
1.SQL分类
DDL(Data Definition Languages、数据定义语言),这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。主要的语句关键字包括 CREATE 、 DROP 、 ALTER 等。
2.DML(Data Manipulation Language、数据操作语言),用于添加、删除、更新和查询数据库记录,并检查数据完整性。主要的语句关键字包括 INSERT 、 DELETE 、 UPDATE 、 SELECT 等。
3.SELECT是SQL语言的基础,最为重要。
DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括 GRANT 、 REVOKE 、 COMMIT 、 ROLLBACK 、 SAVEPOINT 等。
2.规则与规范
SQL 可以写在一行或者多行。为了提高可读性,各子句分行写,必要时使用缩进
2.每条命令以 ; 或 \g 或 \G 结束
3.关键字不能被缩写也不能分行
4.关于标点符号
必须保证所有的()、单引号、双引号是成对结束的
必须使用英文状态下的半角输入方式
字符串型和日期时间类型的数据可以使用单引号(’ ')表示
列的别名,尽量使用双引号(" "),而且不建议省略as
2.1 SQL大小写规范 (建议遵守)
MySQL 在 Windows 环境下是大小写不敏感的
MySQL 在 Linux 环境下是大小写敏感的
数据库名、表名、表的别名、变量名是严格区分大小写的 关键字、函数名、列名(或字段名)、列的别名(字段的别名) 是忽略大小写的。
推荐采用统一的书写规范: 数据库名、表名、表别名、字段名、字段别名等都小写 SQL 关键字、函数名、绑定变量等都大写
