
低代码机器学习工具。中国人工智能发展迅猛,中国政府也高度重视人工智能领域的发展。预计到2020年,中国人工智能产业规模将超过1500亿元,带动相关产业规模超过1万亿元。2017年全球新兴人工智能项目中,中国占据51%,数量上已经超越美国。但全球人工智能人才储备,中国却只有5%左右,人工智能的人才缺口超过500万。
通常,要开发机器学习模型并将该模型部署到可以在操作上使用的状态,需要对编程有深入的了解,并且需要充分了解其背后的算法。
机器学习有潜力帮助解决企业和整个世界范围内的各种问题。通常,要开发机器学习模型并将该模型部署到可以在操作上使用的状态,需要对编程有深入的了解,并且需要充分了解其背后的算法。

这将机器学习的使用限制在一小部分人中,因此也限制了可以解决的问题数量。
幸运的是,在过去的几年中,涌现了许多库和工具,这些库和工具减少了模型开发所需的代码量,或者在某些情况下完全消除了代码开发。 这为非数据科学家(如分析师)发挥了利用机器学习功能的潜力,并允许数据科学家更快地对模型进行原型制作。
这是一些我最喜欢的用于机器学习的低代码工具。
PyCaret
PyCaret是Python的包装器,用于流行的机器学习库,例如Scikit-learn和XGBoost。 它使仅需几行代码就能将模型开发为可部署状态。
可以通过pip安装Pycaret。 有关更详细的安装说明,请参阅PyCaret文档。
- pip install pycaret
PyCaret具有公共数据集的存储库,可以使用pycaret.datasets模块直接安装。 完整列表可在此处找到,但出于本教程的目的,我们将使用一个非常简单的数据集来解决称为"葡萄酒"数据集的分类任务。
PyCaret库包含一组模块,用于解决所有常见的机器学习问题,其中包括:
- 分类。
- 回归。
- 聚类。
- 自然语言处理。
- 关联规则挖掘。
- 异常检测。
要创建分类模型,我们需要使用pycaret.classification模块。 创建模型非常简单。 我们只需调用将Model ID作为参数的create_model()函数即可。 您可以在此处找到支持的型号及其对应ID的完整列表。 或者,您可以在导入适当的模块后运行以下代码以查看可用模型的列表。
- from pycaret.classification import *
- models()
 > A snapshot of models available for classification. Image by Author.
> A snapshot of models available for classification. Image by Author.
在调用create_model()之前,您首先需要调用setup()函数来为您的机器学习实验指定适当的参数。 在这里,您可以指定诸如测试序列拆分的大小以及是否在实验中实施交叉验证之类的内容。
- from pycaret.classification import *
- rf = setup(datadata = data,
- target = 'type',
- train_size=0.8)
- rf_model = create_model('rf')
create_model()函数将自动推断数据类型并使用默认方法处理这些数据类型。 运行create_model()时,您将收到以下输出,其中显示了推断的数据类型。

