
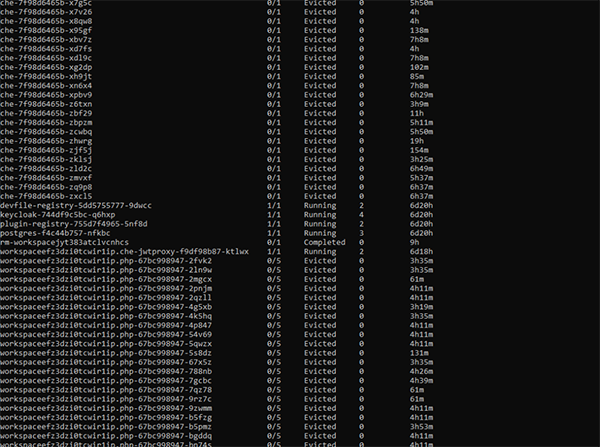
显然,通过kubectl get,我们发现有数十个evicted pod,而实际上可能只想运行5个pod。此时,您可能非常希望通过对Kubernetes集群资源的管理,来自动实现对于容量和资源的分配。
两个示例
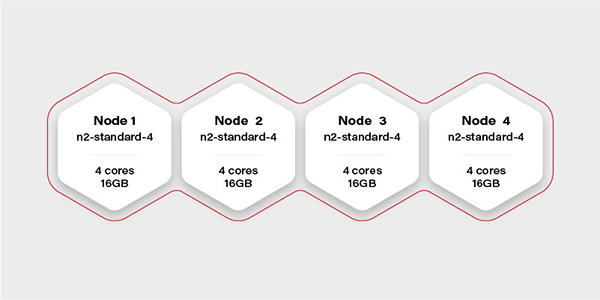
如上图所示,假设我们手头有一个带有16个虚拟CPU和64GB RAM的Kubernetes集群。那么,我们可以在它上面流畅地运行一个需要20GB内存的AI容器吗?
假设该集群中有4个worker,每个都需要有16GB的可用内存(实际上,DaemonSet和系统服务都需要运行一个节点,并占用少量的资源,因此真实可用内存可能会更少一些)。那么,在这种情况下,如果我们只分配16GB内存给容器的话,我们将无法保证其流畅运行。
其实,不仅此类大容器的部署,我们在进行其他复杂的部署,甚至是采用Helm chart(请参见-- https://grapeup.com/blog/asp-net-core-ci-cd-on-azure-pipelines-with-kubernetes-and-helm/)之类开箱即用的产品时,都必须始终考虑到资源的限制问题。
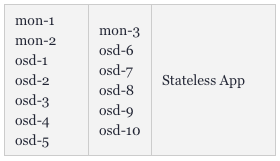
让我们来看另一个示例--将Ceph部署到同一个集群中。我们的实现目标是将1TB的存储空间分成10个OSD(object storage daemons,对象存储守护程序)和3个ceph MON(监视器)。我们希望将其放置在两个节点上,其余两个则留给需要使用该存储的部署。这将是一个高度可扩展的架构。
一般用户首先能够想到的做法是将OSD的数量设置为10,MON设置为3,将tolerations添加到Ceph的pod中,以及将taint匹配上Node 1和Node 2。而所有的ceph部署和pod都将nodeSelector设置为仅针对Node 1和2。
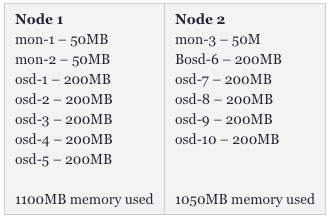
如下图所示,Kubernetes会让mon-1、mon-2和5个osd运行在第一个worker上,让mon-3和另5个osds运行在第二个worker上。应用程序可以快速地将大量的大体积文件保存到Ceph上。
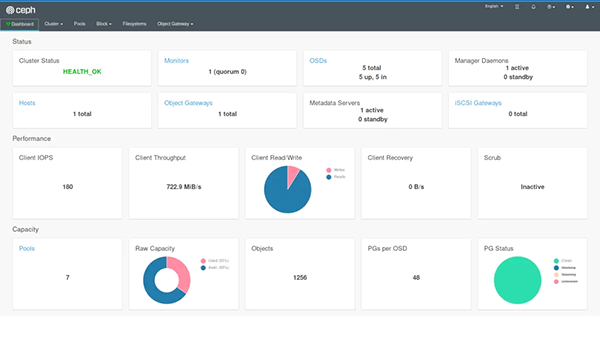
如果我们还部署了仪表板,并创建了一个复制池,那么还可以直观地看到1TB的可用存储空间和10个OSD的状态。
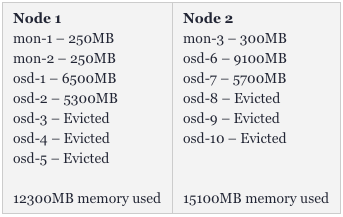
不过,在运行了一段时间后,我们会发现真正可用的存储空间只剩下了400GB,出现了许多evicted OSD pods,而且有4个OSDs正在同时运行。对此,我们需要重新审视初始时的部署配置。
极限和范围
平时,就算我们运行了13个Pod(其中可能有3个监控器),也不会占用过多的资源,但是OSD则不然。由于Ceph在内存中缓存了很大量的数据,那么我们使用得越频繁,它需要的资源也就越多。同时,各种存储容器的数据复制和平衡也需要消耗一定的空间。因此,在初次化部署之后,内存的分配情况会如下图所示:
而在数小时的持续运行之后,该集群就会出现如下状况:
