

作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 专栏案例:数据分析 |
|---|
| 数据分析:某电商优惠卷数据分析 |
| 数据分析:旅游景点销售门票和消费情况分析 |
| 数据分析:消费者数据分析 |
| 数据分析:餐厅订单数据分析 |
| 数据分析:基于随机森林(RFC)对酒店预订分析预测 |
| 数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析 |
文章目录
麦当劳(McDonald’s)是源自美国南加州的跨国连锁快餐店,也是全球最大的快餐连锁店,主要贩售汉堡包及薯条、炸鸡、汽水、冰品、沙拉、水果、咖啡等快餐食品。近年来,越来越多的人意识到快餐食品的不健康性,麦当劳也成了“垃圾食品”的代名词。美国纪录片《Super Size Me》记录了一个人一个月内只吃麦当劳后的身体变化,更引起了人们对于快餐食品营养超标的担忧。本分析旨在通过实证方法评估麦当劳数据集中260个产品的营养成分,我们先从一些标准的数据探索分析开始,之后讨论并使用Plotly绘制交互式散点图以展示不同的营养指标。
2.1数据集的整体特征
|数据集名称 |数据类型 |特征数 |实例数 |值缺失 |相关任务|
| 数据集名称 | 数据类型 | 特征数 | 实例数 | 值缺失 | 相关任务 |
|---|---|---|---|---|---|
| 麦当劳餐品营养成分数据集 | 字符、数值数据 | 24 | 260 | 0 | 可视化 |
2.2属性描述
| 属性 | 数据类型 | 字段描述 |
|---|---|---|
| Category | String | 食物类别 |
| Item | String | 食品名称 |
| Serving Size | String | 食用分量 |
| Calories | Integer | 卡路里 |
| Calories from Fat | Integer | 来自脂肪的卡路里 |
| Total Fat | Integer | 脂肪总量 |
| Total Fat (% Daily Value) | Integer | 脂肪总量占每日推荐摄入量的百分比 |
| Saturated Fat | Integer | 饱和脂肪 |
| Saturated Fat (% Daily Value) | Integer | 饱和脂肪占每日推荐摄入量的百分比 |
| Trans Fat | Integer | 反式脂肪 |
| Cholesterol | Integer | 胆固醇 |
| Cholesterol (% Daily Value) | Integer | 胆固醇占每日推荐摄入量的百分比 |
| Sodium | Integer | 钠 |
| Sodium (% Daily Value) | Integer | 钠占每日推荐摄入量的百分比 |
| Carbohydrates | Integer | 碳水化合物 |
| Carbohydrates (% Daily Value) | Integer | 碳水化合物占每日推荐摄入量的百分比 |
