
文章目录
源码:
- https://gitee.com/gaode-8/big-file-upload
演示视频
- https://www.bilibili.com/video/BV1CA411f7np/?vd_source=1fe29350b37642fa583f709b9ae44b35
对于超大文件上传我们可能遇到以下问题
• 大文件直接上传,占用过多内存,可能导致内存溢出甚至系统崩溃
• 受网络环境影响,可能导致传输中断,只能重新传输
• 传输时间长,用户无法知道传输进度,用户体验不佳
对于上述问题,我们需要对文件做分片传输。分片传输就是把文件分割成许多较小的文件,然后分多次上传,最后再完成合并。
受网络环境影响,我们还要实现断点续传,以节省传输时间和资源。断点续传就是已经上传或者下载过的文件分片不再传输。
对于已经上传过的文件,可以不再上传,实现秒传。秒传就是根据文件的唯一标识,确认是否需要上传。
实现多任务上传或下载。多任务就是同时多个文件上传或下载。
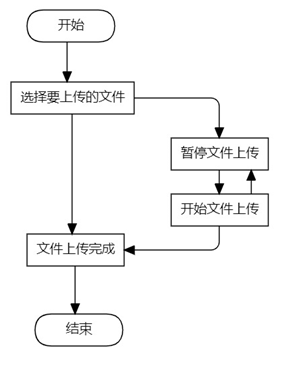
用户上传文件的流程图如图1所示,用户首先选择要上传的文件,上传过程中可以选择暂停或继续上传。
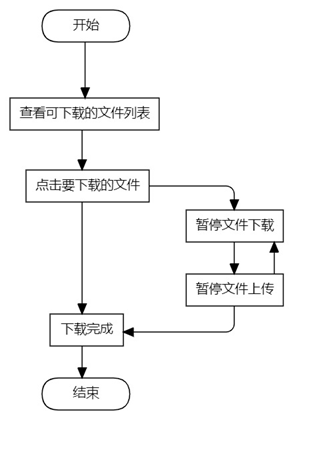
用户上传文件的流程图如图2所示,用户首先可以浏览可以下载的文件列表,然后点击下载,下载过程中可以选择暂停或继续下载
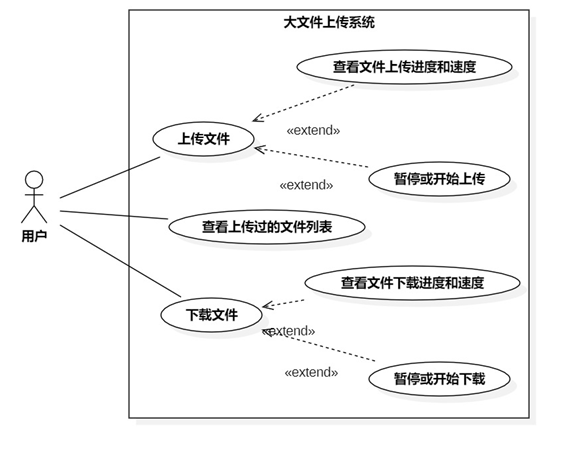
系统用例图如图3所示,用户可以上传文件,在文件上传过程中可以查看文件的上传进度和速度,也可以暂停或开始上传;用户可以查看已经上传过的,也就是可以下载的文件列表;用户可以下载文件,在下载过程中可以查看文件下载的速度和进度,用户可以暂停或开始下载。
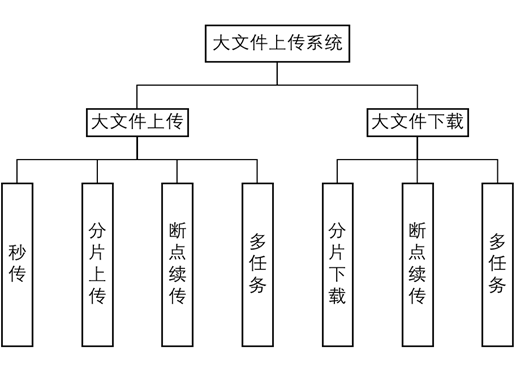
系统总体功能图如图4所示,分为上传和下载。上传包括秒传,分片上传,断点续传,多任务。下载包括分片下载,断点续传,多任务。
后端:
• 语言:Java8
• 框架:SpringBoot2.6
• 开发工具:Idea 2021
前端:
• 语言:Html5、css3、JavaScript
• 框架:Vue3
• 开发工具:Vscode、Edge
数据库:
• mysql8
文件上传模块的流程图如图6所示,顺序图如图7所示
首先前端读取文件生成文件的唯一标识MD5,这里采用常用的MD5生成框架:spark-md5.js。对于大文件一次性读取比较慢,而且容易造成浏览器崩溃,因此这里采用分片读取的方式计算MD5。
然后向服务器发送请求,查看该文件时候已经上传,如果已经上传,就提示用户已经秒传。
如果数据库中没有记录该文件,就表示该文件没有上传或没有上传完成,那么服务器就查询并返回记录的chunk分片列表。
async 和 await配可以实现等待异步函数计算完成
//计算文件的md5值function computeMd5(file, uploadFile) { return new Promise((resolve, reject) => { //分片读取并计算md5 const chunkTotal = 100; //分片数 const chunkSize = Math.ceil(file.size / chunkTotal); const fileReader = new FileReader(); const md5 = new SparkMD5(); let index = 0; const loadFile = (uploadFile) => { uploadFile.parsePercentage.value = parseInt((index / file.size) * 100); const slice = file.slice(index, index + chunkSize); fileReader.readAsBinaryString(slice); }; loadFile(uploadFile); fileReader.onload = (e) => { md5.appendBinary(e.target.result); if (index < file.size) { index += chunkSize; loadFile(uploadFile); } else { // md5.end() 就是文件md5码 resolve(md5.end()); } }; });}//检查文件是否存在function checkFile(md5) { return request({ url: "/check", method: "get", params: { md5: md5, }, });}//文件上传之前,el-upload自动触发async function beforeUpload(file) { console.log("2.