
这篇文章主要介绍“怎么理解Python中的垃圾回收”,在日常操作中,相信很多人在怎么理解Python中的垃圾回收问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么理解Python中的垃圾回收”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
前言
对于python来说,一切皆为对象,所有的变量赋值都遵循着对象引用机制。程序在运行的时候,需要在内存中开辟出一块空间,用于存放运行时产生的临时变量;计算完成后,再将结果输出到永久性存储器中。如果数据量过大,内存空间管理不善就很容易出现 OOM(out of memory),俗称爆内存,程序可能被操作系统中止。而对于服务器,内存管理则显得更为重要,不然很容易引发内存泄漏- 这里的泄漏,并不是说你的内存出现了信息安全问题,被恶意程序利用了,而是指程序本身没有设计好,导致程序未能释放已不再使用的内存。- 内存泄漏也不是指你的内存在物理上消失了,而是意味着代码在分配了某段内存后,因为设计错误,失去了对这段内存的控制,从而造成了内存的浪费。也就是这块内存脱离了gc的控制。
计数引用
因为python中一切皆为对象,你所看到的一切变量,本质上都是对象的一个指针。当一个对象不再调用的时候,也就是当这个对象的引用计数(指针数)为 0 的时候,说明这个对象永不可达,自然它也就成为了垃圾,需要被回收。可以简单的理解为没有任何变量再指向它。
import os import psutil # 显示当前 python 程序占用的内存大小 def show_memory_info(hint): pid = os.getpid() p = psutil.Process(pid) info = p.memory_full_info() memory = info.uss / 1024./ 1024 print( {} memory used: {} MB .format(hint, memory))可以看到调用函数 func(),在列表 a 被创建之后,内存占用迅速增加到了 433 MB:而在函数调用结束后,内存则返回正常。这是因为,函数内部声明的列表 a 是局部变量,在函数返回后,局部变量的引用会注销掉;此时,列表 a 所指代对象的引用数为 0,Python 便会执行垃圾回收,因此之前占用的大量内存就又回来了。
def func(): show_memory_info( initial ) global a a = [i for i in range( 10000000 )] show_memory_info( after a created ) func() show_memory_info( finished ) ########## 输出 ########## initial memory used: 48.88671875 MB after a created memory used:433.94921875 MB finished memory used:433.94921875 MB新的这段代码中,global a 表示将 a 声明为全局变量。那么,即使函数返回后,列表的引用依然存在,于是对象就不会被垃圾回收掉,依然占用大量内存。同样,如果我们把生成的列表返回,然后在主程序中接收,那么引用依然存在,垃圾回收就不会被触发,大量内存仍然被占用着:
def func(): show_memory_info( initial ) a = [i for i in derange( 10000000 )] show_memory_info( after a created ) return a a = func() show_memory_info( finished) ########## 输出 ########## initial memory used: 47.96484375 MB after a created memory used:434.515625 MB finished memory used: 434.515625 MB那怎么可以看到变量被引用了多少次呢?通过 sys.getrefcount。
import sys a = [] # 两次引用,一次来自 a,一次来自 getrefcount print (sys.getrefcount(a)) def func(a): # 四次引用,a,python 的函数调用栈,函数参数,和 getrefcount print (sys.getrefcount(a)) func(a) # 两次引用,一次来自 a,一次来自 getrefcount,函数 func 调用已经不存在 print (sys.getrefcount(a)) ########## 输出 ########## 2 4 2如果其中涉及函数调用,会额外增加两次1. 函数栈2. 函数调用。
从这里就可以看到python不再需要像C那种的认为的释放内存,但是python同样给我们提供了手动释放内存的方法 gc.collect()。
import gc show_memory_info( initial) a = [i for i in range( 10000000 )] show_memory_info( after a created) del a gc.collect() show_memory_info( finish ) print (a) ########## 输出 ########## initial memory used: 48.1015625 MB after a created memory used: 434.3828125 MB finish memory used: 48.33203125 MB --------------------------------------------------------------------------- NameErrorTraceback (most recent call last) <ipython-input- 12 - 153e15063d8a > in<module> 11 12 show_memory_info( finish ) ---> 13 print (a) NameError : name a isnotdefined截止目前,貌似python的垃圾回收机制非常的简单,只要对象引用次数为0,必定为触发gc,那么引用次数为0是否是触发gc的充要条件呢?
循环回收
如果有两个对象,它们互相引用,并且不再被别的对象所引用,那么它们应该被垃圾回收吗?
def func(): show_memory_info( initial ) a = [i for i in range(10000000)] b = [i for i in range(10000000)] show_memory_info( after a, b created ) a.append(b) b.append(a) func() show_memory_info( finished ) ########## 输出 ########## initial memory used: 47.984375 MB after a, b created memory used:822.73828125 MB finished memory used: 821.73046875 MB从结果显而易见,它们并没有被回收,但是从程序上来看,当这个函数结束的时候,作为局部变量的a,b就已经从程序意义上不存在了。但是因为它们的互相引用,导致了它们的引用数都不为0。这时要如何规避呢1. 从代码逻辑上进行整改,避免这种循环引用2. 通过人工回收。
import gc def func(): show_memory_info( initial) a = [i for i in range(10000000)] b = [i for i in range(10000000)] show_memory_info( after a, b created) a.append(b) b.append(a) func() gc.collect() show_memory_info( finished ) ########## 输出 ########## initial memory used:49.51171875 MB after a, b created memory used: 824.1328125 MB finished memory used:49.98046875 MBpython针对循环引用,有它的自动垃圾回收算法1. 标记清除(mark-sweep)算法2. 分代收集(generational)。
标记清除
标记清除的步骤总结为如下步骤1. GC会把所有的『活动对象』打上标记2. 把那些没有标记的对象『非活动对象』进行回收那么python如何判断何为非活动对象?通过用图论来理解不可达的概念。对于一个有向图,如果从一个节点出发进行遍历,并标记其经过的所有节点;那么,在遍历结束后,所有没有被标记的节点,我们就称之为不可达节点。显而易见,这些节点的存在是没有任何意义的,自然的,我们就需要对它们进行垃圾回收。但是每次都遍历全图,对于 Python 而言是一种巨大的性能浪费。所以,在 Python 的垃圾回收实现中,mark-sweep 使用双向链表维护了一个数据结构,并且只考虑容器类的对象(只有容器类对象,list、dict、tuple,instance,才有可能产生循环引用)。
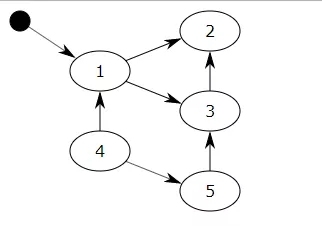
图中把小黑圈视为全局变量,也就是把它作为root object,从小黑圈出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
分代回收
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时(当垃圾回收器中新增对象减去删除对象达到相应的阈值时),Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。事实上,分代回收基于的思想是,新生的对象更有可能被垃圾回收,而存活更久的对象也有更高的概率继续存活。因此,通过这种做法,可以节约不少计算量,从而提高 Python 的性能。所以对于刚刚的问题,引用计数只是触发gc的一个充分非必要条件,循环引用同样也会触发。
调试
可以使用 objgraph来调试程序,因为目前它的官方文档,还没有细读,只能把文档放在这供大家参阅啦~其中两个函数非常有用 1. show_refs() 2. show_backrefs()。
到此,关于“怎么理解Python中的垃圾回收”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!