| Dietary Fiber | Integer | 膳食纤维 |
| Dietary Fiber (% Daily Value) | Integer | 膳食纤维占每日推荐摄入量的百分比 |
| Sugars | Integer | 糖分 |
| Protein | Integer | 蛋白质 |
| Vitamin A (% Daily Value) | Integer | 维他命A占每日推荐摄入量的百分比 |
| Vitamin C (% Daily Value) | Integer | 维他命C占每日推荐摄入量的百分比 |
| Calcium (% Daily Value) | Integer | 钙占每日推荐摄入量的百分比 |
| Iron (% Daily Value) | Integer | 铁占每日推荐摄入量的百分比 |
Python 3.9
Anaconda
Jupyter Notebook
4.1数据准备
加载需要的模块
import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as plt%matplotlib inlineimport plotly.offline as pypy.init_notebook_mode(connected=True)import plotly.graph_objs as goimport plotly.tools as tlsimport warningswarnings.filterwarnings('ignore')加载数据
#加载数据集menu = pd.read_csv("/home/mw/mcdonald_s_menu.csv")#预览数据集前5行menu.head()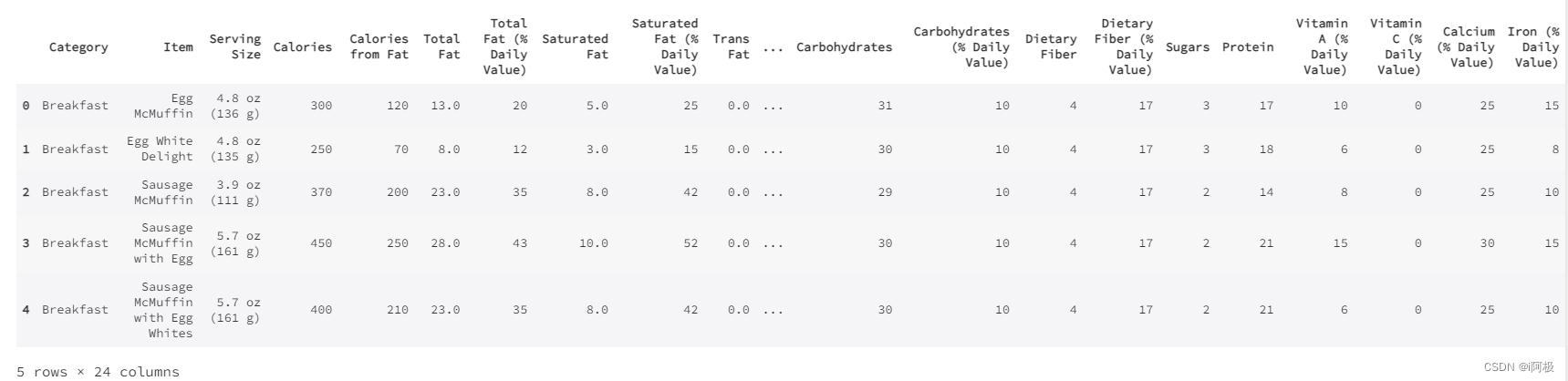
查看数据集行列数
print("该数据集共有 {} 行 {} 列".format(menu.shape[0],menu.shape[1])) 
每一行代表一样麦当劳产品;24列,包括了产品的类别,名称,大小,以及营养成分(如卡路里,脂肪,胆固醇,钠,碳水化合物,膳食纤维,糖,蛋白质,维他命A,维他命C,钙,铁)等内容。
4.2数据质量检查
检查空值
menu.isnull().any()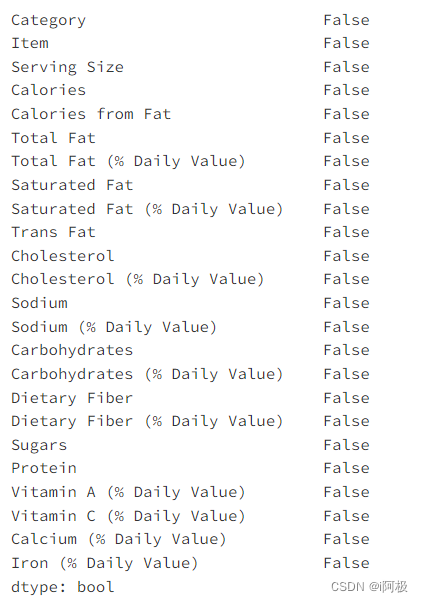
各个column内容的描述性统计
menu.describe()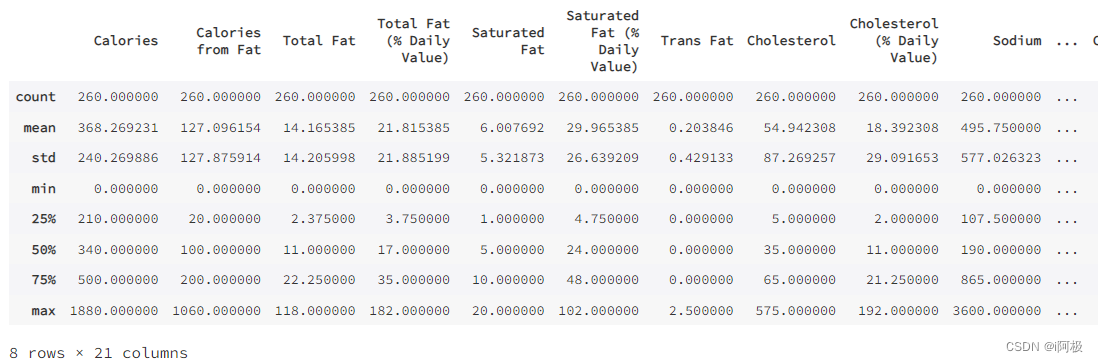
4.3探索性分析
首先,我们看一下每一类食品的数量,并绘图展示:
count_by_category = menu[["Category"]].groupby(["Category"]).size().reset_index(name = 'Counts').sort_values(by = "Counts", ascending = False)count_by_category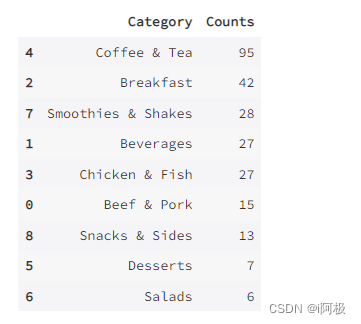