> Image by Author.
PyCaret将使用一组默认的预处理技术来处理诸如分类变量和估算缺失值之类的事情。 但是,如果您需要更定制的数据解决方案,则可以在模型设置中将它们指定为参数。 在下面的示例中,我更改了numeric_imputation参数以使用中位数。
- from pycaret.classification import *
- rf = setup(datadata = data,
- target = 'type',
- numeric_imputation='median')
- rf_model = create_model('rf')
对参数满意后,请按Enter键,模型将最终确定并显示性能结果网格。
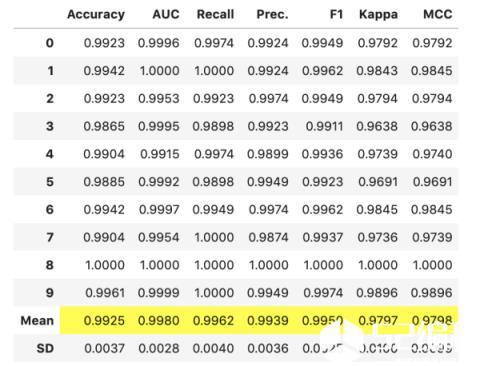
> Image by Author.
PyCaret还具有plot_model()函数,该函数显示模型性能的图形表示。
- plot_model(rf_model)
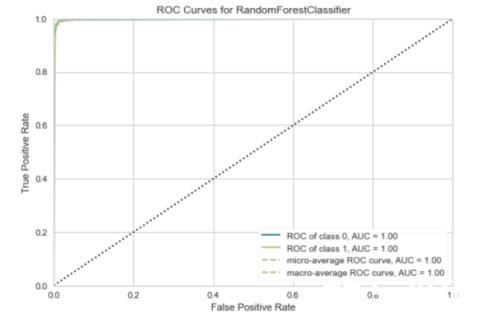
> Image by Author.
本教程刚刚展示了使用PyCaret库进行模型训练的基础。 还有更多功能和模块可提供完整的低码机器学习解决方案,包括功能工程,模型调整,持久性和部署。
BigQuery ML
Google在2018年发布了一个名为BigQuery ML的新工具。 BigQuery是Google的云数据仓库解决方案,旨在为数据分析师和科学家提供快速访问大量数据的途径。 BigQuery ML是一种工具,可让仅使用SQL从BigQuery数据仓库直接开发机器学习模型。
自从发布以来,BigQueryML已经发展到可以支持大多数常见的机器学习任务,包括分类,回归和聚类。 您甚至可以导入自己的Tensforflow模型以在工具中使用。
根据我自己的经验,BigQueryML是用于加速模型原型制作的极其有用的工具,并且还可以用作基于生产的系统来解决简单的问题。
为了简要介绍该工具,我将使用称为成人收入数据集的数据集来说明如何在BigQueryML中建立和评估逻辑回归分类模型。
该数据集可以在UCI机器学习存储库中找到,我正在使用以下Python代码以CSV文件的形式下载。
- url_data = 'https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data'
- column_names = ['age', 'workclass', 'fnlwgt', 'education', 'educational-num','marital-status',
- 'occupation', 'relationship', 'race', 'gender','capital-gain', 'capital-loss',
- 'hours-per-week', 'native-country','income']
- adults_data = pd.read_csv(url_data, names=column_names)
- adults_data.to_csv('adults_data.csv')
这是一个脚本,用于下载数据并导出为CSV文件。
如果您还没有Google Cloud Platform(GCP)帐户,则可以在此处创建一个。 最初注册时,您将获得$ 300的免费信用额度,足以试用以下示例。
进入GCP后,从下拉菜单导航至BigQuery网络用户界面。 如果您是第一次使用GCP,则需要创建一个项目并使用BigQuery进行设置。 Google快速入门指南在此处提供了很好的概述。
我先前下载的CSV文件可以直接上传到GCP中以创建表格。