上传文件之前"); var uploadFile = {}; uploadFile.name = file.name; uploadFile.size = file.size; uploadFile.parsePercentage = ref(0); uploadFile.uploadPercentage = ref(0); uploadFile.uploadSpeed = "0 M/s"; uploadFile.chunkList = null; uploadFile.file = file; uploadFile.uploadingStop = false; uploadFileList.value.push(uploadFile); var md5 = await computeMd5(file, uploadFile);//async 和 await配可以实现等待异步函数计算完成 uploadFile.md5 = md5; var res = await checkFile(md5); //上传服务器检查,以确认是否秒传 var data = res.data.data; if (!data.isUploaded) { uploadFile.chunkList = data.chunkList; uploadFile.needUpload = true; } else { uploadFile.needUpload = false; uploadFile.uploadPercentage.value = 100; console.log("文件已秒传"); ElMessage({ showClose: true, message: "文件已秒传", type: "warning", }); }}前端分片请求文件,如果分片编号被包含在分片列表内,就标识该分片已经上传,跳过;反之,表示还未上传,那么前端通过file的slice方法分割文件,向服务端传递。同时在页面上显示上传进度和速度。
服务端,收到前端的分片文件后,通过Java的RandomAccess类(随机读写类),从文件的指定位置,写入指定字节,并记录chunk到数据库,如果是最后一个分片再记录file到数据库。

图6 文件上传流程图
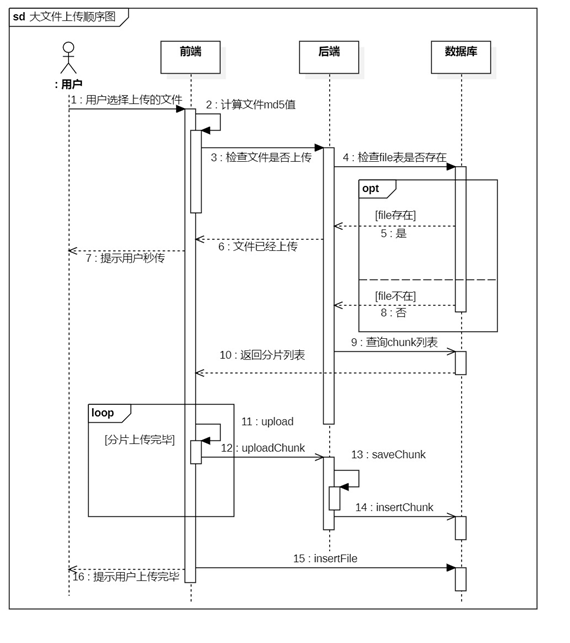
图7 文件上传顺序图
前端代码
选择上传文件 上传列表 {{ uploadFile.name }} {{ formatSize(uploadFile.size) }} 解析进度: 上传进度: {{ uploadFile.uploadSpeed }} 后端代码
package com.cugb.bigfileupload.controller;import com.cugb.bigfileupload.bean.FilePO;import com.cugb.bigfileupload.bean.Result;import com.cugb.bigfileupload.servie.ChunkService;import com.cugb.bigfileupload.servie.FileService;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Value;import org.springframework.web.bind.annotation.*;import org.springframework.web.multipart.MultipartFile;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.Objects;@RestController@CrossOriginpublic class FileController { Logger logger = LoggerFactory.getLogger(getClass()); @Value("${file.path}") private String filePath; @Autowired private FileService fileService; @Autowired private ChunkService chunkService; @GetMapping("/check") public Result checkFile(@RequestParam("md5") String md5){ logger.info("检查MD5:"+md5); //首先检查是否有完整的文件 Boolean isUploaded = fileService.selectFileByMd5(md5); Map data = new HashMap<>(); data.put("isUploaded",isUploaded); //如果有,就返回秒传 if(isUploaded){ return new Result(201,"文件已经秒传",data); } //如果没有,就查找分片信息,并返回给前端 List chunkList = chunkService.selectChunkListByMd5(md5); data.put("chunkList",chunkList); return new Result(201,"",data); } @PostMapping("/upload/chunk") public Result uploadChunk(@RequestParam("chunk") MultipartFile