#条形图fig, ax = plt.subplots(figsize = (12,9))ax = sns.barplot(x="Category", y="Counts", data = count_by_category).set_title("每一类食品的数量")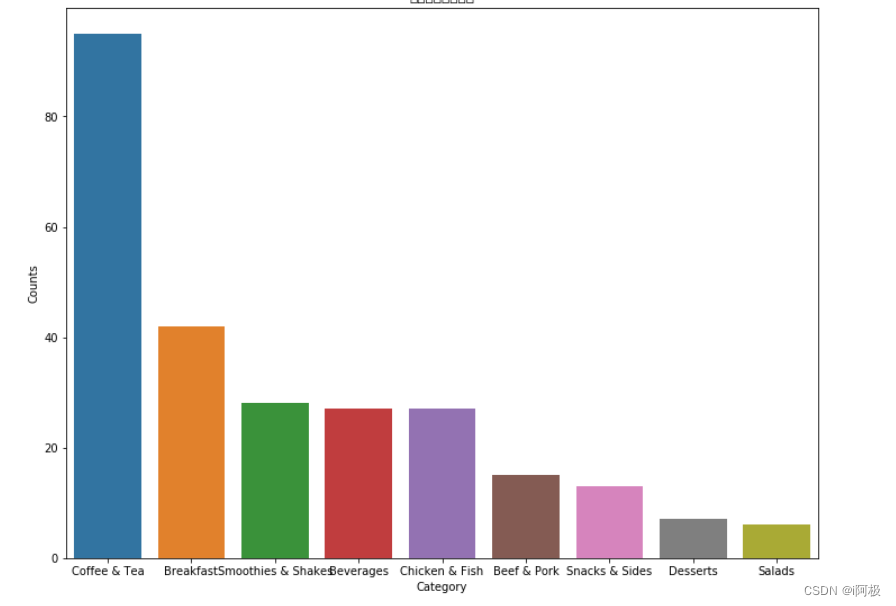
#饼形图plt.figure(figsize = (12,9))plt.pie(x = count_by_category["Counts"], labels=count_by_category["Category"], autopct='%1.0f%%',)plt.show()
从条形图和饼形图可以看出,数量排名第一的品类是咖啡和茶,高达37%;之后是早餐(16%),冰沙奶昔(11%),饮品(10%),鸡肉鱼肉(10%)和牛肉猪肉(6%)。小吃,甜点和沙拉占比最少,其中沙拉类食品仅占所有食品的2%。
接下来,我们看看,不同品类的食物,其卡路里含量如何
#盒形图fig, ax = plt.subplots(figsize = (12,9))ax = sns.boxplot(x = 'Category', y = 'Calories', data = menu).set_title("卡路里")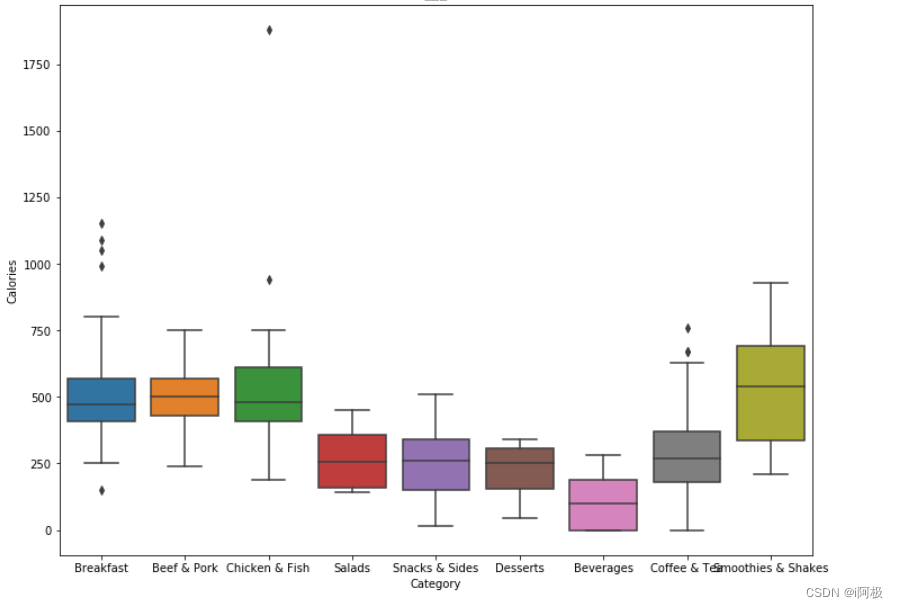
一些有趣的发现:
- 早餐系列、猪肉牛肉系列、鸡肉鱼肉系列的卡路里含量较高(主食),冰沙奶昔系列的卡路里含量最高;
- 沙拉、小食、甜品、咖啡和茶的卡路里含量较低,饮品的卡路里含量最低;
- 早餐系列、鸡肉鱼肉系列和咖啡茶系列有一些异常值(outlier),可能是一些大份食物。
以上分析提醒了我们,食品的卡路里含量(及其他成分含量)会受到其份量的影响,将食品调整至同样的份量可以让之后的分析更加客观。
通过回顾数据集中“Serving Size”一栏,我们发现麦当劳对份量的标注并不完全统一,有如下几种形式:
1)4.8 oz (136 g) 2)1 cookie (33 g) 3)21 fl oz cup 4) 1 carton (236 ml) 5) 6 fl oz (177 ml) 6) 16.9 fl oz
固体食物的份量标注比较统一,都是按1)的形式,标出了oz和g两种重量单位,唯一的特例是2),只标注了g这一重量单位。
半液态和液态食物的份量标注比较杂乱,有些和固体食物一样标注了重量,但大部分属于3)-6),即标注fl oz和/或ml两种体积单位。
因此我们的提取原则是,重量单位优先提取g,没有g再提取oz,并转换为g;体积单位优先提取ml,没有ml再提取fl oz,并转换为ml。
*注:1盎司(oz)=28.35克(g);1美制液体盎司(fl oz)=29.57毫升(ml)
因为重量单位和体积单位的不一致,为了之后的分析方便,我们假设1ml的液体等于1g,并把一些半液态和液态食品的份量从体积转为重量。
将食品调整至同样的份量(按100g计算)
