
这篇文章,讲的是“信号与编码”,不会的小伙伴要认真的阅读了。这里面都是一些精华。
模拟信号与调制方式、波特率
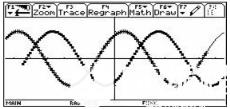
电路中,信号的传输从接收端在时间来看是一个波形。那么发送端就是根据数据生成这个波形,接收端就是拿到波形分析出来数据。这整个过程其实就是数据到电波的编解码,中间的载体是电路、电缆。
实际的模拟信号是一个随时间连续的曲线。这条曲线类似正弦波,有波幅,有波峰波谷,有频率。我们一般用其变化来表示数据,这就是调制方式。用频率变化来表示就是调频,用波幅来表示就是调幅。
波特率(Baudrate)即调制速率,指的是信号被调制以后在单位时间内的变化,即单位时间内载波参数变化的次数。它是对符号传输速率的一种度量,1波特即指每秒传输1个符号。
数字信号与采样定理
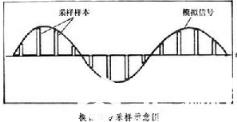
而实际数据是离散的,我们能表达的数据也是离散的。怎么来表达这样的一个连续的模拟信号呢?答案就是离散化,采样。采集足够多的离散的信息点,再把这些点串起来,就能近似的还原出来这个波形。而且直觉上来讲,采集到的点越多,还原出来的波形越接近实际情况。这个离散的数据就是数字信号。
一般情况下,例如我们在波形中用波峰表示数据1,波谷表示数据0。这样的话,如下图,每个波峰内采集到4个点,或者在加一个点达到5个点,一样不大。都能还原出来这个波形所表示的数据。但只采集一个点不行,比如正好都采集到穿越x轴附近的点,这样的所有采样点连接起来的波形近似于一条直线。
采样定理告诉我们:在进行模拟/数字信号的转换过程中,当采样频率fs.max大于信号中最高频率fmax的2倍时(fs.max>=2fmax),采样之后的数字信号完整地保留了原始信号中的信息,一般实际应用中保证采样频率为信号最高频率的5~10倍;采样定理又称奈奎斯特定理。
编码常识
简介
GB编码标准中,比较常用的是GB2312和GBK两种,GB2312是GBK的一个子集,GB2312编码范围是0xA1A1-0xFEFE,如果纯粹的GB2312编码,处理起来是十分简单的,但处理GBK字符集时有些小的提示,先说说GBK编码的标准吧:
GBK采用双字节表示,总体编码范围为8140-FEFE,首字节在81-FE之间,尾字节在40-FE之间,剔除xx7F一条线。总计23940个码位,共收入21886个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个。
编码分类
1.汉字区。包括:
a.GB2312汉字区。即GBK/2:B0A1-F7FE。收录GB2312汉字6763个,按原顺序排列。
b.GB13000.1扩充汉字区。包括:
(1)GBK/3:8140-A0FE。收录GB13000.1中的CJK汉字6080个。
(2)GBK/4:AA40-FEA0。收录CJK汉字和增补的汉字8160个。
CJK汉字在前,按UCS代码大小排列;增补的汉字(包括部首和构件)在后,按《康熙字典》的页码/字位排列。
2.图形符号区。包括:
a.GB2312非汉字符号区。即GBK/1:A1A1-A9FE。其中除GB2312的符号外,
还有10个小写罗马数字和GB12345增补的符号。计符号717个。
b.GB13000.1扩充非汉字区。即GBK/5:A840-A9A0。BIG-5非汉字符号、结构符和“○”排列在此区。计符号166个。
3.用户自定义区:分为(1)(2)(3)三个小区。
(1)AAA1-AFFE,码位564个。
(2)F8A1-FEFE,码位658个。
(3)A140-A7A0,码位672个。
第(3)区尽管对用户开放,但限制使用,因为不排除未来在此区域增补新字符的可能性。
这里有几个小技巧:
一、在php中,字符编码是按所发送的编码为准的,因此使用的就是用户输入的编码,不会自动改变,但在asp中,默认的编码是unicode,这样我们很容易就能得到gbk->unicode的编码对照表,这样即使在毫无基础库的情况下也能很容易的实现gbk到utf-8的转换了;
二、由于GBK是高位最低数值是0x40,即是64,因此,有时候组织一些涉及中文的字串时,分割字符最好用64之前的ascii码,这样在任意情况下替换或分割都不会出现乱码,比较常用的是","、";"、":"、""、""、"",这些字符永远都不会给gb编码添乱。