chunk, @RequestParam("md5") String md5, @RequestParam("index") Integer index, @RequestParam("chunkTotal")Integer chunkTotal, @RequestParam("fileSize")Long fileSize, @RequestParam("fileName")String fileName, @RequestParam("chunkSize")Long chunkSize ){ String[] splits = fileName.split("\\."); String type = splits[splits.length-1]; String resultFileName = filePath+md5+"."+type; chunkService.saveChunk(chunk,md5,index,chunkSize,resultFileName); logger.info("上传分片:"+index +" ,"+chunkTotal+","+fileName+","+resultFileName); if(Objects.equals(index, chunkTotal)){ FilePO filePO = new FilePO(fileName, md5, fileSize); fileService.addFile(filePO); chunkService.deleteChunkByMd5(md5); return new Result(200,"文件上传成功",index); }else{ return new Result(201,"分片上传成功",index); } } @GetMapping("/fileList") public Result getFileList(){ logger.info("查询文件列表"); List fileList = fileService.selectFileList(); return new Result(201,"文件列表查询成功",fileList); }} 文件下载的流程图如图8所示,顺序图如图9所示
文件下载是首先,前端向后端发送分片下载的请求,请求的responseType设为blob(Binary large Object) ,然后后端通过RandomAccess类读取指定字节的内容,再写入到响应的文件流中。
浏览器前端的请求的分片数据,会暂时保存在“C:\Users\用户名\AppData\Local\Microsoft\Edge\User Data\Default\blob_storage\”中,(请确保c盘有足够的空间),当所有分片下载完成,会合并成一个大文件(很快),分片不是放在内存中,所以不用担心文件太大是不是不行。
,
刷新浏览器,也会删除已经下载好的分片
当前端请求了所有的文件分片之后,再把所有的blob合并成一个blob
if (index == chunkTotal) { var resBlob = new Blob(file.blobList, { type: "application/octet-stream", }); // console.log("resb", resBlob); let url = window.URL.createObjectURL(resBlob); // 将获取的文件转化为blob格式 let a = document.createElement("a"); // 此处向下是打开一个储存位置 a.style.display = "none"; a.href = url; // 下面两行是自己项目需要的处理,总之就是得到下载的文件名(加后缀)即可 var fileName = file.name; a.setAttribute("download", fileName); document.body.appendChild(a); a.click(); //点击下载 document.body.removeChild(a); // 下载完成移除元素 window.URL.revokeObjectURL(url); // 释放掉blob对象 }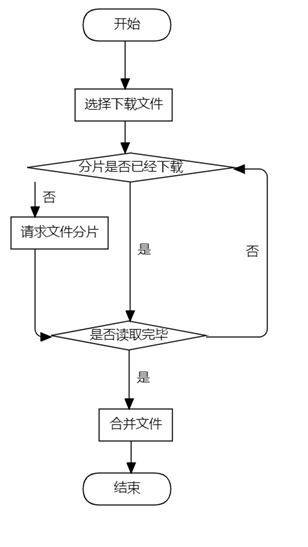
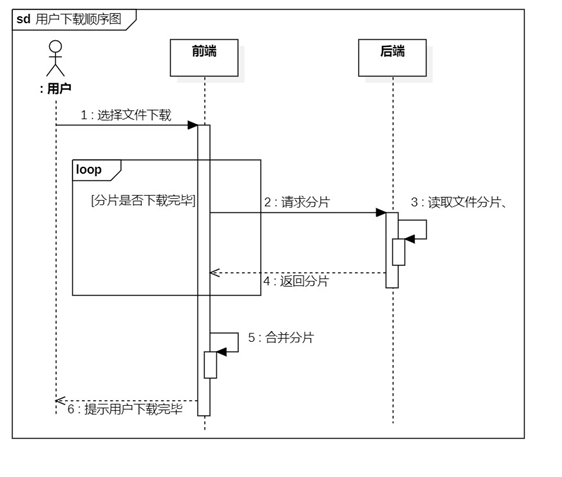
图9文件上传顺序图
前端代码
文件列表 {{ formatSize(scope.row) }} 下载 下载列表 {{ file.name }} {{ formatSize(file) }} {{ file.downloadSpeed }} 下载进度: 后端代码