#正则表达式匹配几种不同的份量标注方式import rep1 = re.compile(r'[(](.*?)[ g)]')p2 = re.compile(r'(.*?)[ ]')#定义函数,提取份量数据def getLambda(x, p1, p2): try: val = float(re.findall(p1,x)[0]) except: val = float(re.findall(p2,x)[0]) * 29.57 # 提取的是fl oz,乘以29.57转换为ml return val#调整menu数据集norm_menu = menu.iloc[:,:]norm_menu["Size g"] = norm_menu["Serving Size"].apply(lambda x: getLambda(x, p1, p2))norm_menu["Calories per 100g"] = (norm_menu['Calories']/norm_menu["Size g"]) * 100norm_menu.head()#盒形图fig, ax = plt.subplots(figsize = (12,9))sns.boxplot(x = 'Category', y = 'Calories per 100g', data = norm_menu)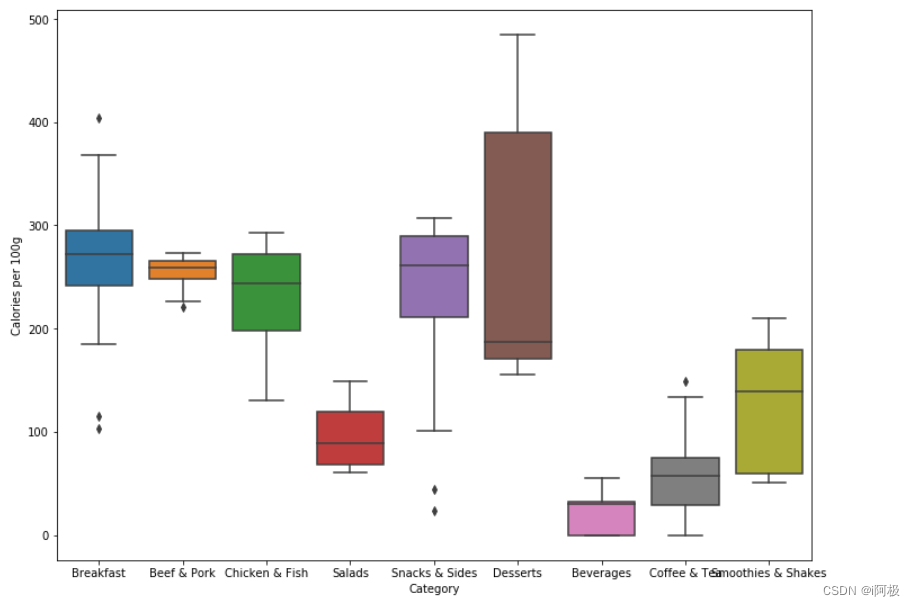
对比没有调整过的数据画出的盒形图可以得知:
- 固态食品中,主食(早餐,牛肉猪肉,鸡肉鱼肉)依旧是卡路里含量最高的食品。之前我们以为卡路里含量较低的小食、甜点等,其实只是因为份量较小,如果换算成同样的份量,卡路里含量也不低,和主食持平。只有沙拉的卡路里含量远低于其他类食品,其平均值是主食的一半左右。
- 液体及半液体的饮品,卡路里含量总体低于固体食品,但冰沙奶昔的卡路里明显高于饮料和咖啡茶,甚至高于沙拉。
因此,对于一个选择麦当劳就餐的减肥人士来说,为了填饱肚子,最好点一份沙拉。如果还想点一份饮品,不建议点冰沙奶昔。
4.4通过轮廓图和相关图来比较特征
轮廓图
我们首先看看一个特征如何影响其他特征:轮廓图或者KDE图可以提供一个特征相对于另一个特征的分布。简单来讲,这让我们对定量数据有一个快速的感知。调用了Seaborn中的kdeplot函数。我们选取了几个主要特征,并生成了9张轮廓图,如下所示:
# KDE图f, axes = plt.subplots(3, 3, figsize=(10, 10), sharex=True, sharey=True)s = np.linspace(0, 3, 10)cmap = sns.cubehelix_palette(start=0.0, light=1, as_cmap=True)# Generate and plot a random bivariate datasetx = menu['Cholesterol (% Daily Value)'].valuesy = menu['Sodium (% Daily Value)'].valuessns.kdeplot(x, y, cmap=cmap, shade=True, cut=5, ax=axes[0,0])axes[0,0].set(xlim=(-10, 