2.2 注 释
可以使用如下格式的注释结构
单行注释:#注释文字(MySQL特有的方式)单行注释:-- 注释文字(--后面必须包含一个空格。)多行注释:2.3 命名规则
数据库、表名不得超过30个字符,变量名限制为29个
2.必须只能包含 A–Z, a–z, 0–9, _共63个字符
数据库名、表名、字段名等对象名中间不要包含空格
3.同一个MySQL软件中,数据库不能同名;同一个库中,表不能重名;同一个表中,字段不能重名
4.必须保证你的字段没有和保留字、数据库系统或常用方法冲突。如果坚持使用,请在SQL语句中使用’ '(着重号)引起来
5.保持字段名和类型的一致性,在命名字段并为其指定数据类型的时候一定要保证一致性。假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了
3.基本SELECT语句
3.1 SELECT…
SELECT 1; #没有任何子句SELECT 9/2; #没有任何子句3.2 SELECT … FROM
SELECT 标识选择哪些列FROM 标识从哪个表中选择选择全部列
SELECT *FROM departments;3.3 去除重复行
在SELECT语句中使用关键字DISTINCT去除重复行
SELECT DISTINCT department_idFROM employees;3.4 空值参与运算
所有运算符或列值遇到null值,运算的结果都为null 这里你一定要注意,在 MySQL 里面, 空值不等于空字符串。一个空字符串的长度是0,而一个空值的长度是空。而且,在 MySQL 里面,空值是占用空间的。
3.5着重号
