
但是对于 flink sql 的执行过程,大家还是不熟悉的。上节使用 ETL,group agg(sum,count等)简单聚合类 query 带大家走进一条 flink sql query 逻辑的世界。帮大家至少能够熟悉在 flink sql 程序运行时知道 flink 程序在干什么。
此节就是窗口聚合章节的第一篇,以一个最简单、最常用的分钟 tumble window 聚合案例给大家介绍其使用方式和原理。
由于 flink 1.13 引入了 window tvf,所以 1.13 和 1.12 及之前版本的实现不同。本节先介绍 flink 1.12 及之前的 tumble window 实现。这也是大家在引入 flink sql 能力时最常使用的。
本节依然从以下几个章节给大家详细介绍 flink sql 的能力。
目标篇-本文能帮助大家了解 flink sql 什么?
- 回顾上节的 flink sql 适用场景的结论
概念篇-先聊聊常见的窗口聚合
- 窗口竟然拖慢数据产出?
- 常用的窗口
实战篇-简单的 tumble window 案例和运行原理
- 先看一个 datastream 窗口案例
- flink sql tumble window 的语义
- tumble window 实际案例
- GeneratedWatermarkGenerator - flink 1.12.1
- BinaryRowDataKeySelector - flink 1.12.1
- AggregateWindowOperator - flink 1.12.1
总结与展望篇
先说说结论,以下这些结论已经在上节说过了,此处附上上节文章:
场景问题:flink sql 很适合简单 ETL,以及基本全部场景下的聚合类指标(本节要介绍的 tumble window 就在聚合类指标的范畴之内)。
语法问题:flink sql 语法其实是和其他 sql 语法基本一致的。基本不会产生语法问题阻碍使用 flink sql。但是本节要介绍的 tumble window 的语法就是略有不同的那部分。下面详细介绍。
运行问题:查看 flink sql 任务时的一些技巧,以及其中一些可能会碰到的坑:
- 去 flink webui 就能看到这个任务目前在做什么。包括算子名称都会给直接展示给我们目前哪个算子在干啥事情,在处理啥逻辑。
- sql 的 watermark 类型要设置为 TIMESTAMP(3)。
- 事件时间逻辑中,sql api 和 datastream api 对于数据记录时间戳存储逻辑是不一样的。datastream api:每条记录的 rowtime 是放在 StreamRecord 中的时间戳字段中的。sql api:时间戳是每次都从数据中进行获取的。算子中会维护一个下标。可以按照下标从数据中获取时间戳。
2.目标篇-本文能帮助大家了解 flink sql tumble window 什么?
关于 flink sql tumble window 一般都会有以下问题。本文的目标也是为大家解答这些问题:
场景问题:场景问题就不必多说,datastream 在 tumble window 场景下的应用很多了,分钟级别聚合等常用场景
语法问题:flink sql 写 tumble window 任务时是一种与 hive sql 中没有的语法。下文详细介绍。
运行问题:使用一条简单的 tumble window sql 帮大家从 transformation、runtime 帮大家理解 tumble window 的整体运行机制。
理解误区:既然是 sql 必然要遵循 sql 语义,sql tumble window 聚合是输入多条,产出一条数据。并不像 datastream 那样可以在窗口 udf 中做到多对多。
在正式开始聊 tumble window 之前,先看看上节 flink sql 适用场景的结论。让大家先有 flink sql 的一个整体印象以及结论。
2.1.回顾上节的 flink sql 适用场景的结论
不装了,我坦白了,flink sql 其实很适合干的活就是 dwd 清洗,dws 聚合。
此处主要针对实时数仓的场景来说。flink sql 能干 dwd 清洗,dws 聚合,基本上实时数仓的大多数场景都能给覆盖了。
flink sql 牛逼!!!
但是!!!
经过博主使用 flink sql 经验来看,并不是所有的 dwd,dws 聚合场景都适合 flink sql(截止发文阶段来说)!!!
其实这些目前不适合 flink sql 的场景总结下来就是在处理上比 datastream 还是会有一定的损失。
先总结下使用场景:
dwd:简单的清洗、复杂的清洗、维度的扩充、各种 udf 的使用
dws:各类聚合
然后分适合的场景和不适合的场景来说,因为只这一篇不能覆盖所有的内容,所以本文此处先大致给个结论,之后会结合具体的场景详细描述。
适合的场景:
简单的 dwd 清洗场景
全场景的 dws 聚合场景
目前不太适合的场景:
复杂的 dwd 清洗场景:举例比如使用了很多 udf 清洗,尤其是使用很多的 json 类解析清洗
关联维度场景:举例比如 datastream 中经常会有攒一批数据批量访问外部接口的场景,flink sql 目前对于这种场景虽然有 localcache、异步访问能力,但是依然还是一条一条访问外部缓存,这样相比批量访问还是会有性能差距。
3.概念篇-先聊聊常见的窗口聚合
窗口聚合大家都在 datastream api 中很熟悉了,目前在实时数据处理的过程中,窗口计算可以说是最重要、最常用的一种计算方式了。
但是在抛出窗口概念之前,博主有几个关于窗口的小想法说一下。
3.1.窗口竟然拖慢数据产出?