50), ylim=(-30, 70), title = 'Cholesterol and Sodium')cmap = sns.cubehelix_palette(start=0.333333333333, light=1, as_cmap=True)# Generate and plot a random bivariate datasetx = menu['Carbohydrates (% Daily Value)'].valuesy = menu['Sodium (% Daily Value)'].valuessns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[0,1])axes[0,1].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Carbs and Sodium')cmap = sns.cubehelix_palette(start=0.666666666667, light=1, as_cmap=True)# Generate and plot a random bivariate datasetx = menu['Carbohydrates (% Daily Value)'].valuesy = menu['Cholesterol (% Daily Value)'].valuessns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[0,2])axes[0,2].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Carbs and Cholesterol')cmap = sns.cubehelix_palette(start=1.0, light=1, as_cmap=True)# Generate and plot a random bivariate datasetx = menu['Total Fat (% Daily Value)'].valuesy = menu['Saturated Fat (% Daily Value)'].valuessns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[1,0])axes[1,0].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Total Fat and Saturated Fat')cmap = sns.cubehelix_palette(start=1.333333333333, light=1, as_cmap=True)# Generate and plot a random bivariate datasetx = menu['Total Fat (% Daily Value)'].valuesy = menu['Cholesterol (% Daily Value)'].valuessns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[1,1])axes[1,1].