我们需要保证表中的字段、表名等没有和保留字、数据库系统或常用方法冲突。如果真的相同,请在SQL语句中使用一对``(着重号)引起来。
3.6显示表结构
使用DESCRIBE 或 DESC 命令,表示表结构。
DESCRIBE employees;或DESC employees;其中,各个字段的含义分别解释如下:
Field:表示字段名称。
Type:表示字段类型,这里 barcode、goodsname 是文本型的,price 是整数类型的。
Null:表示该列是否可以存储NULL值。
Key:表示该列是否已编制索引。PRI表示该列是表主键的一部分;UNI表示该列是UNIQUE索引的一部分;MUL表示在列中某个给定值允许出现多次。
Default:表示该列是否有默认值,如果有,那么值是多少。
Extra:表示可以获取的与给定列有关的附加信息,例如AUTO_INCREMENT等。
3.7 WHERE语句
SELECT 字段1,字段2FROM 表名WHERE 过滤条件# WHERE 过滤条件 使用WHERE 子句,将不满足条件的行过滤掉# WHERE子句紧随 FROM子句4.运算符
4.1算术运算符
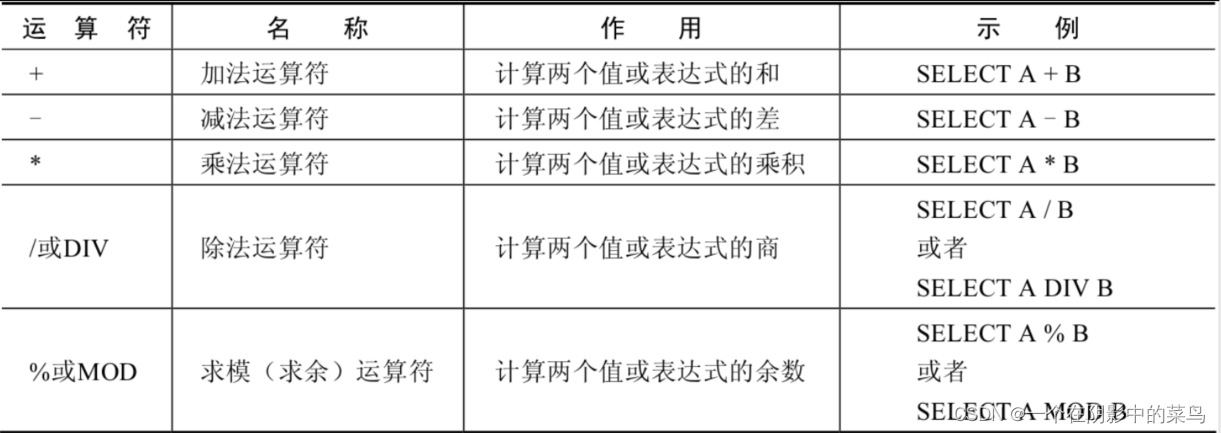
4.2比较运算符
符号运算符

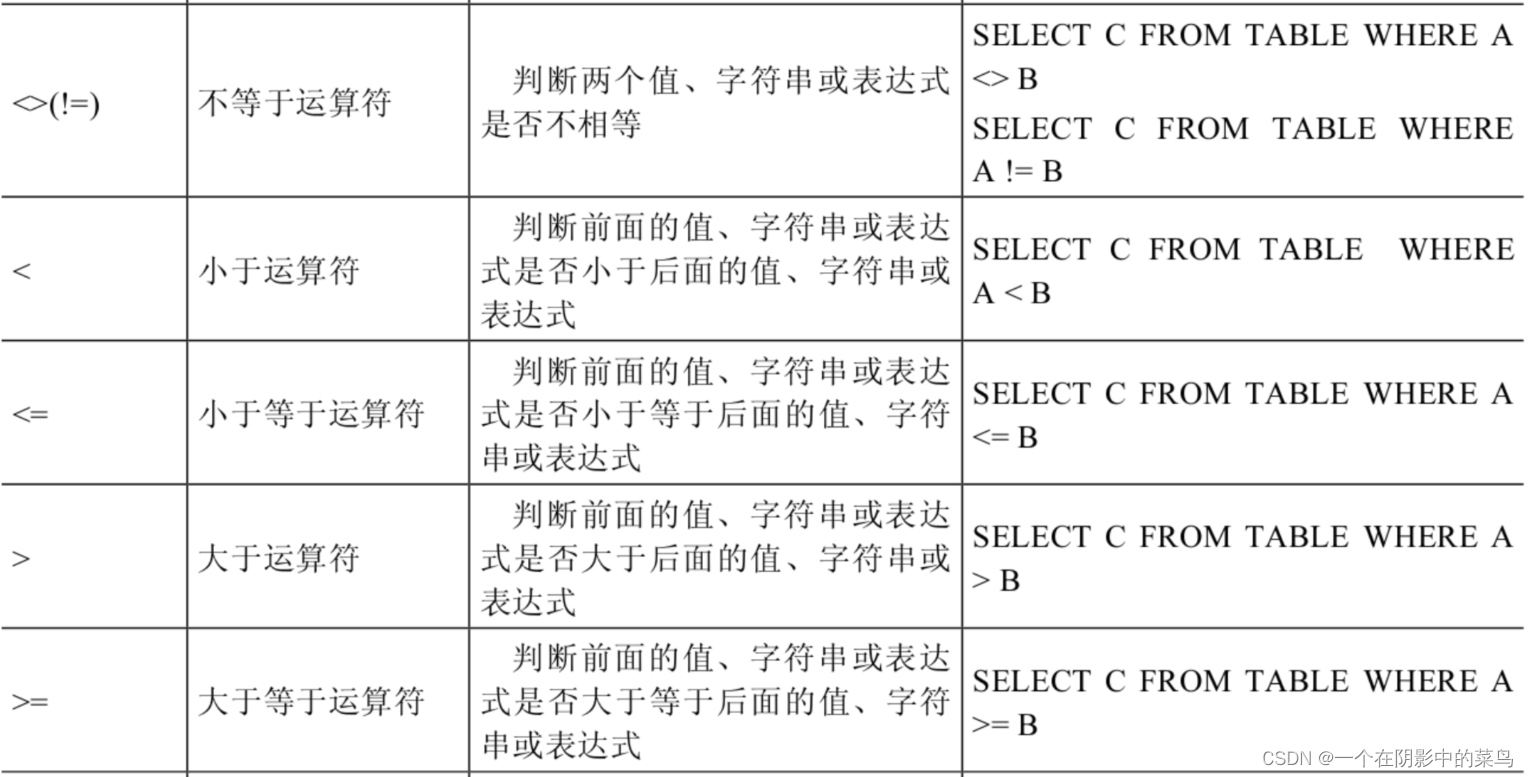
非符号运算符
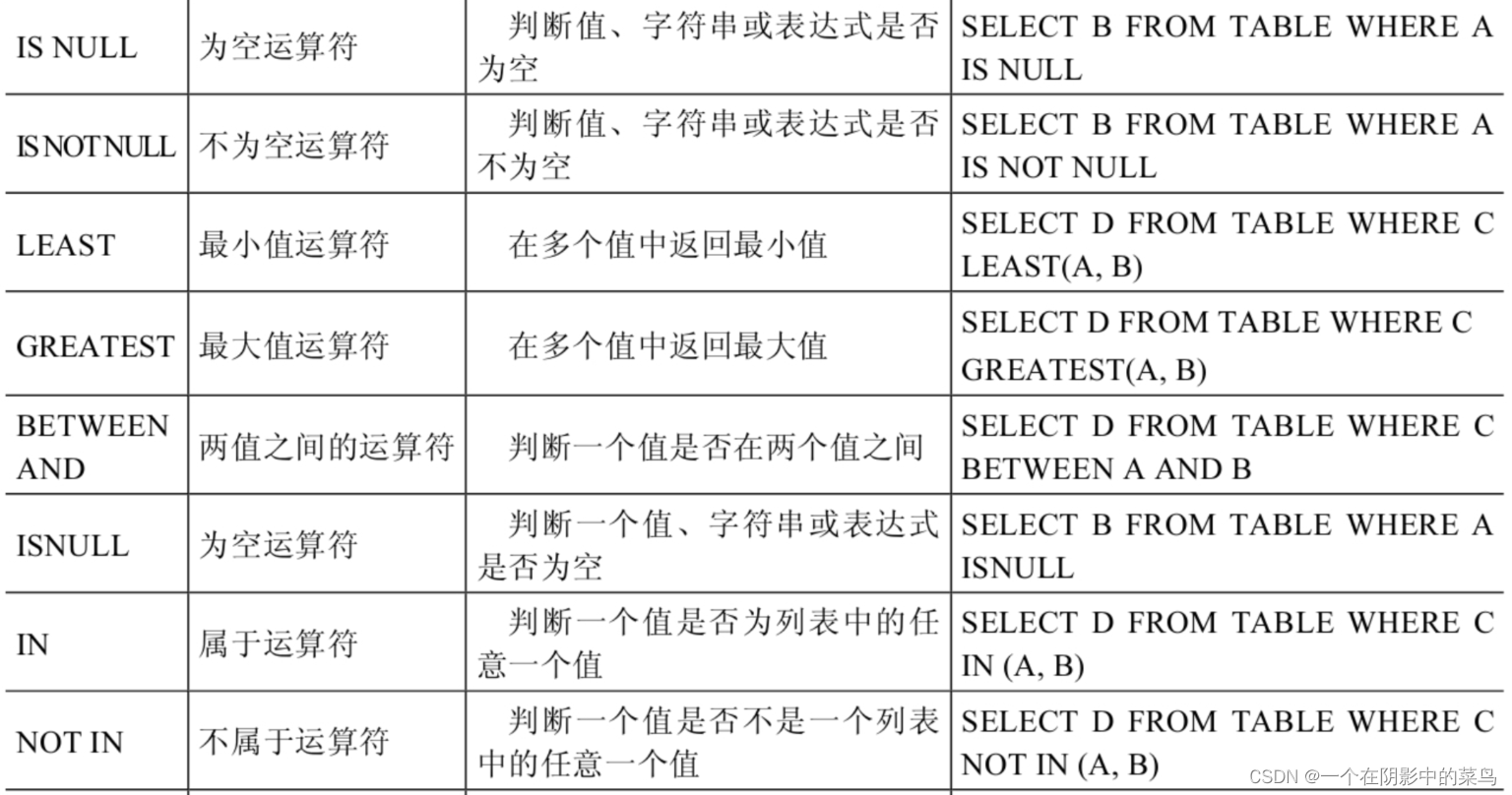

4.3逻辑运算符

4.4 位运算符
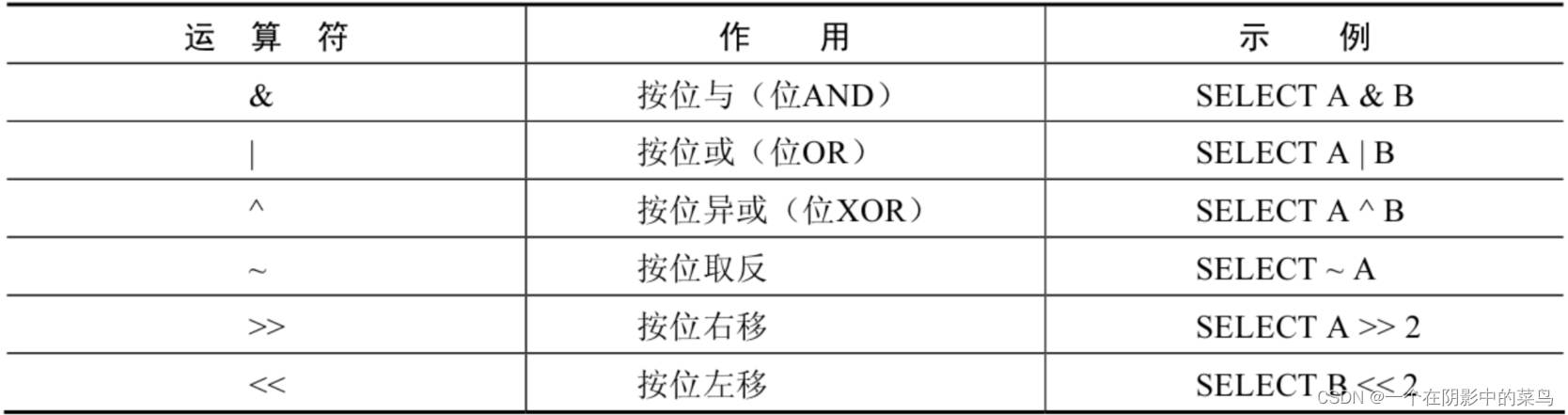
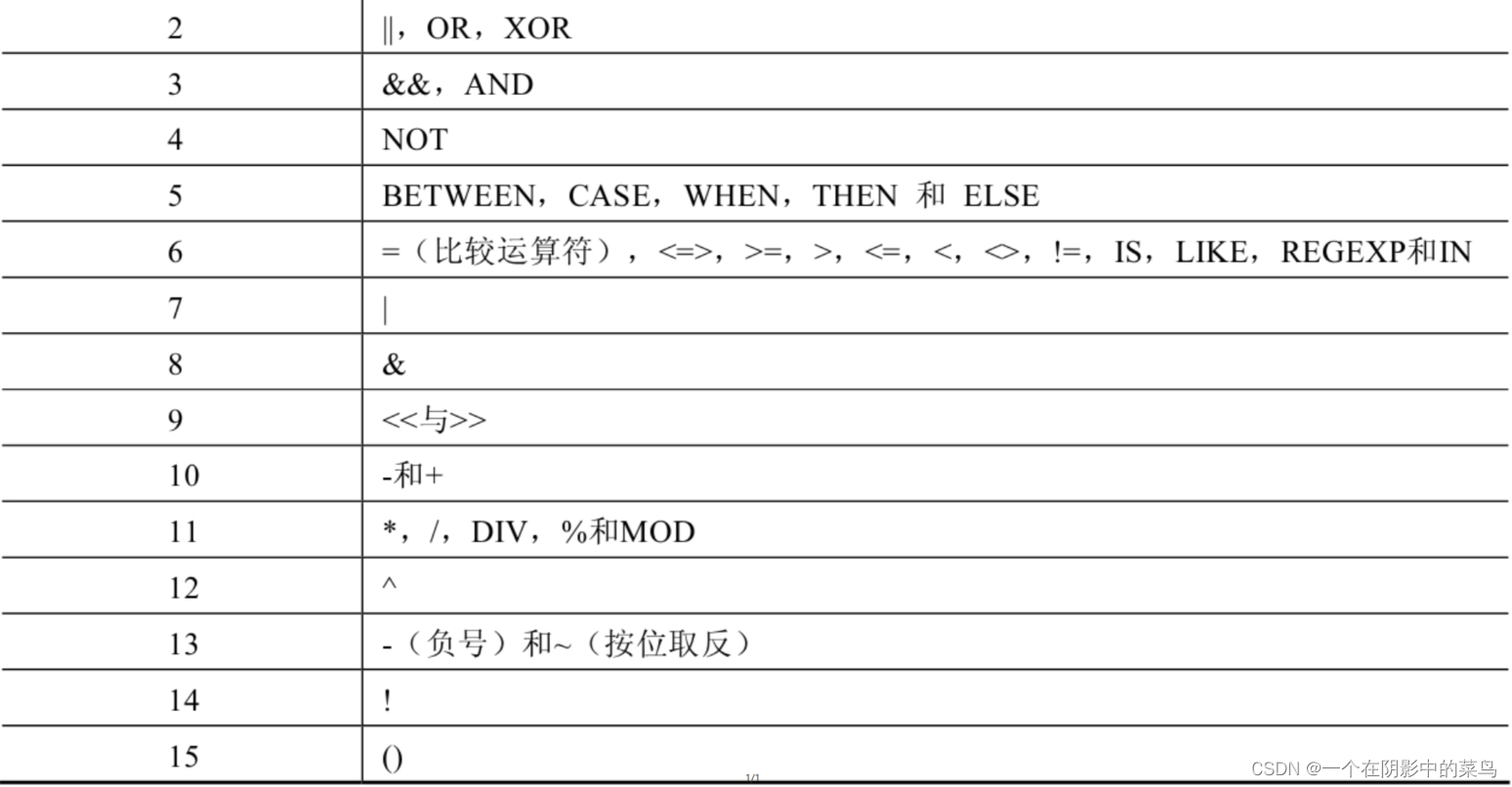
4.5 运算符的优先级

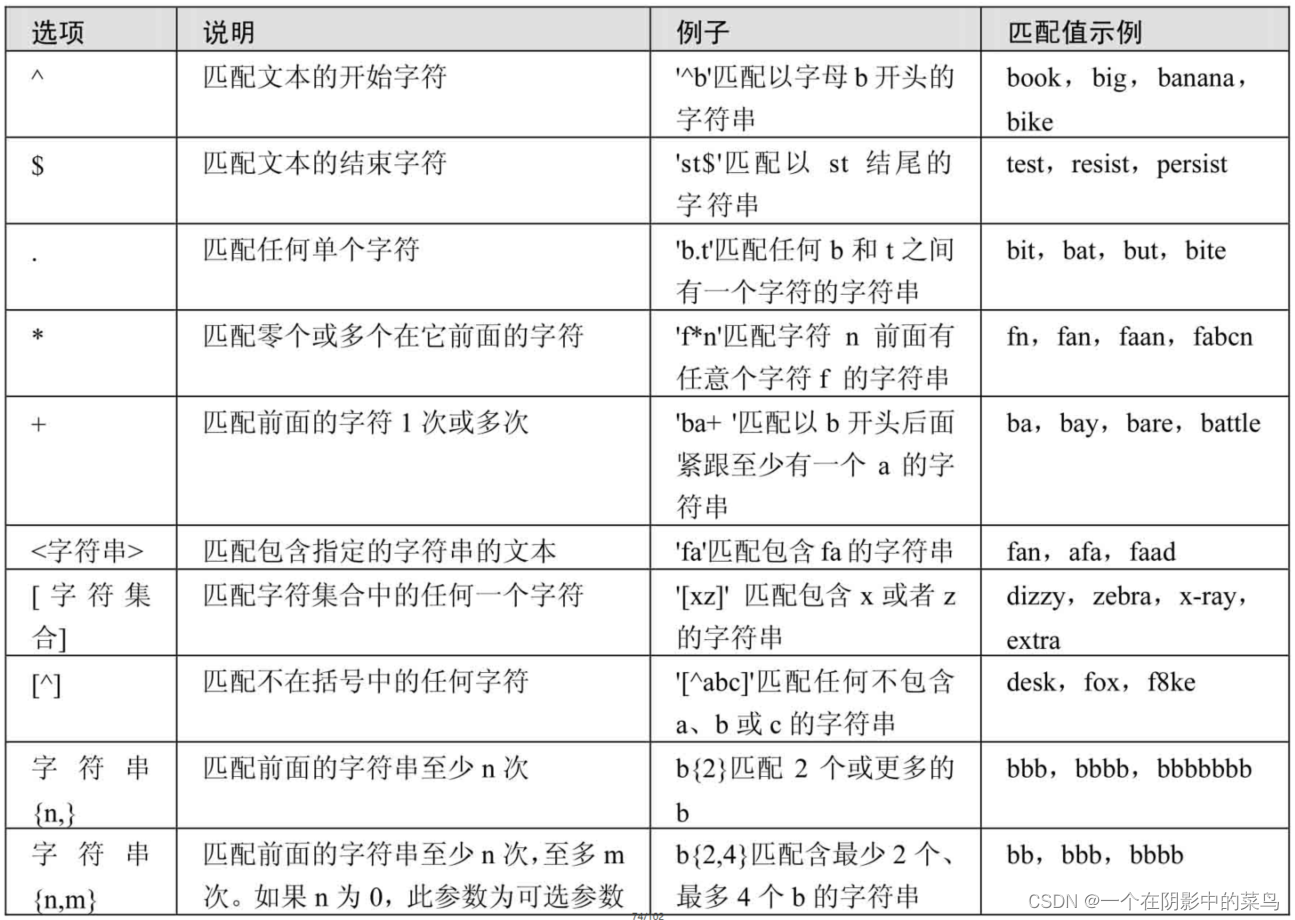