可见,我们损失了几乎50%的pod。而且这并非是最终状态,如果高吞吐量将目标指向剩余的容器,那么我们很快会失去得更多。那么,这是否意味着我们需要给Ceph集群配置超过32GB的内存呢?非也。只要我们正确地设置了限制(请参见--https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#resource-requests-and-limits-of-pod-and-container),单个OSD就不能从其他pod处抢夺所有的可用内存。
也就是说,在这种情况下,我们最简单的方法是:为mon整体分配并保留2GB的内存,其中每个的极限为650MB;将一共30GB的内存除以10个OSD(请见下图):
由于我们为OSD分配了15GB的内存,并为每个Pod配置了650MB的内存,因此第一个节点会需要:15 + 2 * 0.65 = 16.3GB。此外,我们同样需要考虑到在同一节点上运行的DaemonSet日志。因此,修正值应该是:
服务质量
如果我们还为Pod设置了一个与限制完全匹配的请求,那么Kubernetes将会以不同的方式来对待此类Pod,如下图所示:
该配置将Kubernetes中的QoS设置为Guaranteed(否则是Burstable)。有Guaranteed的Pod是永远不会被evicte的。通过设置相同的请求和限制,我们可以确保Pod的资源使用情况,而无需顾及Kubernetes对其进行移动或管理。此举虽然降低了调度程序(scheduler)的灵活性,但是能够让整个部署方式更具有一定的弹性。
自动扩展环境中的资源
对于关键性任务系统(mission-critical systems,请参见--https://grapeup.com/)而言,光靠估算所需的资源,来匹配群集的大小,并做好相关限制是远远不够的。有时候,我们需要通过更加复杂的配置,以及非固定的集群容量,来实现水平扩展和调整可用的worker数量。
假设资源会呈线性扩展的话,那么我们可以同时规划最小和最大群集的容量。而如果pod能够被允许在群集扩展时,跟踪那些按比例在水平方向和垂直方向的扩展的话,那么它在按等比收缩时,则可能会“逐出”其他的pod。为了缓解该问题,Kubernetes提出了两个主要概念:Pod Priority和Pod Disruption Budget。
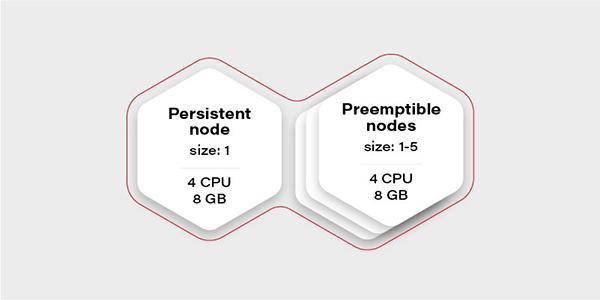
下面,让我们从创建测试场景开始讨论。这次我们不需要大量的节点,只需要创建一个具有两个节点组的集群:一个由常规实例组成(称为持久性),一个由可抢占(preemptible/spot)实例组成。如下图所示,当VM(现有节点)的CPU使用率超过0.7(即70%)时,可抢占节点组将进行扩展。
可抢占实例的优势在于它们比具有相同性能的常规VM要容易实现得多。而唯一缺点是无法保证其生命周期。也就是说,当云提供商出于维护目的,或在24小时之后决定在其他地方需要实例时,该实例就可能会被“逐出”。因此,我们只能在其中运行那些可容错的无状态负载。
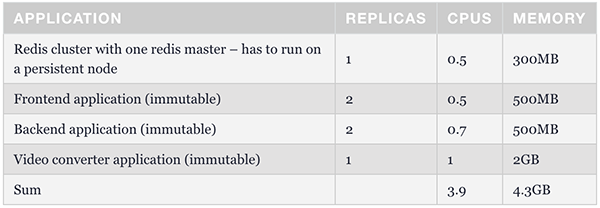
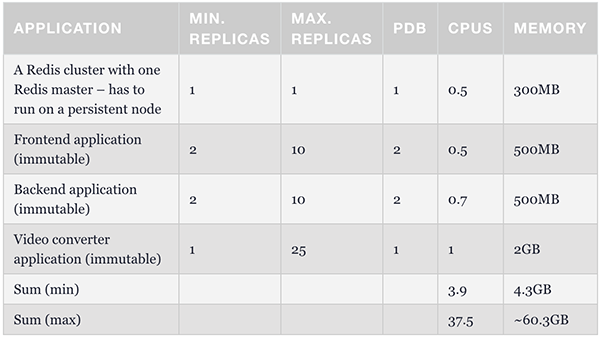
那么,集群中为什么只有一个持久性节点呢?这是为极端情况做准备的。当所有可抢占节点均未运行时,它将维护一个最少的容器集,以管理和保障应用程序的可操作性。下表展示了此类例程的结构。我们可以使用节点选择器将redis master配置为能够在持久性节点上运行。