package com.cugb.bigfileupload.controller;import com.cugb.bigfileupload.servie.ChunkService;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Value;import org.springframework.stereotype.Controller;import org.springframework.web.bind.annotation.*;import javax.servlet.ServletOutputStream;import javax.servlet.http.HttpServletResponse;import java.io.File;import java.io.IOException;import java.util.Objects;@Controller@CrossOriginpublic class DownLoadController { Logger logger = LoggerFactory.getLogger(getClass()); @Value("${file.path}") private String filePath; @Autowired private ChunkService chunkService; @PostMapping("/download") public void download(@RequestParam("md5") String md5, @RequestParam("fileName") String fileName, @RequestParam("chunkSize") Integer chunkSize, @RequestParam("chunkTotal") Integer chunkTotal, @RequestParam("index")Integer index, HttpServletResponse response) { String[] splits = fileName.split("\\."); String type = splits[splits.length - 1]; String resultFileName = filePath + md5 + "." + type; File resultFile = new File(resultFileName); long offset = (long) chunkSize * (index - 1); if(Objects.equals(index, chunkTotal)){ offset = resultFile.length() -chunkSize; } byte[] chunk = chunkService.getChunk(index, chunkSize, resultFileName,offset); logger.info("下载文件分片" + resultFileName + "," + index + "," + chunkSize + "," + chunk.length+","+offset);// response.addHeader("Access-Control-Allow-Origin","Content-Disposition"); response.addHeader("Content-Disposition", "attachment;filename=" + fileName); response.addHeader("Content-Length", "" + (chunk.length)); response.setHeader("filename", fileName); response.setContentType("application/octet-stream"); ServletOutputStream out = null; try { out = response.getOutputStream(); out.write(chunk); out.flush(); out.close(); } catch (IOException e) { e.printStackTrace(); } }}3.1 概念结构设计
数据库设计只有俩个表,一个file表来记录已经完整上传的文件信息,一个chunk表用来记录还未上传完成的分片信息

上传页面如图13所示,有一个“选择上传文件”的按钮,下面是显示正在上传文件的列表
图13 上传页面首页
我们选择要上传的文件,确认上传,首先会显示解析进度,当解析完成后,就会开始上传,并显示上传进度和速度;同时,我们可以选择多个文件一同上传;在上传的同时我们还可以暂停上传。如图14所示
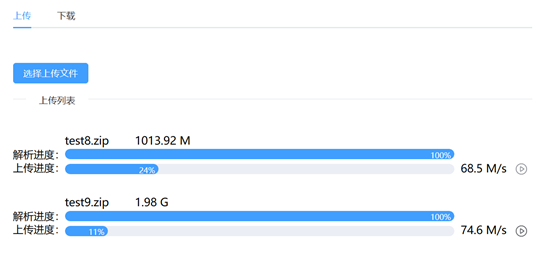
图14 上传文件中
当文件上传成功之后,就会弹窗提示文件上传成功。如图15所示

图15 文件上传成功
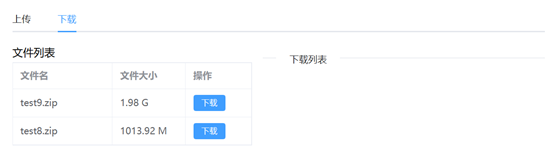
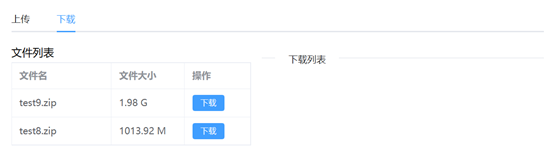
文件下载页面如图16所示,左边是可以下载文件的列表,右边是下载中的文件
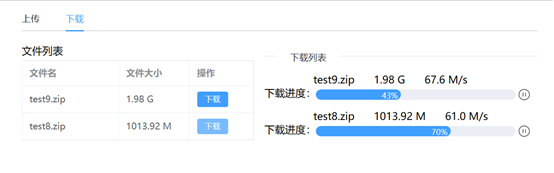
当所有的分片下载完成后,前端会将所有的分片合并成一个文件。如图18所示
来源地址:https://blog.csdn.net/weixin_50799082/article/details/128547482