> Image by Author.
您可以通过单击边栏中的表名称并选择预览来检查表中的数据。 现在,成人的数据就是BigQuery中的数据。
> Image by Author.
要针对这些数据训练模型,我们只需编写一个SQL查询,该查询从表中选择所有内容(*),将目标变量(收入)重命名为label,并添加逻辑以创建名为" adults_log_reg"的逻辑回归模型。
有关所有模型选项,请参见此处的文档。
- CREATE MODEL `mydata.adults_log_reg`
- OPTIONS(model_type='logistic_reg') AS
- SELECT *,
- ad.income AS label
- FROM
- `mydata.adults_data` ad
如果我们单击现在将出现在数据表旁边的侧栏中的模型,则可以看到对训练效果的评估。
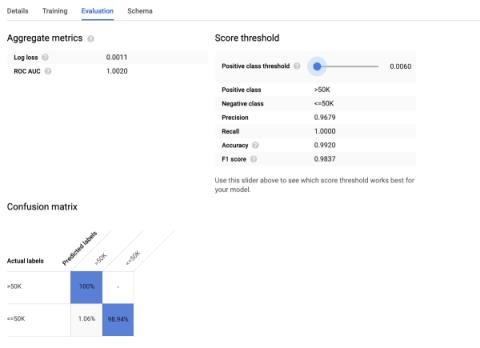
> Image by Author.
现在我们可以使用模型使用ML.PREDICT函数进行预测。
Fastai
众所周知,诸如Tensorflow之类的流行深度学习框架具有陡峭的学习曲线,对于初学者或非数据科学家而言,可能很难起步并运行它。 fastai库提供了一个高级API,使您可以用几行简单的代码来训练神经网络。
Fastai与Pytorch一起使用,因此您需要先安装这两个库,然后才能使用它。
- pip install pytorch
- pip install fastai
fastai库具有用于处理结构化数据和非结构化数据(例如文本或图像)的模块。 在本教程中,我们将使用fastai.tabular.all模块来解决我们之前使用的葡萄酒数据集的分类任务。
类似于PyCaret,fastai将通过嵌入层对非数字数据类型执行预处理。 为了准备数据,我们使用TabularDataLoaders帮助器函数。 在这里,我们具体说明了数据框的名称,列的数据类型以及我们要模型执行的预处理步骤。
要训练神经网络,我们只需使用tabular_learner()函数,如下所示。
- dl = TabularDataLoaders.from_df(data, y_names="type",
- cat_names = ['quality'],
- cont_names = ['fixed acidity', 'volatile acidity',
- 'citric acid', 'residual sugar',
- 'chlorides', 'free sulfur dioxide',
- 'total sulfur dioxide', 'density',
- 'pH', 'sulphates', 'alcohol'],
- procs = [Categorify, FillMissing, Normalize])
运行此代码后,将显示性能指标。

> Image by Author.
要使用模型进行预测,您可以简单地使用learning.predict(df.iloc [0])。
以培养掌握人工智能理论与工程技术的专门人才为目标,学习机器学习的理论和方法、深度学习框架、工具与实践平台、自然语言处理技术、语音处理与识别技术、视觉智能处理技术、国际人工智能专业领域最前沿的理论方法,培养人工智能专业技能和素养,构建解决科研和实际工程问题的专业思维、专业方法和专业嗅觉。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
软考中级精品资料免费领
 历年真题答案解析
历年真题答案解析 备考技巧名师总结
备考技巧名师总结 高频考点精准押题
高频考点精准押题
- 资料下载
- 历年真题
193.9 KB下载数265
191.63 KB下载数245
143.91 KB下载数1148
183.71 KB下载数642
644.84 KB下载数2756
相关文章
发现更多好内容- 如何在 Java 中定义一种方法?(java如何定义一种方法)
- Ruby代码安全:有效防护手段全指南
- 如何理解 Javascript Array.slice()方法的作用?(Javascript Array.slice()方法的作用是什么)
- 揭秘Ruby代码安全:常见的威胁与防护策略
- Java 环境究竟是什么含义?(java环境是什么意思)
- 在 Java 中,keystore 究竟有哪些作用呢?(java中keystore的作用是什么)
- 在 Java 中,三个点(...)具体代表什么含义呢?(java中三个点是什么意思)
- Java 中 Replace 和 ReplaceAll 的区别究竟在哪里?(Java中的Replace和ReplaceAll有什么区别)
- 如何有效提升 Java con 的查询效率?(如何提高java con的查询效率)
- 提升Ruby代码安全性:全面攻略
猜你喜欢
AI推送时光机人工智能低代码机器学习工具

人工智能机器学习算法

PHP学习笔记:人工智能与机器学习
pyCaret效率倍增开源低代码的python机器学习工具
人工智能、机器学习和自动化





