
一、Kubernetes介绍
Kubernetes(K8s)是一个开源平台,能够有效简化应用管理、应用部署和应用扩展环节的手动操作流程,让用户更加灵活地部署管理云端应用。
作为可扩展的容错平台,K8s几乎能够部署在所有基础设施中,与Google Cloud、MS Azure及AWS等公有云、私有云、混合云、服务器集群、数据中心等完美兼容。Kubernetes最大的亮点在于支持容器自动部署和自动复制。这也是大量云端微服务基础设施部署在K8s上的原因。
二、K8s由来
K8s最初是由Google工程师设计开发的,于2014年上线并开源,目前由来自微软、红帽、IBM及Docker等软件巨头的社区贡献者维护升级。
Google不仅开源了公司整个基础设施在容器中的运行方式,还积极开发Linux容器技术,支撑Google所有云服务。K8s是基于云平台15年的生产工作负载运行经验设计出来的,用于处理成千上万个容器。Google每周部署20多亿个容器。在K8s上线前,Google主要通过内部开发平台Borg进行容器部署。Borg是大型内部集群管理系统,运行了无数应用和集群任务,多年的开发经验奠定了K8s技术的基础。
三、K8s工作原理
K8s本质上是分部在不同机器上的容器化应用的协调系统,目的是帮助开发人员通过K8s的可预测性、可扩展性和高可用性管理容器化应用和服务的整个生命周期,通过更高水平的抽象,将多个机器统一成一个机器。这对于大型环境的运行来说至关重要。
K8s不仅能够优化Docker的镜像运行能力和容器管理能力,还能兼容rkt和CoreOS等容器引擎。
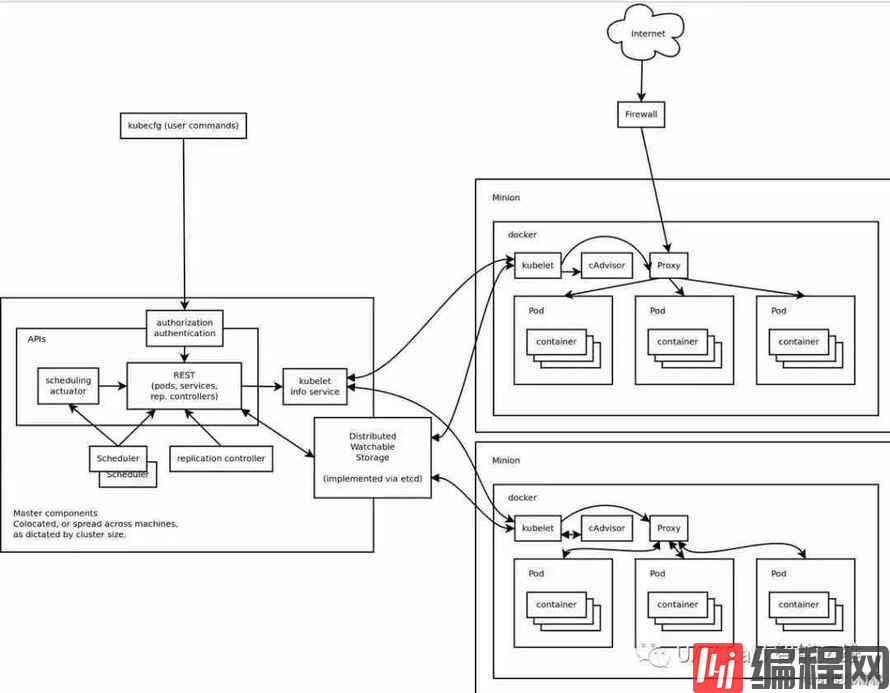
上方架构图展示了K8s工作原理。图中包含一组Master组件,其中包括很多pod。Pod针对特定应用的“逻辑主机”进行建模。每个Pod均包含一个或多个应用容器、存储资源、唯一的网络IP及容器运行细节。Pod是容器的最小原子单元。理论上,Pod中包含一个或多个高度耦合的应用。理想情况下,每个Pod中包含一个容器。
每个进程包含一个API server、一个scheduler和多个controller。
API server负责暴露K8s API、处理REST操作及后续更新。Scheduler负责将未部署的Pod匹配到合适虚拟机或物理机上。如果没有合适的机器,则Pod将处于未分配状态,直至出现合适的节点。Master运行集群级别的其他功能,通过嵌入式controller完成创建端点、发现节点、复制控制等操作。由于controller设计灵活且可扩展,Kube管理员可自行创建controller。Kube通过API server监控K8s集群的共享状态,并对集群状态进行调整,确保当前状态与理想状态一致。
K8s提供支持容器化应用统一自动化、控制和升级的各项功能,包括企业级容器部署、内置服务发现、自动扩展、持久化存储、高可用、集群互通和资源装箱等。
依赖这些功能,K8s实现了对单体应用、批处理应用及高度分布式微服务应用等不同应用架构的支持。
四、K8s监控实践中的挑战
2014年上线以来,K8s一直在变革容器技术,已经成为快速批量启动应用的关键工具。与此同时,挑战也随之而来,容器编排极其复杂。
K8s虽然已经极大地简化了容器实现和管理过程中从调度、配置到状态自动维护等一系列任务的操作难度,但监控方面依然存在挑战:
- 相互通信的应用分布在不同的云服务平台上。K8s本质上是一个通用平台,用户可在平台上自由部署应用。企业一般会采用多云端解决方案,不仅能够减少对单一云服务平台的依赖,还能缩短故障停机时间,避免数据丢失。但这种部署方式也给实时数据抓取和应用状态监控带来了挑战。
