(t_border_src_i)) == 0) \ or (t_border_src_i - int(t_border_src_i)) == 0 \ or (t_border_src_j - int(t_border_src_j)) == 0: # 表明t_border_src_j是一个整数 如果是整数,直接将原图的灰度值付给目标图像即可 new_img[i, j] = self.img[round(t_border_src_i), round(t_border_src_j)] # 直接将原图的灰度值赋值给目标图像即可 else: """否则进行向上和向下取整,然后进行(一维)线性插值算法""" t_border_src_i, t_border_src_j = self.convert2src_axes(i, j) j1 = int(t_border_src_j) # 向下取整 j2 = math.ceil(t_border_src_j) # 向上取整 new_img[i, j] = self.img[round(t_border_src_i), j1] + (t_border_src_j - j1) * \ (self.img[round(t_border_src_i), j2] - self.img[round(t_border_src_i), j1]) # 左右两列进行线性插值 temp_col = [0, new_img.shape[1]-1] for i in temp_col: # i -> w -> y # j -> h -> x for j in range(0, new_img.shape[0]): """边界线(除了四个角落)采用线性插值法""" t_border_src_i, t_border_src_j = self.convert2src_axes(i, j) if ((t_border_src_j - int(t_border_src_j)) == 0 and (t_border_src_i - int(t_border_src_i)) == 0) \ or (t_border_src_i - int(t_border_src_i)) == 0 \ or (t_border_src_j - int(t_border_src_j)) == 0: # 表明border_src_j是一个整数 如果是整数,直接将原图的灰度值付给目标图像即可 new_img[j, i] = self.img[round(t_border_src_i), round(t_border_src_j)] # 直接将原图的灰度值赋值给目标图像即可 else: """否则进行向上和向下取整,然后进行(一维)线性插值算法""" t_border_src_i, t_border_src_j = self.convert2src_axes(j, i) j1 = int(t_border_src_i) # 向下取整 j2 = math.ceil(t_border_src_i) # 向上取整 new_img[j, i] = self.img[j1, round(t_border_src_j)] + (t_border_src_i - j1) * \ (self.img[j2, round(t_border_src_j)] - self.img[j1, round(t_border_src_j)]) """四个角落(顶点)使用最临近插值算法""" corner_low = [0, new_img.shape[0]-1] corner_height = [0, new_img.shape[1]-1] for i in corner_low: for j in corner_height: src_i, src_j = self.convert2src_axes(i, j) new_img[i, j] = self.img[round(src_i), round(src_j)] """中间的使用双线性插值法""" for i in range(1, new_img.shape[0] - 1): # 减1的目的就是为了可以进行向上向下取整数 for j in range(1, new_img.shape[1] - 1): inner_src_i, inner_src_j = self.convert2src_axes(i, j) # 将取得到的变量参数坐标映射到原图中,并且返回映射到原图中的坐标 inner_i1 = int(inner_src_i) # 对行进行向上向下取整数 inner_i2 = math.ceil(inner_src_i) inner_j1 = int(inner_src_j) # 对列进行向上向下取整数 inner_j2 = math.ceil(inner_src_j) Q1 = (inner_j2 - inner_src_j) * self.img[inner_i1, inner_j1] + \ (inner_src_j - inner_j1) * self.img[inner_i1, inner_j2] Q2 = (inner_j2 - inner_src_j) * self.img[inner_i2, inner_j1] + \ (inner_src_j - inner_j1) * self.img[inner_i2, inner_j2] new_img[i, j] = (inner_i2 - inner_src_i) * Q1 + (inner_src_i - inner_i1) * Q2 return new_img附件
下面附上我这个插值算法所有的代码
import numpy as npimport cv2import mathimport loggingclass Image_inter_lines(object): """设置传入参数""" def __init__(self, img, modify_size=(3, 3), *, align='center'): self.img = img self.h_rate = modify_size[0] # 高度的缩放率 self.w_rate = modify_size[1] # 宽度的缩放率 self.align = align # 设置居中模式,进而进行判断其对齐方式 self.source_h = img.shape[0] # 对应 i 列 -> x self.source_w = img.shape[1] # 对饮 j 列 -> y self.goal_channel = img.shape[2] # 通道数 self.goal_h = round(self.source_h * self.h_rate) # 将原图像的size进行按照传入进来的rate参数等比的放大 self.goal_w = round(self.source_w * self.w_rate) if self.align not in ['center', 'left']: logging.exception(f'{self.align} is not a valid align parameter') self.align = 'center' # 如果传入的参数不是居中或者居左,则强制将其置为居中 pass def