4.6正则表达式
MySQL中使用REGEXP关键字指定正则表达式的字符匹配模式。下表列出了REGEXP操作符中常用字符匹配列表
5. 排序与分页
ORDER BY
ASC(ascend): 升序
DESC(descend):降序
ORDER BY 子句在SELECT语句的结尾。
6.分页
LIMIT
LIMIT [位置偏移量,] 行数
分页显式公式:(当前页数-1)*每页条数,每页条数
注意:LIMIT 子句必须放在整个SELECT语句的最后!
7.多表查询
WHERE 加入有效的连接条件
示例
ELECT table1.column, table2.columnFROM table1, table2WHERE table1.column1 = table2.column2; #连接条件等值连接
多个连接条件与 AND 操作符
2:区分重复的列名
多个表中有相同列时,必须在列名之前加上表名前缀。
在不同表中具有相同列名的列可以用 表名 加以区分。
3.表的别名
使用别名可以简化查询。
列名前使用表名前缀可以提高查询效率。
4.连接多个表
连接 n个表,至少需要n-1个连接条件。
非等值连接(BETWEEN)
自连接
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
2.外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的
行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。
如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表 。
内连接(INNER JOIN)
SELECT 字段列表FROM A表 INNER JOIN B表ON 关联条件WHERE 等其他子句;外连接(OUTER JOIN)
左外连接(LEFT OUTER JOIN)
#实现查询结果是ASELECT 字段列表FROM A表 LEFT JOIN B表ON 关联条件WHERE 等其他子句;右外连接(RIGHT OUTER JOIN)
SELECT 字段列表FROM A表 RIGHT JOIN B表ON 关联条件WHERE 等其他子句;满外连接(FULL OUTER JOIN)
UNION的使用
SELECT column,... FROM table1UNION [ALL]SELECT column,... FROM table2UNION 操作符返回两个查询的结果集的并集,去除重复记录。
UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
SQL JOINS
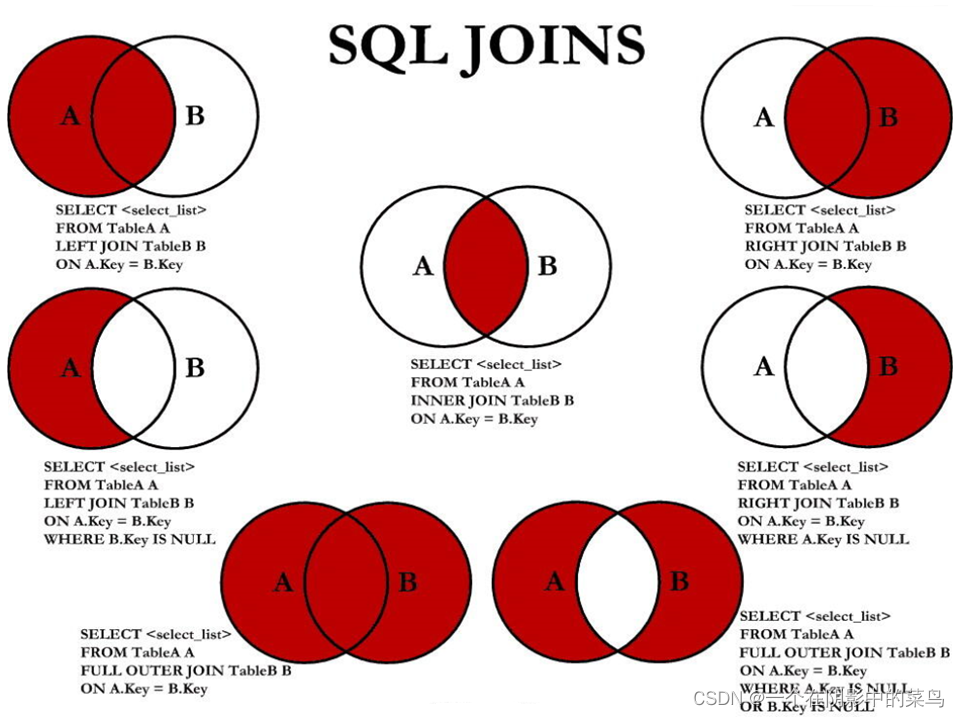
示例
#中图:内连接 A∩BSELECT employee_id,last_name,department_nameFROM employees e JOIN departments dON e.`department_id` = d.`department_id`;#左上图:左外连接SELECT employee_id,last_name,department_nameFROM employees e LEFT JOIN departments dON e.`department_id` = d.