
这篇文章主要讲解了“python3 chromedrivers签到如何实现”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“python3 chromedrivers签到如何实现”吧!
爬虫一般是useragent,或者js脚本交互验算的方式来反机器人爬虫,只是很多反爬虫容易被侦测出来容易被拦截,这里有个思路可以用webdrivers来驱动浏览器去爬虫,这样就可以绕过大多数的防爬机制(有些高级的防反爬虫也不行,比如验证码,鼠标轨迹验证等技术这样chromedriver就不管用了)
用chrome浏览器举例
第一下载安装chrome浏览器并查明版本号。
┌──(kali㉿kali)-[~]
└─$ apt-get install google-chrome-stable
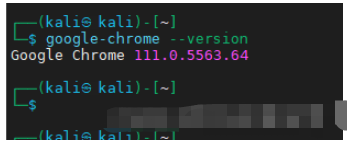
然后照着浏览器去下载相应的chromedriver
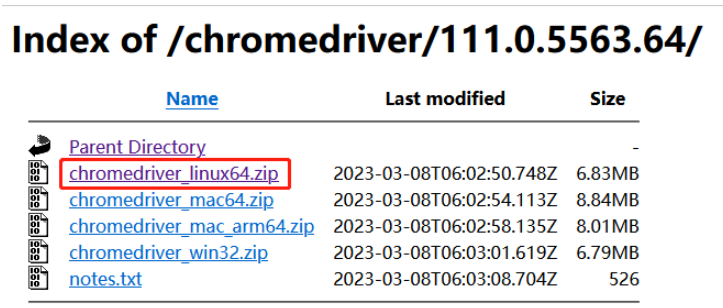
下载后解压,将里面的chromedriver 复制到/usr/bin/ 目录下面(pach环境变量里面)即可

下面开始写脚本
from time import sleepimport osfrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.keys import Keys option = webdriver.ChromeOptions() #设置chrome的浏览器选项 option.add_argument('--headless') #设施chrome选项为无窗口运行 driver = webdriver.Chrome(chrome_options=option) # 创建一个chrome浏览器,应用无窗口的配置。 driver.get("http://www.jsons.cn/ping/") #用chrome去访问网页 WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, 'txt_url')))#让chrome显式等待driver这个对象,并最多等待10秒,当界面出现'txt_url'这个元素后在继续往下 driver.find_element(By.XPATH, '//*[@id="txt_url"]').send_keys('ss111d.yqw5ey.dnslog.cn')#再出现//*[@id="txt_url"]这个元素后往这个元素里面填入ss111d.yqw5ey.dnslog.cn这个数值 driver.find_element(By.XPATH, '//*[@id="startbtn"]').click()#然后找到//*[@id="startbtn"] 这个按钮模拟点击它 sleep(1)#等待一秒后退出find_element(By.XPATH, '//*[@id="txt_url"]') 这个元素怎么来的?如下:

总的来说这个脚本就是用chrome 打开这个网站,然后输入这个dnslog的网址去ping一下。模仿人点击去测试网页

结果
其他:
下拉菜单如何选择?
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import Select # 创建一个 WebDriver 实例driver = webdriver.Chrome() # 访问网页driver.get("https://example.com") # 选择下拉框元素select_box = driver.find_element(By.ID, "my_select_box") # 初始化 Select 类select = Select(select_box) # 选择一个选项select.select_by_value("option_value") # 关闭 WebDriver 实例driver.quit()在最新版本的 Selenium Python 包中,推荐使用 find_element 方法的新形式,即指定查找方式的参数 By,以及对应的选择器表达式,具体有以下几种用法:
通过元素 ID 查找元素:find_element(By.ID, id_)
通过元素 name 查找元素:find_element(By.NAME, name)
通过元素 class name 查找元素:find_element(By.CLASS_NAME, name)
通过元素标签名查找元素:find_element(By.TAG_NAME, name)
通过元素链接文本查找元素:find_element(By.LINK_TEXT, text)
通过元素部分链接文本查找元素:find_element(By.PARTIAL_LINK_TEXT, text)
通过元素 CSS 选择器查找元素:find_element(By.CSS_SELECTOR, css_selector)
通过元素 XPath 查找元素:find_element(By.XPATH, xpath)
感谢各位的阅读,以上就是“python3 chromedrivers签到如何实现”的内容了,经过本文的学习后,相信大家对python3 chromedrivers签到如何实现这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是编程网,小编将为大家推送更多相关知识点的文章,欢迎关注!