set_rate(self, new_modify_size=(None, None)): self.h_rate = new_modify_size[0] self.w_rate = new_modify_size[1] def convert2src_axes(self, des_x, des_y): if self.align == 'left': # 左对齐 src_x = float(des_x * (self.source_w / self.goal_w)) src_y = float(des_y * (self.source_h / self.goal_h)) src_x = min((self.source_h - 1), src_x) src_y = min((self.source_w - 1), src_y) else: # 几何中心对齐 src_x = float(des_x * (self.source_w / self.goal_w) + 0.5 * (self.source_w / self.goal_w)) src_y = float(des_y * (self.source_h / self.goal_h) + 0.5 * (self.source_h / self.goal_h)) src_x = min((self.source_h - 1), src_x) src_y = min((self.source_w - 1), src_y) return src_x, src_y # 这里返回的数值可以是小数,也可能是整数例如:23.00,但是这个数仍然是小数 def nearest_inter(self): """最邻近插值法""" new_img = np.zeros((self.goal_h, self.goal_w, self.goal_channel), dtype=np.uint8) for i in range(0, new_img.shape[0]): for j in range(0, new_img.shape[1]): src_i, src_j = self.convert2src_axes(i, j) new_img[i, j] = self.img[round(src_i), round(src_j)] return new_img def linear_inter(self): """线性插值算法""" new_img = np.zeros((self.goal_h, self.goal_w, self.goal_channel), dtype=np.uint8) for i in range(0, new_img.shape[0]): for j in range(0, new_img.shape[1]): src_i, src_j = self.convert2src_axes(i, j) if ((src_j - int(src_j)) == 0 and (src_i - int(src_i)) == 0) \ or ((src_i - int(src_i)) == 0) \ or ( (src_j - int(src_j)) == 0): # 表明t_border_src_j是一个整数 如果是整数,直接将原图的灰度值付给目标图像即可 new_img[i, j] = self.img[round(src_i), round(src_j)] # 直接将原图的灰度值赋值给目标图像即可 else: """否则进行向上和向下取整,然后进行(一维)线性插值算法""" src_i, src_j = self.convert2src_axes(i, j) j1 = int(src_j) # 向下取整 j2 = math.ceil(src_j) # 向上取整 new_img[i, j] = (j2 - src_j)*self.img[round(src_i), j1] + (src_j-j1)*self.img[round(src_i), j2] return new_img def double_linear_inter(self): new_img = np.zeros((self.goal_h-2, self.goal_w-2, self.goal_channel), dtype=np.uint8) # 这里减的目的就是为了可以进行向上向下取整 for i in range(0, new_img.shape[0]): # 减1的目的就是为了可以进行向上向下取整数 for j in range(0, new_img.shape[1]): inner_src_i, inner_src_j = self.convert2src_axes(i, j) # 将取得到的变量参数坐标映射到原图中,并且返回映射到原图中的坐标 inner_i1 = int(inner_src_i) # 对行进行向上向下取整数 inner_i2 = math.ceil(inner_src_i) inner_j1 = int(inner_src_j) # 对列进行向上向下取整数 inner_j2 = math.ceil(inner_src_j) Q1 = (inner_j2 - inner_src_j) * self.img[inner_i1, inner_j1] + \ (inner_src_j - inner_j1) * self.img[inner_i1, inner_j2] Q2 = (inner_j2 - inner_src_j) * self.img[inner_i2, inner_j1] + \ (inner_src_j - inner_j1) * self.img[inner_i2, inner_j2] new_img[i, j] = (inner_i2 - inner_src_i) * Q1 + (inner_src_i - inner_i1) * Q2 return new_img def all_transform(self): # source_h, source_w, source_channel = self.img.shape # 获得原图像的高度,宽度和通道量 # goal_h, goal_w = round(source_h*self.h_rate), round(source_w*self.w_rate) # 将原图像的size进行按照传入进来的rate参数等比的放大 # goal_channel = source_channel """进行图像转换了""" new_img = np.zeros((self.goal_h-1, self.goal_w-1, self.goal_channel), dtype=np.uint8) # 得到一个空的数组用来存放转换后的值,即为新的图片 """边界使用线性插值算法""" temp_row = [0, new_img.shape[0]-1] # 上下两行进行线性插值 for i in temp_row: # i -> h -> x # j -> w -> y for j in range(0, new_img.shape[1]): """边界线(除了四个角落)采用线性插值法""" t_border_src_i, t_border_src_j = self.convert2src_axes(i, j) if ((t_border_src_j - int(t_border_src_j)) == 0 and (t_border_src_i - int(t_border_src_i)) == 0) \ or (t_border_src_i - int(t_border_src_i)) == 0 \ or (t_border_src_j - int(t_border_src_j)) == 0: # 表明t_border_src_j是一个整数 如果是整数,直接将原图的灰度值付给目标图像即可 new_img[i, j] = self.img[round(t_border_src_i), round(t_border_src_j)] # 直接将原图的灰度值赋值给目标图像即可 else: """否则进行向上和向下取整,然后进行(一维)线性插值算法""" t_border_src_i, t_border_src_j = self.convert2src_axes(i, j) j1 = int(t_border_src_j) # 向下取整 j2 = math.ceil(t_border_src_j) # 向上取整 new_img[i, j] = self.img[round(t_border_src_i), j1] + (t_border_src_j - j1) * \ (self.img[round(t_border_src_i), j2] - self.img[round(t_border_src_i), j1]) # 左右两列进行线性插值 temp_col = [0, new_img.shape[1]-1] for i in temp_col: # i -> w -> y # j -> h -> x for j in range(0, new_img.shape[0]): """边界线(除了四个角落)采用线性插值法""" t_border_src_i, t_border_src_j = self.convert2src_axes(i, j) if ((t_border_src_j - int(t_border_src_j)) == 0 and (t_border_src_i - int(t_border_src_i)) == 0) \ or (t_border_src_i - int(t_border_src_i)) == 0 \ or (t_border_src_j - int(t_border_src_j)) == 0: # 表明border_src_j是一个整数 如果是整数,直接将原图的灰度值付给目标图像即可 new_img[j, i] = self.img[round(t_border_src_i), round(t_border_src_j)] # 直接将原图的灰度值赋值给目标图像即可 else: """否则进行向上和向下取整,然后进行(一维)线性插值算法""" t_border_src_i, t_border_src_j = self.convert2src_axes(j, i) j1 = int(t_border_src_i) # 向下取整 j2 = math.ceil(t_border_src_i) # 向上取整 new_img[j, i] = self.img[j1, round(t_border_src_j)] + (t_border_src_i - j1) * \ (self.img[j2, round(t_border_src_j)] - self.img[j1, round(t_border_src_j)]) """四个角落(顶点)使用最临近插值算法""" corner_low = [0, new_img.shape[0]-1] corner_height = [0, new_img.shape[1]-1] for i in corner_low: for j in corner_height: src_i, src_j = self.convert2src_axes(i, j) new_img[i, j] = self.img[round(src_i), round(src_j)] """中间的使用双线性插值法""" for i in range(1, new_img.shape[0] - 1): # 减1的目的就是为了可以进行向上向下取整数 for j in range(1, new_img.shape[1] - 1): inner_src_i, inner_src_j = self.convert2src_axes(i, j) # 将取得到的变量参数坐标映射到原图中,并且返回映射到原图中的坐标 inner_i1 = int(inner_src_i) # 对行进行向上向下取整数 inner_i2 = math.ceil(inner_src_i) inner_j1 = int(inner_src_j) # 对列进行向上向下取整数 inner_j2 = math.ceil(inner_src_j) Q1 = (inner_j2 - inner_src_j) * self.img[inner_i1, inner_j1] + \ (inner_src_j - inner_j1) * self.img[inner_i1, inner_j2] Q2 = (inner_j2 - inner_src_j) * self.img[inner_i2, inner_j1] + \ (inner_src_j - inner_j1) * self.img[inner_i2, inner_j2] new_img[i, j] = (inner_i2 - inner_src_i) * Q1 + (inner_src_i - inner_i1) * Q2 return new_imgif __name__ == '__main__': pic1 = cv2.imread(r'C:\Users\heshijie\Desktop\Py_study\image processing\Carmen.jpg') pic2 = cv2.imread(r'C:\Users\heshijie\Desktop\Py_study\image processing\girl.jpg') pic3 = cv2.imread(r'C:\Users\heshijie\Desktop\Py_study\image processing\architecture.jpg') Obj_pic1 = Image_inter_lines(pic1, modify_size=(2, 2), align='center') new_pic1 = Obj_pic1.nearest_inter() cv2.imshow('origin', pic1) cv2.imshow('nearest_inter', new_pic1) new_pic2 = Obj_pic1.linear_inter() cv2.imshow('liner_inter', new_pic2) new_pic3 = Obj_pic1.all_transform() cv2.imshow('double_liner_inter', new_pic3) cv2.waitKey()到此,关于“Python怎么实现RGB等图片的图像插值算法”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!