脉冲信号与脉冲编码调制
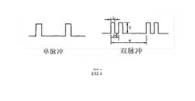
脉冲信号是一种离散信号,形状多种多样,与普通模拟信号(如正弦波)相比,波形之间在时间轴不连续(波形与波形之间有明显的间隔)但具有一定的周期性是它的特点。最常见的脉冲波是矩形波(也就是方波)。脉冲信号可以用来表示信息,也可以用来作为载波,比如脉冲调制中的脉冲编码调制(PCM),脉冲宽度调制(PWM)等等,还可以作为各种数字电路、高性能芯片的时钟信号。
脉冲编码调制(PulseCodeModulation)是一种对模拟信号数字化的取样技术,将模拟语音信号变换为数字信号的编码方式,特别是对于音频信号。例如PCM对信号每秒钟取样8000次;每次取样为8个位,总共64kbPS。
脉冲编码调制主要经过3个过程:抽样、量化和编码。抽样过程将连续时间模拟信号变为离散时间、连续幅度的抽样信号,量化过程将抽样信号变为离散时间、离散幅度的数字信号,编码过程将量化后的信号编码成为一个二进制码组输出。
所谓量化,就是把经过抽样得到的瞬时值将其幅度离散,即用一组规定的电平,把瞬时抽样值用最接近的所谓编码,就是用一组二进制码组来表示每一个有固定电平的量化值。
时钟信号与时钟频率
时钟信号可以看做脉冲信号的一个基准。以时钟频率作为基准,就可以把脉冲信号里的数据按频率周期分割开来。见下面的曼彻斯特编码。
在通信网络中,接收端需要从接收数据中恢复时钟信息来保证同步,这就需要线路中所传输的二进制码流有足够多的跳变,即不能有过多连续的高电平或低电平,否则无法提取时钟信息。这样没有一个参照的话,两个连续的低电平和两个连续的高电平,与一个低电平和一个高电平,看起来是一样的、无法区分。而且对于电路中的隔直电容来说,连续多个高电平会导致被看做直流,后面的一部分会直接被截断。
曼彻斯特编码与差分曼彻斯特编码
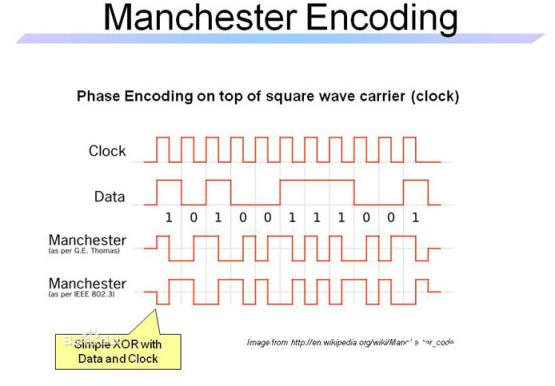
曼彻斯特编码是一种混合了时钟信号和数字信号的编码。这样同步时钟就直接被加入到了信号中,使得每一个表示数据位的码元都至少会有一个跳变,即最多出现两个连续的高电平或低电平(这点很重要)。缺点是每个码元变成了两位,数据传输速率也就是比特率只有原来的一半。
编码方式为每个周期中间位置的跳变从高到低为1,从低到高为0。上图的第四行表示反相的曼彻斯特编码。
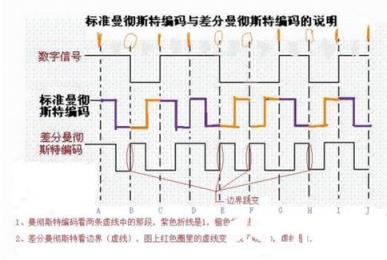
差分曼彻斯特编码跟曼彻斯特编码一样,每个周期的中间部分都有跳变。只做了一个很小的变动,如果每个周期开始处有跳动,表示0,否则表示1。这样就跟上升或下降没有直接关系。
4B/5B编码
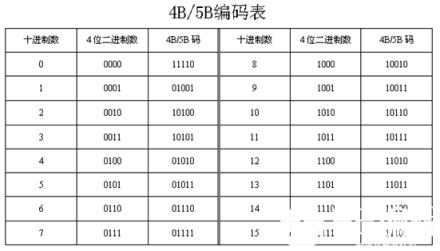
针对曼彻斯特编码只有一半的传输速度的问题,在放宽约束条件下,出现了4B\\5B编码(类似base64)。
原理大概如下,4个bit可以表示16个不同组合,而5个bit可以表示32个组合,从32个不同组合里,取出16个相对均匀的组合来,跟原来的4bit表示的16个情况一一对应。这样所有的数据byte(8bit),都分成高位4bit和低位4bit,每个4bit再按对照表表示成5bit。产生的信号电平就相对均衡,最多有7个连续的1(0x7F),3个连续的0(0x21)。
虽然其均匀性不如曼彻斯特编码,其传输效率,从4位变成5位,效率为原来的80%,比曼彻斯特编码高出了30%。
简单交叉编码:1001编码
有时候我们发现针对多个连续出现的高电平,会导致信号衰弱的厉害,这时候曼彻斯特瞒报很有效。其实我们可以简单的简化一下此编码。
方法如下:
所有的数据二进制化比如11000110…
在每个1后添加一个0,每个0后添加一个1
前面的数据就成了1010010101101001…黑色为原数据,蓝色为补充的数据。
解码数据时,直接按位,去掉偶数位上的数据,得到的数据即为原数据的二进制表示。
可以分别对原数据、奇偶数位做奇偶校验。如果数据错误一位,可从另一部分还原数据。
看完这篇文章,自己是不是更清晰了,如果有疑问可以提出来和大家一起交流,还希望大家多多支持编程学习网! 如果想了解更多这方面的知识,随时可以登陆编程学习网哟~









