
今天和大家聊一下mysql中的count()方法
我们日常开发中,经常会用到count()命令,有的人用count(*),有的人用count(1),还有的人用count(id),那么这几种写法都有什么区别呢?哪种方法效率更高呢?今天我们就来解密一下
1 首先我们要先了解count()方法的原理
count()方法的作用就是计算当前sql语句所能查到的非NULL的行数,
mysql分为server层和存储引擎层,具体结构如下:
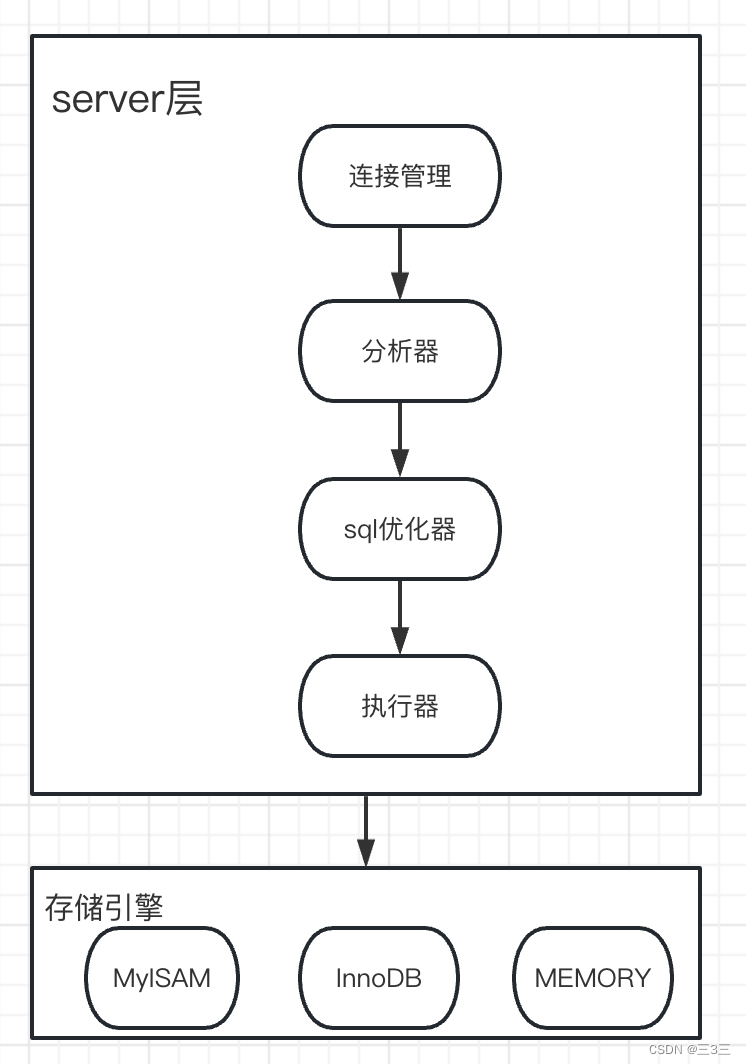
常见的存储引擎是InnoDB、myisam。
为什么要介绍引擎种类呢?因为count()方法在不同的存储引擎下,他的实现方式是不一样的。
例如语句 select count(*) from table1;
在myisam引擎的数据表里,会有个单独的字段,用来记录当前表里有几行数据,因此当查询行数的时候,直接返回这个字段就可以了,速度自然是相当迅速。
在InnoDB引擎里,实现方式则是选择体积最小的索引树,然后通过遍历叶子节点的个数,以此来获取全表的数据。
所以在InnoDB中,当count()需要扫描的数据量越大的时候,所消耗的时间就会越长。
2 也许有人会问为什么InnoDB不能像MyIsam那样单独记录表行数呢?
MyIsam和InnoDB最大的区别就是MyIsam不支持事务,InnoDB支持事务。
而事务有四种隔离级别,其中默认的就是可重复读。
InnoDB通过MVCC实现了可重复读隔离级别,事务开启之后多次执行同样的select,执行的结果都会是同样的数据。
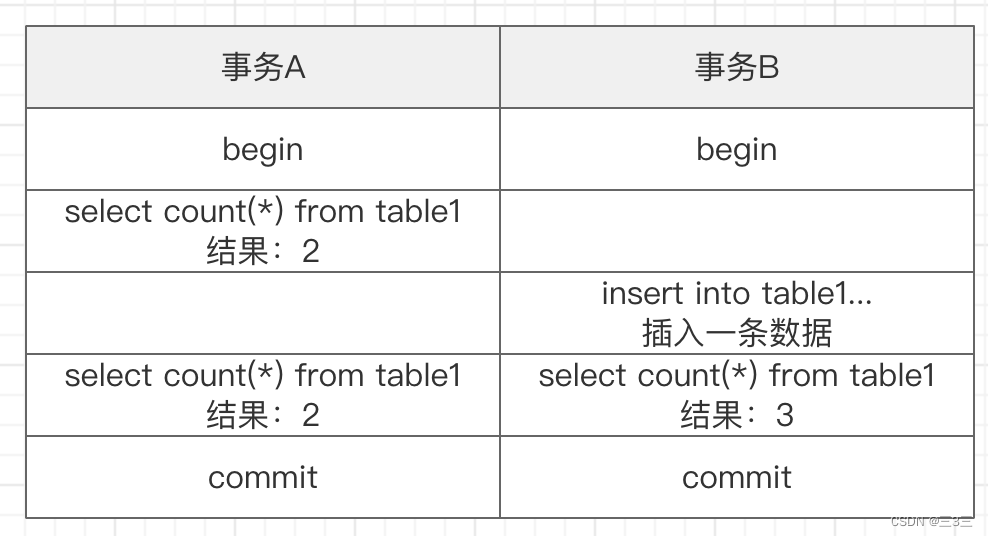
我们看个例子:
如上图所示,有两个事务A、B,一开始table1表里就2条数据,事务A也确实查到了2条,在A第一次查完之后,事务B插入了一条数据,此时table1表里会有3条数据,事务A再次查询还是只能查到2条数据。这就是MVCC保证了在同一事务中,查询的结果是一样的。
也正因为有事务隔离级别,所以不同的事务在同一时间下,查询的表内数据会是不一致的,以此InnoDB是没办法像MyIsam那样,在表里单纯的加个字段来存储表数据行数的。
3 回到正题,count()括号里可以放置各种字段,甚至是非字段,那么他们都有什么区别呢?
count方法的大原则是server层会从innodb存储引擎里读来一行行数据,并且只累计非null的值。但这个过程,根据count()方法括号内的传参,有略有不同。
(1) count(*)
server层拿到innodb返回的行数据,不对里面的行数据做任何解析和判断,默认取出的值肯定都不是null,直接行数+1。
(2) count(1)
server层拿到innodb返回的行数据,每行放个1进去,默认不可能为null,直接行数+1。
(3) count(某个列字段)
由于指明了要count某个字段,innodb在取数据的时候,会把这个字段解析出来返回给server层,所以会比count(1)和count(*)多了个解析字段出来的流程。
- 如果这个列字段是主键id,主键是不可能为null的,所以server层也不用判断是否为null,innodb每返回一行,行数结果就+1.
- 如果这个列是普通索引字段,innodb一般会走普通索引,每返回一行数据,server层就会判断这个字段是否为null,不是null的情况下+1。当然如果建表sql里字段定义为not null的话,那就不用做这一步判断直接+1。
- 如果这个列没有加过索引,那innodb可能会全表扫描,返回的每一行数据,server层都会判断这个字段是否为null,不是null的情况下+1。同上面的情况一样,字段加了not null也就省下这一步判断了。
现在应该对他们的执行效率有数了吧
大概如下:
count(*) = count(1) > count(主键id) > count(普通索引列) > count(未加索引列)
所以说count(*)是最快的
来源地址:https://blog.csdn.net/LT11hka/article/details/130955503