Pod Priority
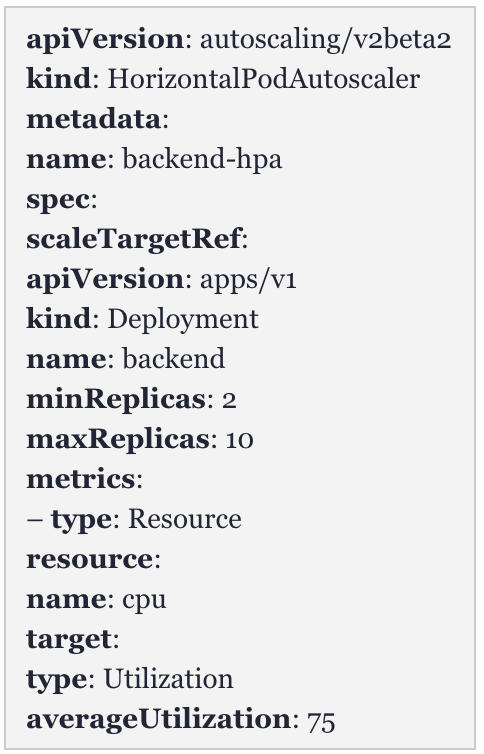
下面,我们来看一个水平pod自动扩展器(Horizontal Pod Autoscaler,HPA)的例子。
前端:
后端:
视频转换器:
作为一款视频转换器,它的目标是降低平均资源的占有率。也就是说,通过检查扩展策略,当有多个转换队列时,其CPU平均使用率可能会迅速达到25%,那么它就会产生新的自动化扩展。例如:如果在大约10分钟的时间内,需要进行50次视频转换,那么该转换器就会扩展出25个实例。那么,为了避免集群中的其他容器被evicte,我们可以创建一种优先级类别(请参见-- https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption):优先级较高的pod对于调度程序而言,具有更高的价值;而优先级较低的pod,则可以被evicte。
因此,如果我们给予转换器较低的优先级,那么就是默认了前端和后端Pod更为重要。在最坏的情况下,该视频转换器可以从群集中逐出。
Pod Disruption Budget
作为更好的pod控制与调度方法,Pod Disruption Budget(PDB)使我们可以一次性配置最少数量的pod。由于有效地阻止了节点资源被耗尽,因此它比仅使用Pod Priority要更加严格。如果其他worker上没有足够的空间用来重新调度pod,它会保证副本的数量不少于可分配的预定。
上表展示了最基本的配置。其中,前端副本数不低于2。我们可以据此为所有Pod分配一个最小值,并确保始终至少有1到2个pod可以处理请求。
这是确保pod能够自动扩展、集群可以伸缩的最简单、也是最安全的方法。只要我们配置了带有中断预定的最少容器集,就能够在不会影响整体稳定性的基础上,满足最小集群容量、以及各种请求的最低处理要求。
至此,我们已拥有了创建稳定方案所需的全部必需组件。我们可以将HPA配置为与PDB相同的最小副本数,以简化调度程序的工作。同时,我们需要根据最大群集数,来确保限制数与请求数不但相同,且不会evicte pod。具体配置如下表所示:
基于上述调度程序的灵活性,在前端和后端的负载过低,却有大量数据需要转换时,该转换器会自动扩展出19-21个实例。
自动扩展的注意事项
关于自动扩展,我们需要注意如下两个方面:
首先,由于我们无法确定云服务提供商的虚拟机启动时长(可能几秒钟,也可能需要几分钟),因此我们无法保障自动扩展肯定能够解决峰值负载的问题。
其次,在集群缩减时,对于那些正在运行组件,我们需要通过反复测试,让调度程序能够快速地将负载移至其他worker处,以实现在不破坏应用操作的前提下,有效地关闭虚拟机。
原Kubernetes Cluster Management: Size and Resources,作者:Adam Kozlowski
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】












{kind=link}
![[[341211]]](https://s2.51cto.com/oss/202009/08/4d45bfd0025e61540bde25b13bb96178.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}