`department_id`;#右上图:右外连接SELECT employee_id,last_name,department_nameFROM employees e RIGHT JOIN departments dON e.`department_id` = d.`department_id`;#左中图:A - A∩BSELECT employee_id,last_name,department_nameFROM employees e LEFT JOIN departments dON e.`department_id` = d.`department_id`WHERE d.`department_id` IS NULL#右中图:B-A∩BSELECT employee_id,last_name,department_nameFROM employees e RIGHT JOIN departments dON e.`department_id` = d.`department_id`WHERE e.`department_id` IS NULL左中图右中图左下图#左下图:满外连接# 左中图 + 右上图 A∪BSELECT employee_id,last_name,department_nameFROM employees e LEFT JOIN departments dON e.`department_id` = d.`department_id`WHERE d.`department_id` IS NULLUNION ALL #没有去重操作,效率高SELECT employee_id,last_name,department_nameFROM employees e RIGHT JOIN departments dON e.`department_id` = d.`department_id`;#右下图#左中图 + 右中图 A ∪B- A∩B 或者 (A - A∩B) ∪ (B - A∩B)SELECT employee_id,last_name,department_nameFROM employees e LEFT JOIN departments dON e.`department_id` = d.`department_id`WHERE d.`department_id` IS NULLUNION ALLSELECT employee_id,last_name,department_nameFROM employees e RIGHT JOIN departments dON e.`department_id` = d.`department_id 8. 子查询
子查询(内查询)在主查询之前一次执行完成。
子查询的结果被主查询(外查询)使用 。
注意事项
子查询要包含在括号内
将子查询放在比较条件的右侧
单行操作符对应单行子查询,多行操作符对应多行子查询
EXISTS 与 NOT EXISTS关键字
关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
1.如果在子查询中不存在满足条件的行:
条件返回 FALSE
继续在子查询中查找
2.如果在子查询中存在满足条件的行:
不在子查询中继续查找
条件返回 TRUE
NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
来源地址:https://blog.csdn.net/qq_43482410/article/details/129700086