- 在动态基础设施上不断迁移应用。由于应用处于频繁迁移状态,因此很难做到所有平台和协议之间的完全可见,这就会隐藏系统的瓶颈问题。很多公司的基础设施上都运行着多个应用,因此这种问题是不可避免的。如果没有稳健的监控系统,用户便无法发现应用的潜在问题。
监控对象数量繁多且极为复杂:K8s由很多组件构成,非常复杂,因此要监控K8s,就必须监控下列所有对象:
- 集群容量和资源利用情况:(a)Node:确保K8s所有节点的状态,监控CPU、内存和硬盘的使用情况;(b)Pod:确保所有已实现Pod状态正常;(c)Container:根据配置的消耗上限监控CPU和内存的消耗情况。 应用:根据请求率、吞吐量、错误率监控集群中应用的性能和可用性。
- 终端用户体验:监控移动应用和浏览器性能,优化加载时间和可用性,提高客户满意度。
- 配套基础设施:前文提到,K8s的运行平台也非常重要。
操作细节:K8s的所有核心组件(即kubelet、Kube controller manager和Kube scheduler)都有很多标记。这些标记决定了集群的操作和运行方式,其初始默认值一般较小,适用于规模较小的集群。随着集群规模的扩大,用户需要及时对集群进行调整,并监控K8s的标签和注释等细节。
但监控工具从K8s抓取大量数据时会影响集群性能甚至导致集群故障,因此需要确定监控基线。需要诊断故障时,可适当调高基线值。
调高基线值的同时要部署更多master和node,提高可用性。涉及大规模部署时,可单独部署专门存储K8s数据的集群,这样能够保证在创建监控事件、检索监控数据时,主要实例的性能不受影响。
五、从源头上监控K8s
和很多容器编排平台一样,K8s具备基本的服务器监控工具。用户可对这些工具进行适当调整,以便更好地监控K8s的运行情况。主要工具如下:
- K8s仪表盘:插件工具,展示每个K8s集群上的资源利用情况,也是实现资源和环境管理与交互的主要工具。
- 容器探针:容器健康状态诊断工具。
- Kubelet:每个Node上都运行着Kubelet,监控容器的运行情况。Kubelet也是Master与各个Node通信的渠道。Kubelet能够直接暴露cAdvisor中与容器使用相关的个性化指标数据。
- cAdvisor:开源的单节点agent,负责监控容器资源使用情况与性能,采集机器上所有容器的内存、网络使用情况、文件系统和CPU等数据。
- cAdvisor简单易用,但也存在不足:一是仅能监控基础资源利用情况,无法分析应用的实际性能;二是不具备长期存储和趋势分析能力。
- Kube-state-metrics:轮询Kubernetes API,并将Kubernetes的结构化信息转换为metrics。
- Metrics server:Metrics server定时从Kubelet的Summary API采集指标数据,并以metric-api的形式暴露出去。
整体监控流程如下:
- cAdvisor默认安装在所有集群节点上,采集容器和节点的指标数据。
- Kubelet通过kubelet API将指标数据暴露出去。
- Metrics判断所有可用节点,请求kubelet API上送容器和节点使用情况数据,然后通过Kubernetes聚合API将指标数据暴露出去。
上述基础性工具虽然不能提供详细的应用监控数据,但能够帮助用户了解底层主机和K8s节点的情况。
一般来说,K8s集群管理员主要关注全局监控,而应用开发人员则主要关注应用层面的监控情况。但两者的共同诉求都是在控制投入成本的前提下尽可能全面地监控系统、采集数据。下周文章中,我们将介绍两个可行的监控方案:Prometheus和Sensu。两个方案都能全面提供系统级的监控数据,帮助开发人员跟踪K8s关键组件的性能、定位故障、接收预警。
本篇为译文,原文作者:STEFAN THORPE
译自Monitoring Kubernetes
译文首发于UAVStack智能运维