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Cholesterol and Total Fat')cmap = sns.cubehelix_palette(start=1.666666666667, light=1, as_cmap=True)# Generate and plot a random bivariate datasetx = menu['Vitamin A (% Daily Value)'].valuesy = menu['Cholesterol (% Daily Value)'].valuessns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[1,2])axes[1,2].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Vitamin A and Cholesterol')cmap = sns.cubehelix_palette(start=2.0, light=1, as_cmap=True)# Generate and plot a random bivariate datasetx = menu['Calcium (% Daily Value)'].valuesy = menu['Sodium (% Daily Value)'].valuessns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[2,0])axes[2,0].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Calcium and Sodium')cmap = sns.cubehelix_palette(start=2.333333333333, light=1, as_cmap=True)# Generate and plot a random bivariate datasetx = menu['Calcium (% Daily Value)'].valuesy = menu['Cholesterol (% Daily Value)'].valuessns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[2,1])axes[2,1].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Cholesterol and Calcium')cmap = sns.cubehelix_palette(start=2.666666666667, light=1, as_cmap=True)# Generate and plot a random bivariate datasetx = menu['Iron (% Daily Value)'].valuesy = menu['Total Fat (% Daily Value)'].valuessns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[2,2])axes[2,2].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Iron and Total Fat')f.tight_layout()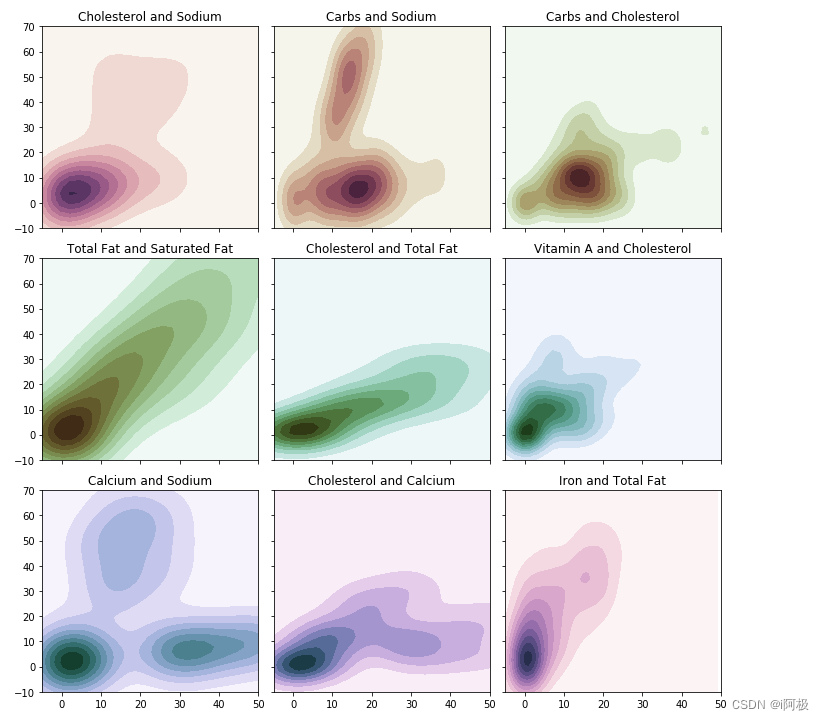
Pearson相关图
现在绘制Pearson相关图,检查不同营养指标之间的相关程度。这次,我们调用了Plotly的交互式绘图功能,绘制特征之间相关性的热图(Heatmap),如下所示:
data = [ go.Heatmap( z = menu.iloc[:, 3:].corr().values, x = menu.columns.values, y = menu.columns.values, colorscale = 'Viridis', text = menu.iloc[:, 3:].corr().round(2).astype(str), opacity = 1.0 )]layout = go.Layout( title = '各个营养指标的Pearson相关图', xaxis = dict(ticks='', nticks=36), yaxis = dict(ticks=''), width = 900, height = 700,)fig = go.Figure(data = data, layout = layout)py.iplot(fig, filename = 'labelled-heatmap')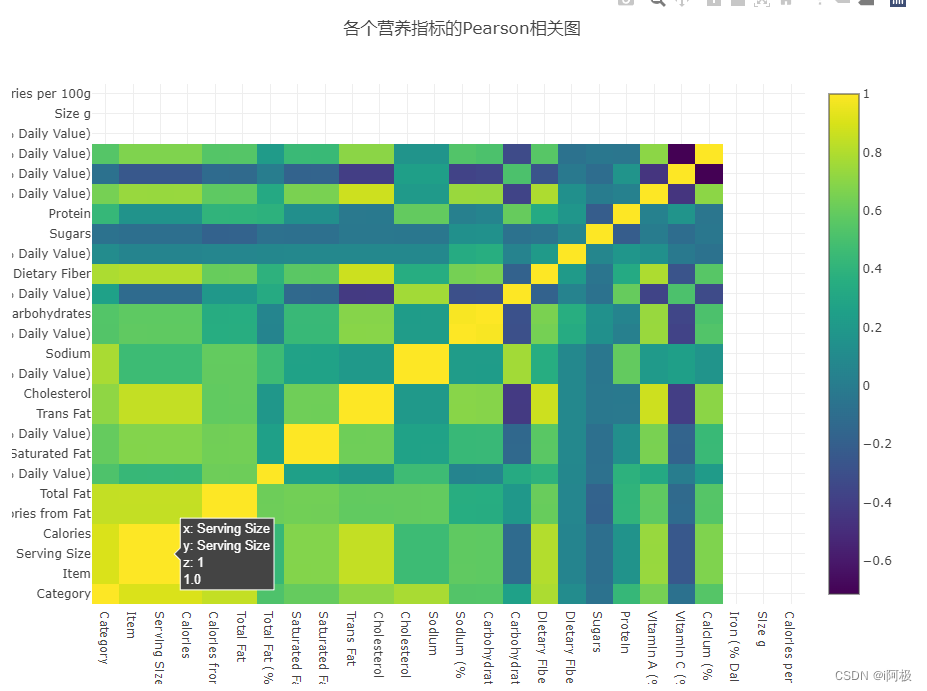
点击不同的方格,可以查看某两个特征的相关性。颜色越趋近于黄色,说明两者正相关性越强。颜色越趋近于紫色,说明两者负相关性越强。
- 从相关图中可以看出明显相关的特征,例如份量和卡路里的相关性高达0.9。
- 然而,有一些相关性非常不直观。例如,总脂肪和饱和脂肪/反式脂肪之间存在相当弱的相关性,但在我们普通人的认知中,这两者理应早存一定相关性。
- 热图也从负相关图(深蓝/黑)的斑点中引出了有趣的发现。例如,它表明碳水化合物通常与反式脂肪,胆固醇,钠,膳食纤维和维生素A呈负相关。这与碳水化合物的负相关性确实很多。
数据质量是否存在任何问题?
- 现在很明显,碳水化合物列与其他列负相关程度很强,这是符合常识的。然而,或许存在如下可能性:含碳水化合物的食物可能除了碳水化合物之外没有其他东西,从而导致了上面提到的负相关性,这也是需要在分析中结合实际情况思考的。
订阅热门专栏:
《数据分析之道》
《数据分析之术》
《机器学习案例》
《数据分析案例》
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢首发CSDN博客,创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗








