
本文章向大家介绍python中Scrapy爬虫框架的作用有哪些,主要包括python中Scrapy爬虫框架的作用有哪些的使用实例、应用技巧、基本知识点总结和需要注意事项,具有一定的参考价值,需要的朋友可以参考一下。
python可以做什么
Python是一种编程语言,内置了许多有效的工具,Python几乎无所不能,该语言通俗易懂、容易入门、功能强大,在许多领域中都有广泛的应用,例如最热门的大数据分析,人工智能,Web开发等。
Scrapy是什么?
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
Scrapy是一个非常好用的爬虫框架,它不仅提供了一些开箱即用的基础组件,还提供了强大的自定义功能。
# Scrapy 安装
Scrapy 官网:https://scrapy.org/
各位同学的电脑环境应该和小编的相差不远(如果是使用 win10 的话) 安装过程需要10分钟左右
安装命令:
pip install scrapy由于 Scrapy 依赖了大量的第三方的包,所以在执行上面的命令后并不会马上就下载 Scrapy ,而是会先不断的下载第三方包,包括并不限于以下几种:
pyOpenSSL:Python 用于支持 SSL(Security Socket Layer)的包。
cryptography:Python 用于加密的库。
CFFI:Python 用于调用 C 的接口库。
zope.interface:为 Python 缺少接口而提供扩展的库。
lxml:一个处理 XML、HTML 文档的库,比 Python 内置的 xml 模块更好用。
cssselect:Python 用于处理 CSS 选择器的扩展包。
Twisted:为 Python 提供的基于事件驱动的网络引擎包。
……
如果安装不成功多试两次 或者 执行pip install --upgrade pip 后再执行 pip install scrapy
等待命令执行完成后,直接输入 scrapy 进行验证。
C:\Users\Administrator>scrapyScrapy 2.4.0 - no active projectAvailable commands:bench Run quick benchmark test...版本号可能会有差别,不用太在意
如果能正常出现以上内容,说明我们已经安装成功了。
理论上 Scrapy 安装出现各种问题才算正常情况
三、Scrapy创建项目
Scrapy 提供了一个命令来创建项目 scrapy 命令,在命令行上运行:
scrapy startproject jianshu我们创建一个项目jianshu用来爬取简书首页热门文章的所有信息。
jianshu/ scrapy.cfg jianshu/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py ...spiders文件夹下就是你要实现爬虫功能(具体如何爬取数据的代码),爬虫的核心。在spiders文件夹下自己创建一个spider,用于爬取简书首页热门文章。
scrapy.cfg是项目的配置文件。
settings.py用于设置请求的参数,使用代理,爬取数据后文件保存等。
items.py 自己预计需要爬取的内容
middlewares.py自定义中间件的文件
pipelines.py 管道,保持数据
项目的目录就用网图来展示一下吧
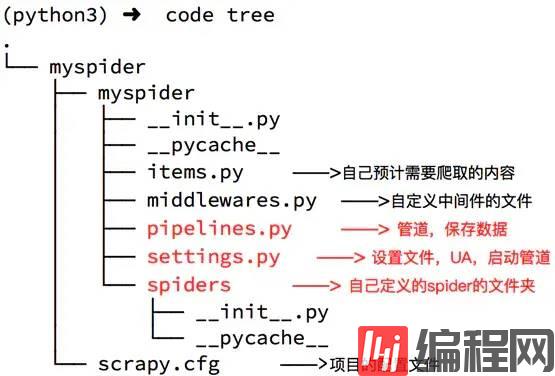
image Scrapy爬取简书首页热门文章
cd到Jianshu项目中,生成一个爬虫:
scrapy genspider jianshublog www.jianshu.com这种方式生成的是常规爬虫
1)新建jianshuSpider
import scrapyclass JianshublogSpider(scrapy.Spider): name = 'jianshublog' allowed_domains = ['www.jianshu.com'] start_urls = ['http://www.jianshu.com/'] def parse(self, response): pass可以看到,这个类里面有三个属性 name 、 allowed_domains 、 start_urls 和一个parse()方法。
name,它是每个项目唯一的名字,用来区分不同的 Spider。
allowed_domains,它是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉。start_urls,它包含了 Spider 在启动时爬取的 url 列表,初始请求是由它来定义的。
parse,它是 Spider 的一个方法。默认情况下,被调用时 start_urls 里面的链接构成的请求完成下载执行后,返回的响应就会作为唯一的参数传递给这个函数。该方法负责解析返回的响应、提取数据或者进一步生成要处理的请求。
到这里我们就清楚了,parse() 方法中的 response 是前面的 start_urls中链接的爬取结果,所以在 parse() 方法中,我们可以直接对爬取的结果进行解析。
修改USER_AGENT
打开settings.py 添加 UA 头信息
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36'修改`parse`方法解析网页
我们打开简书首页 右键检查(ctrl+shift+I)发现所有的博客头条都放在类名.note-list .content 的div 节点里面
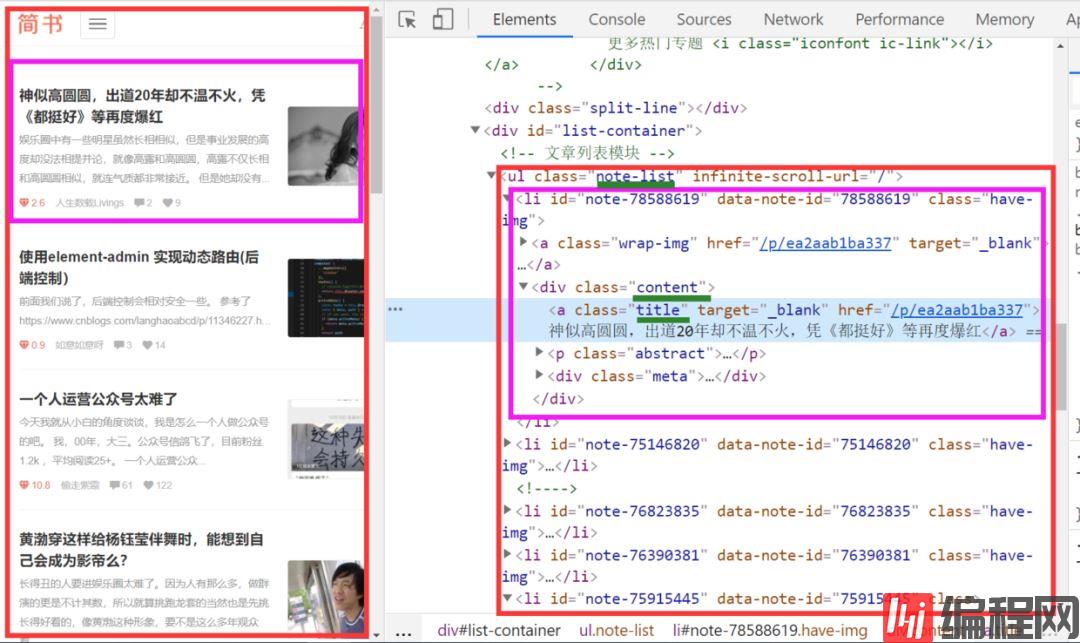
修改jianshublog.py代码如下
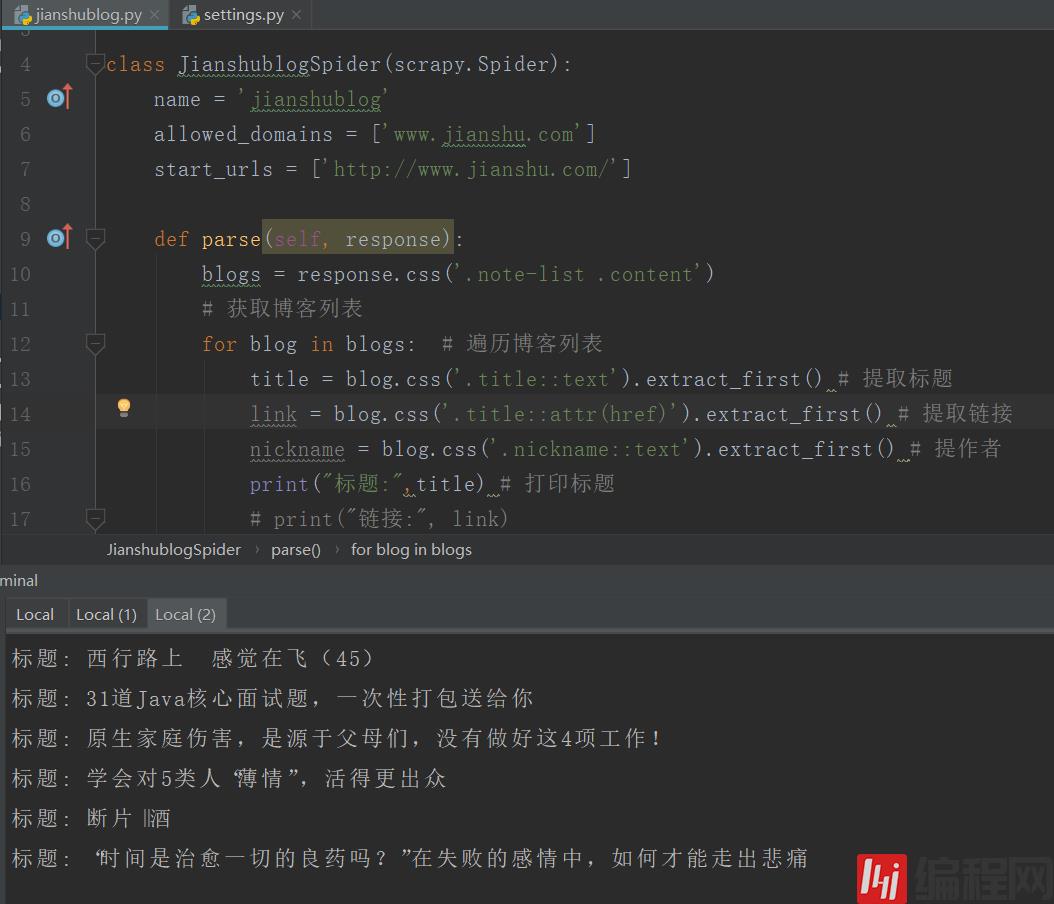
jianshublog.py
import scrapy class JianshublogSpider(scrapy.Spider): name = 'jianshublog' allowed_domains = ['www.jianshu.com'] start_urls = ['http://www.jianshu.com/'] def parse(self, response): blogs = response.css('.note-list .content') # 获取博客列表 for blog in blogs: # 遍历博客列表 title = blog.css('.title::text').extract_first() # 提取 link = blog.css('.title::attr(href)').extract_first() # 提取链接 nickname = blog.css('.nickname::text').extract_first() # 提作者 print("",title) # 打印 # print("链接:", link) # print("作者:", nickname)最后别忘了执行爬虫命令
scrapy crawl jianshublog到此这篇关于python中Scrapy爬虫框架的作用有哪些的文章就介绍到这了,更多相关的内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!