一个小想法。
先抛结论:窗口会拖慢实时数据的产出,是在目前下游分析引擎能力有限的情况下的一种妥协方案。
站在数据开发以及需求方的世界中,当然希望所有的数据都是实时来的,实时处理的,实时产出的,实时展现的。
举个例子:如果你要满足一个一分钟窗口聚合的 pv,uv,或者其他聚合需求。
olap 数据服务引擎 就可以满足上述的实时来的,实时处理的,实时产出的,实时展现的的场景。flink 消费处理明细数据,产出到 kafka,然后直接导入到 olap 引擎中。查询时直接用 olap 做聚合。这其中是没有任何窗口的概念的。但是整个链路中,要保障端对端精确一次,要保障大数据量情况下 olap 引擎能够秒级查询返回,更何况有一些去重类指标的计算,等等场景。把这些压力都放在 olap 引擎的压力是很大的。
因此在 flink 数据计算引擎中就诞生了窗口的概念。我们可以直接在计算引擎中进行窗口聚合计算,然后等到窗口结束之后直接把结果数据产出。这就出现了博主所说的窗口拖慢了实时数据产出的情况。而且窗口在处理不好的情况下可能会导致数据丢失。
关于上述两种情况的具体优劣选择,都由大家自行选择。上述只是引出博主一些想法。
3.2.常用的窗口
目前已知的窗口分为以下四种。
Tumble Windows2. Hop Windows3. Cumulate Windows4. Session Windows
这些窗口的具体描述直接见官网,有详细的说明。此处不赘述。
https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sql/queries/window-agg/
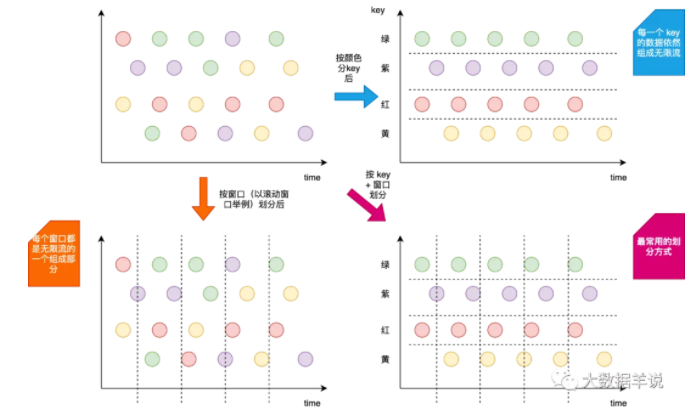
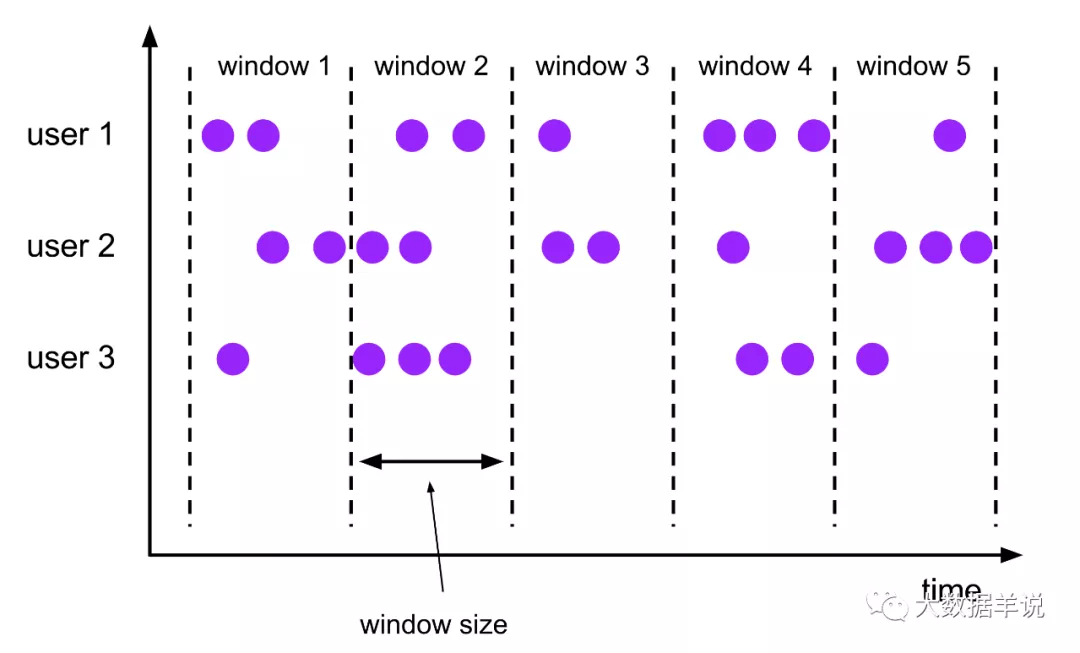
此处介绍下 flink 中常常会涉及到的两个容易混淆的概念就是:窗口 + key。这里来形象的说明下。
窗口:时间周期上面的划分。将无限流进行纵向切分,将无限流切分为一个一个的窗口,窗口相当于是无限流中的一段时间内的数据。
key:数据类别上面的划分。将无限流进行横向划分,相同 key 的数据会被划分到一组中,这个 key 的数据也是一条无限流。
如下图所示。
4.实战篇-简单的 tumble window 案例和运行原理
源码公众号后台回复flink sql tumble window 的奇妙解析之路获取。
4.1.先看一个 datastream 窗口案例
在介绍 sql tumble window 窗口算子执行案例之前,先看一个 datastream 中的窗口算子案例。其逻辑都是相通的。会对我们了解 sql tumble window 算子有帮助。
我们先看看 datastream 处理逻辑。
以下面这个为例。
- public class _04_TumbleWindowTest {
-
- public static void main(String[] args) throws Exception {
-
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
-
- env.setParallelism(1);
-
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
-
- env.addSource(new UserDefinedSource())
- .assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor
Integer , Long>>(Time.seconds(0)) { - @Override
- public long extractTimestamp(Tuple4
Integer, Long> element) { - return element.f3;
- }
- })
- .keyBy(new KeySelector
Integer , Long>, String>() { - @Override
- public String getKey(Tuple4
Integer, Long> row) throws Exception { - return row.f0;
- }
- })
- .window(TumblingEventTimeWindows.of(Time.seconds(10)))
- .sum(2)
- .print();
-
- env.execute("1.12.1 DataStream TUMBLE WINDOW 案例");
- }
-
- private static class UserDefinedSource implements SourceFunction
Integer, Long>> { -
- private volatile boolean isCancel;
-
- @Override
- public void run(SourceContext
Integer, Long>> sourceContext) throws Exception { -
- while (!this.isCancel) {
-
- sourceContext.collect(Tuple4.of("a", "b", 1, System.currentTimeMillis()));
-
- Thread.sleep(10L);
- }
-
- }
-
- @Override
- public void cancel() {
- this.isCancel = true;
- }
- }
- }
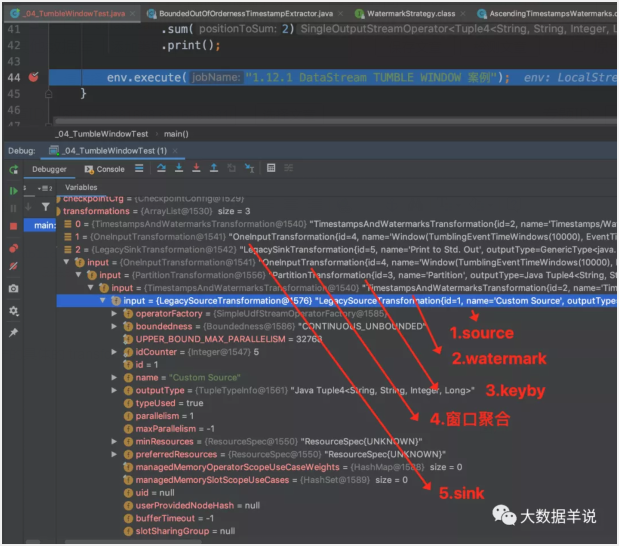
datastream 生产的具体的 transformation 如下图:
其中我们只关注最重要的 WindowOperator 算子。
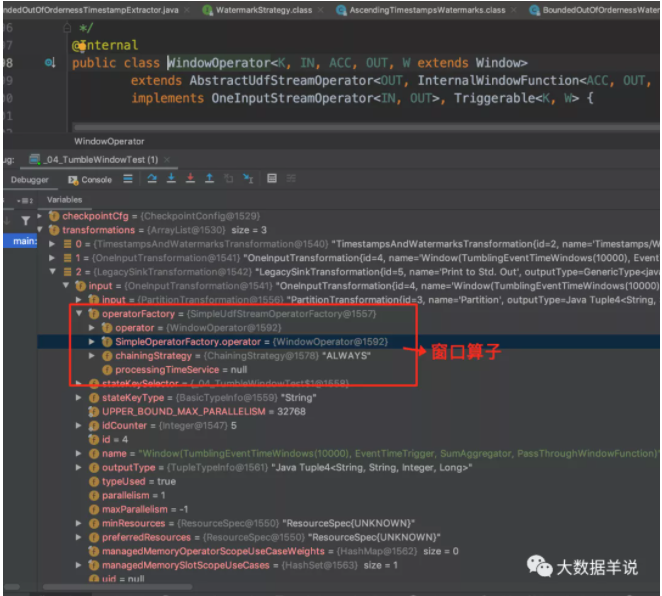
其中 WindowOperator 算子包含的重要属性如下图。
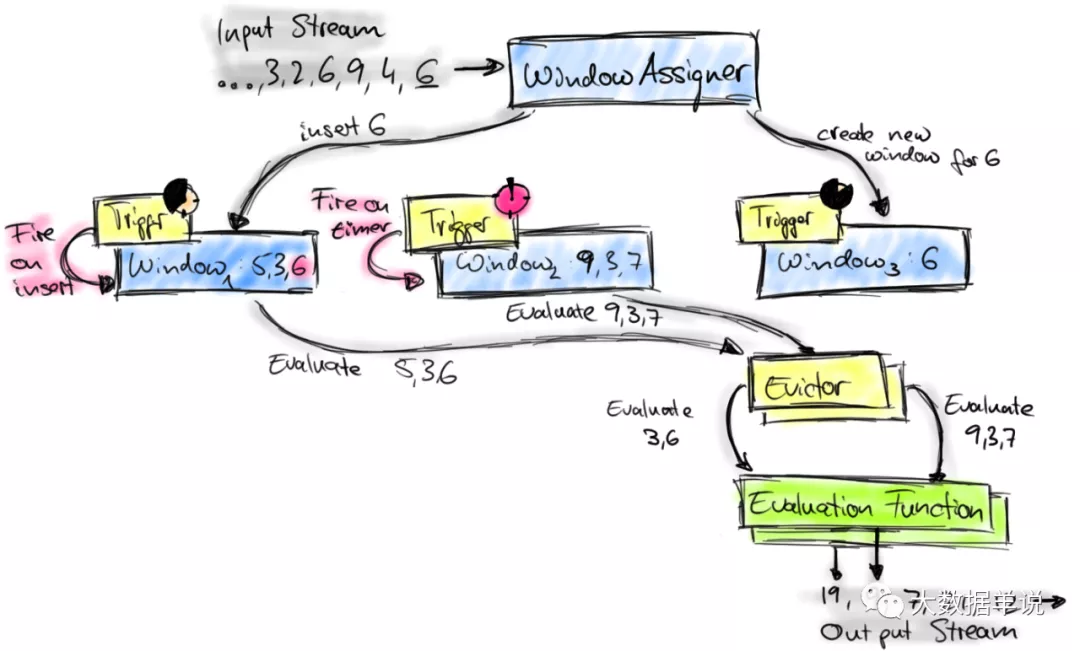
来看看 WindowOperator 的执行逻辑。窗口执行的整体详细流程可以参考:http://wuchong.me/blog/2016/05/25/flink-internals-window-mechanism/
4.2.flink sql tumble window 的语义
介绍到 tumble window 的语义,总要有对比的去介绍。这里的参照物就是 datastream api。
在 datastream api 中。tumble window 一般用作以下两种场景。
业务场景:使用 tumble window 很轻松的计算出窗口内的聚合数据。一般是多条输入数据,窗口结束时一条输出数据。
优化场景:窗口聚合一批数据然后批量访问外部存储扩充维度、或者有一些自定义的处理逻辑。一般是多条输入数据,窗口结束时多条输出数据。
但是在 sql api 中。tumble window 是聚合(group by)语义,聚合在 sql 标准中的数据处理逻辑是多条输入,在窗口触发时就输出一条数据的语义。而上面的常常用在 datastream 中的优化场景是多对多的场景。因此和 sql 语义不符合。所以 flink sql tumble window 一般都是用于计算聚合运算值来使用。
4.3.tumble window 实际案例
滚动窗口的特性就是会将无限流进行纵向划分成一个一个的窗口,每个窗口都是相同的大小,并且不重叠。
本文主要介绍 flink 1.12 及之前版本的实现。下一篇文章介绍 flink 1.13 的实现。
来,在介绍原理之前,总要先用起来,我们就以下面这个例子展开。
(flink 1.12.1)场景:简单且常见的分维度分钟级别同时在线用户数、总销售额
数据源表:
- CREATE TABLE source_table (
- -- 维度数据
- dim STRING,
- -- 用户 id
- user_id BIGINT,
- -- 用户
- price BIGINT,
- -- 事件时间戳
- row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),
- -- watermark 设置
- WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
- ) WITH (
- 'connector' = 'datagen',
- 'rows-per-second' = '10',
- 'fields.dim.length' = '1',
- 'fields.user_id.min' = '1',
- 'fields.user_id.max' = '100000',
- 'fields.price.min' = '1',
- 'fields.price.max' = '100000'
- )
- Notes - 关于 watermark 容易踩得坑:sql 的 watermark 类型必须要设置为 TIMESTAMP(3)。
数据汇表:
- CREATE TABLE sink_table (
- dim STRING,
- pv BIGINT,
- sum_price BIGINT,
- max_price BIGINT,
- min_price BIGINT,
- uv BIGINT,
- window_start bigint
- ) WITH (
- 'connector' = 'print'
- )
数据处理逻辑:
可以看下下面语法,窗口聚合的写法有专门的 tumble(row_time, interval '1' minute) 写法,这就是与平常我们写的 hive sql,mysql 等不一样的地方。
- insert into sink_table
- select dim,
- sum(bucket_pv) as pv,
- sum(bucket_sum_price) as sum_price,
- max(bucket_max_price) as max_price,
- min(bucket_min_price) as min_price,
- sum(bucket_uv) as uv,
- max(window_start) as window_start
- from (
- select dim,
- count(*) as bucket_pv,
- sum(price) as bucket_sum_price,
- max(price) as bucket_max_price,
- min(price) as bucket_min_price,
- -- 计算 uv 数
- count(distinct user_id) as bucket_uv,
- cast(tumble_start(row_time, interval '1' minute) as bigint) * 1000 as window_start
- from source_table
- group by
- -- 按照用户 id 进行分桶,防止数据倾斜
- mod(user_id, 1024),
- dim,
- tumble(row_time, interval '1' minute)
- )
- group by dim,
- window_start
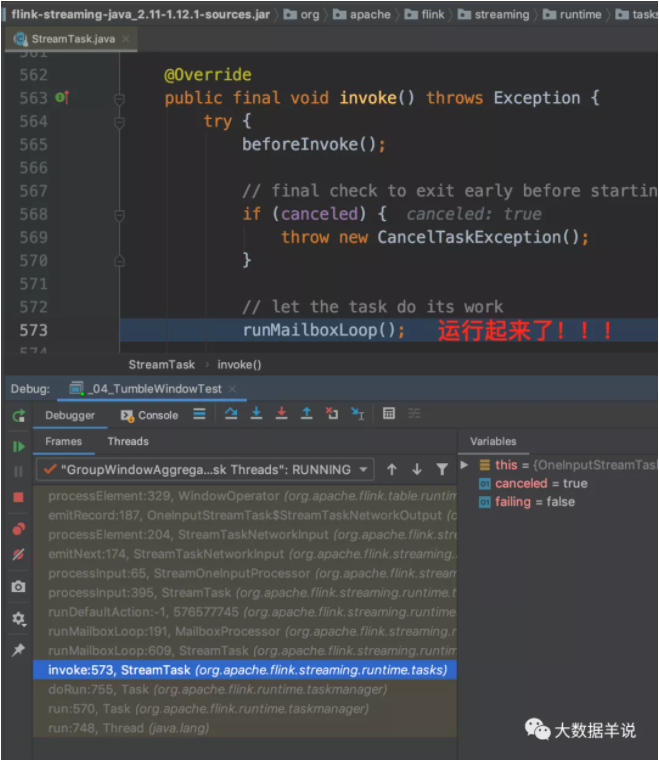
运行:可以看到,其实在 flink sql 任务中,其会把对应的处理逻辑给写到算子名称上面。
- Notes - 观察 flink sql 技巧 1:这个其实就是我们观察 flink sql 任务的第一个技巧。如果你想知道你的 flink 任务在干啥,第一反应是去 flink webui 看看这个任务目前在做什么。包括算子名称都会给直接展示给我们目前哪个算子在干啥事情,在处理啥逻辑
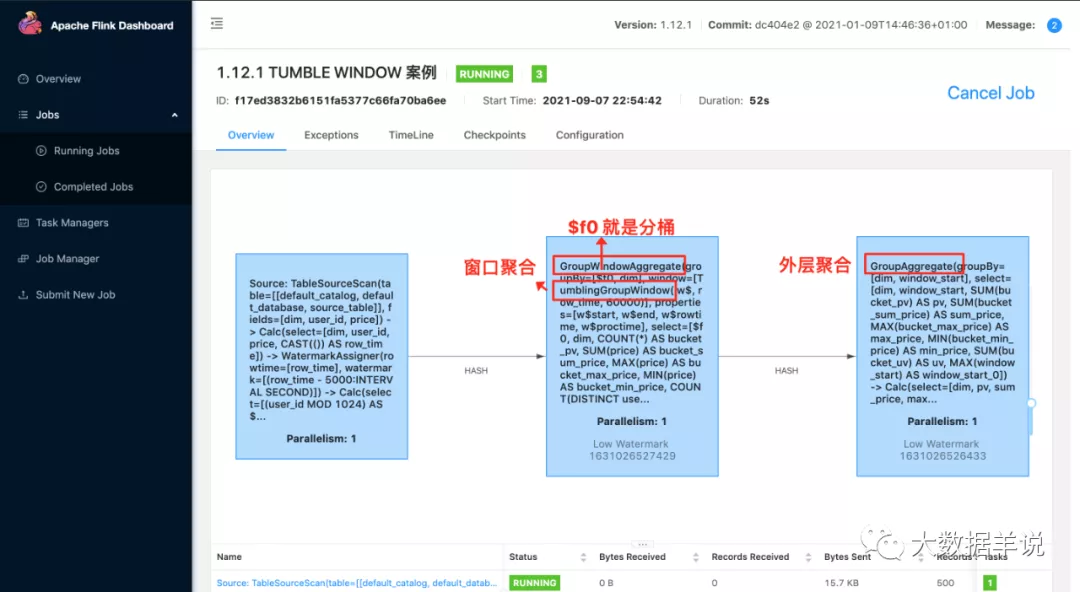
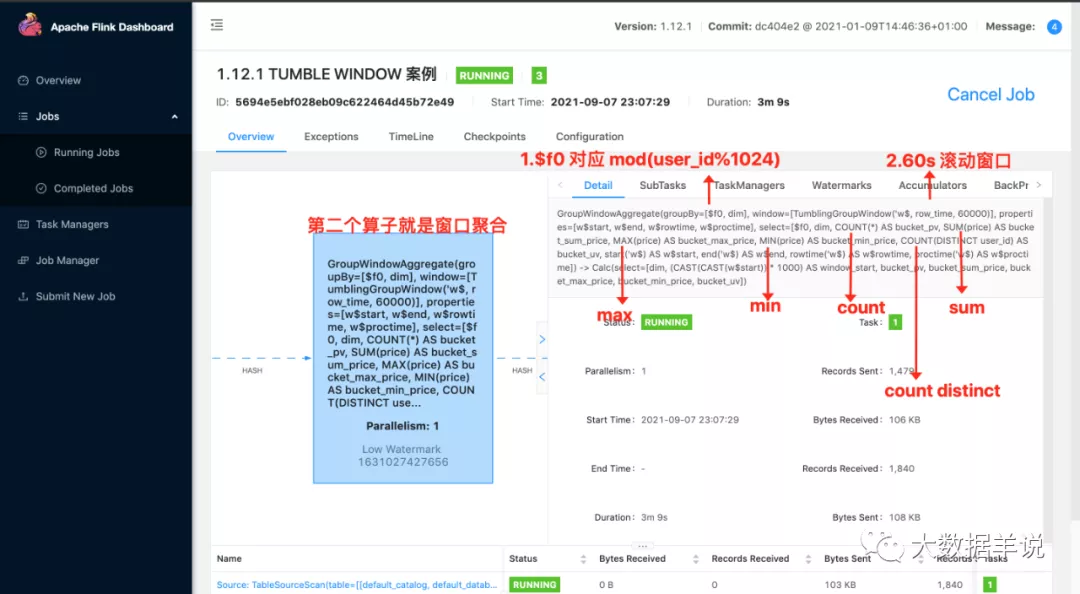
先看一下整个算子图,如下图。从左到右总共分为三个算子。
第一个算子就是数据源算子
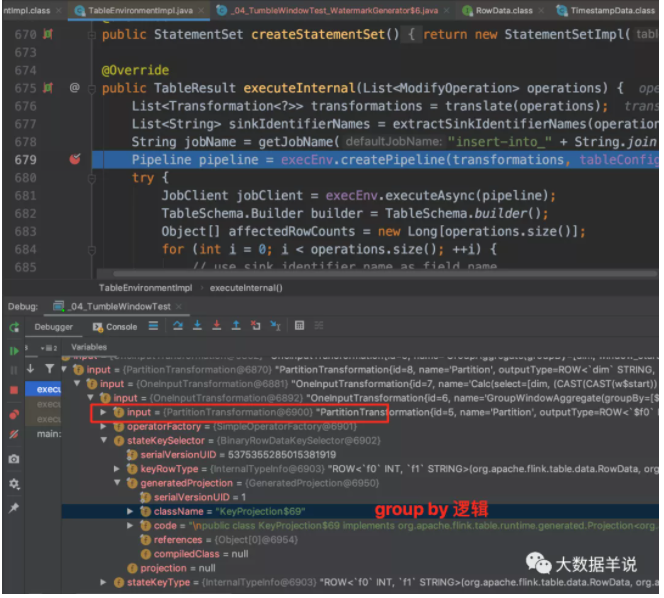
第二个算子就是分了桶的窗口聚合算子,第一个算子和第二个算子之间 hash 传输就是按照 group key 进行 hash 传输
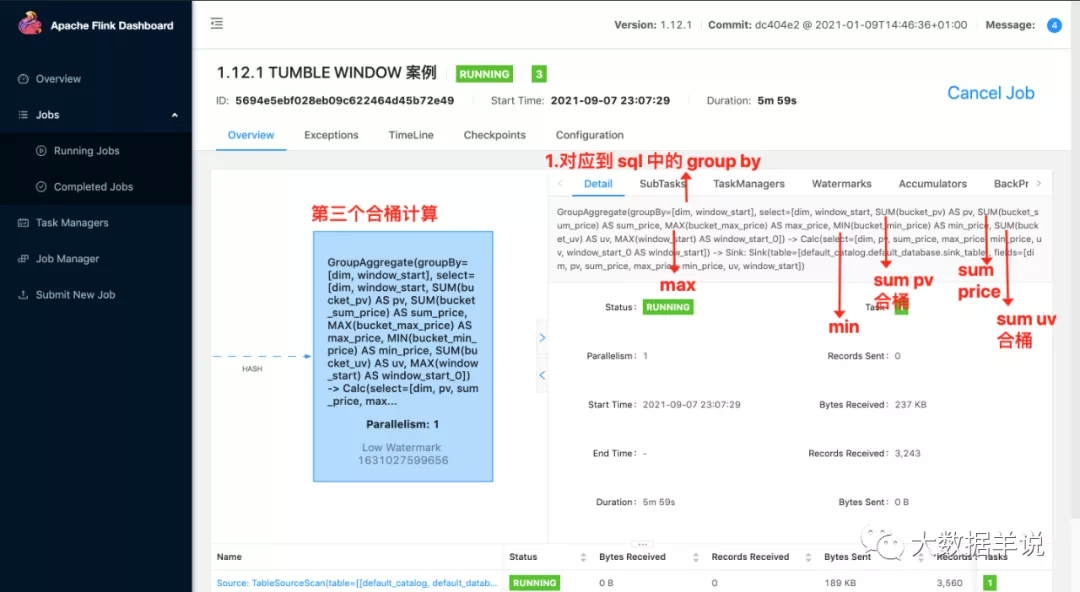
第三个算子就是外层进行合桶计算的算子,同样也是 hash 传输,将分桶的数据在一个算子中进行合并计算
来看看每一个算子具体做了什么事情。
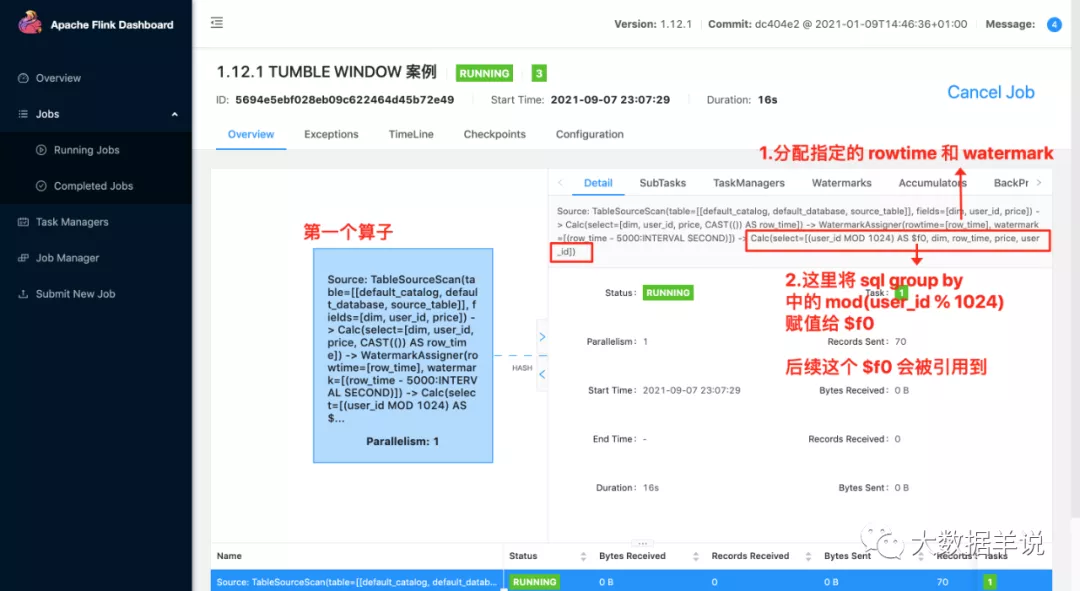
第一个算子:
table scan 读取数据源
从数据源中获取对应的字段(包括源表定义的 rowtime)
分配 watermark(按照源表定义的 watermark 分配对应的 watermark)
将一些必要的字段抽取。比如 group by 中的字段。在 hash 时需要使用。
第二个算子:
窗口聚合,计算窗口聚合数据
将数据按照第一层 select 中的数据进行计算以及格式化
第三个算子:
group 聚合合桶计算
将数据按照第二层 select 中的数据进行计算以及格式化
将数据 sink 写出
(flink 1.12.1)结果:
- +I(9,1,32682,32682,32682,1,1631026440000)
- -U(9,1,32682,32682,32682,1,1631026440000)
- +U(9,2,115351,82669,32682,2,1631026440000)
- +I(2,1,76148,76148,76148,1,1631026440000)
- +I(8,1,79321,79321,79321,1,1631026440000)
- +I(a,1,85792,85792,85792,1,1631026440000)
- +I(0,1,12858,12858,12858,1,1631026440000)
- +I(5,1,36753,36753,36753,1,1631026440000)
- +I(3,1,19218,19218,19218,1,1631026440000)
(flink 1.12.1)原理:
关于 sql 开始运行的机制见上一节详述。
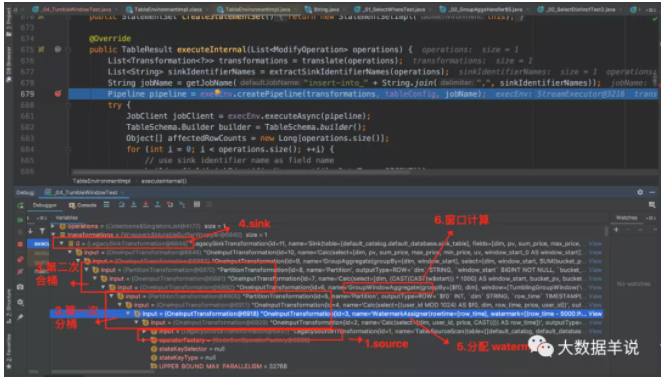
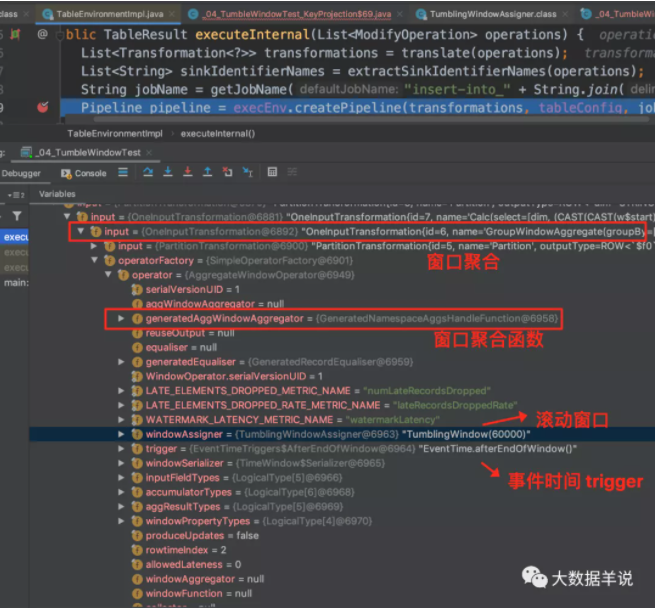
此处只介绍相比前一节新增内容。可以看到上述代码的具体 transformation 如下图。
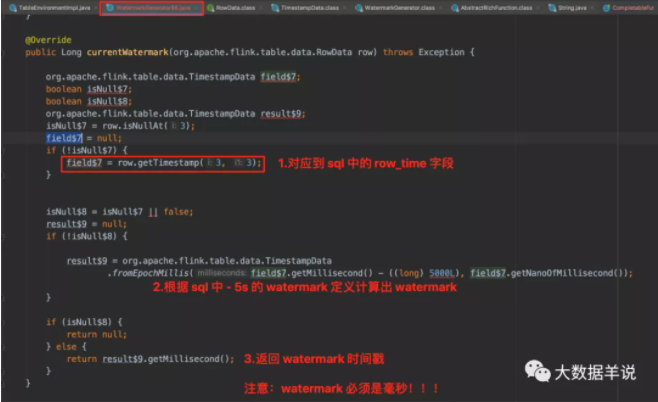
4.4.GeneratedWatermarkGenerator - flink 1.12.1
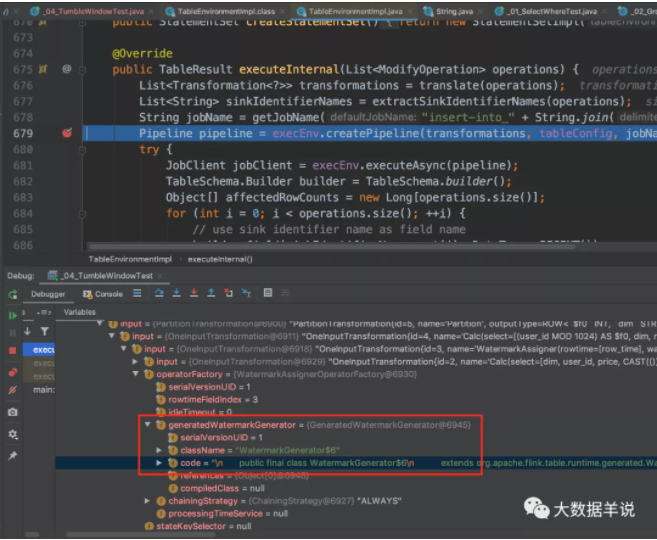
按照顺序,首先看看 watermark 算子。同 datastream 的自定义 watermark 分配策略。
watermark 生成的具体代码 WatermarkGenerator$6,主要获取 watermark 的逻辑在 currentWatermark 方法中。如下图。
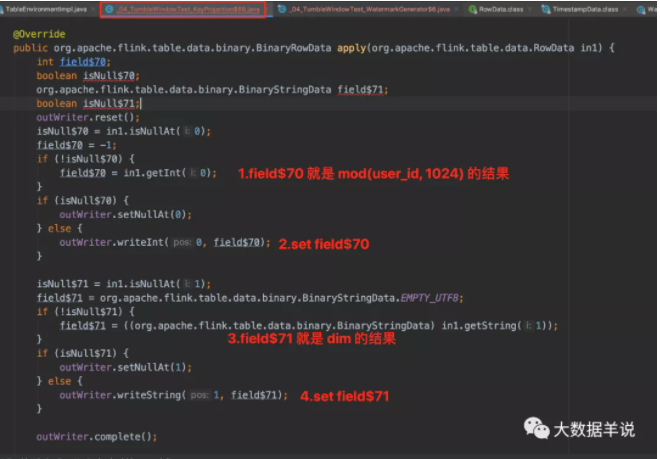
4.5.BinaryRowDataKeySelector - flink 1.12.1
接着就是 group by(同 datastream 中的 keyby)。
group by key 生成的具体代码 KeyProjection$19,主要逻辑在 apply 方法中。
下一个就是窗口聚合算子。
4.6.AggregateWindowOperator - flink 1.12.1
兄弟们!!!兄弟们!!!兄弟们!!!
本节的重头戏来了。sql 窗口聚合算子解析搞起来了。
关于 WatermarkGenerator 和 KeyProjection 没有什么可以详细介绍的,都是输入一条数据,输出一条数据,逻辑很简单。
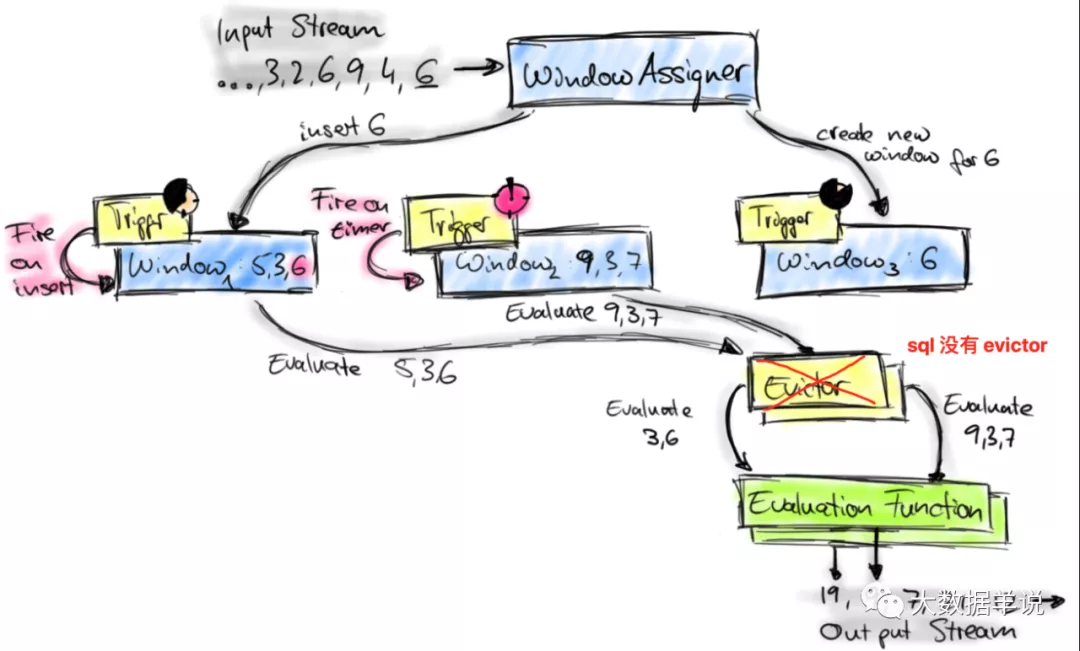
但是窗口聚合算子的计算逻辑相比上面两个算子复杂很多。窗口算子又承载了窗口聚合的主要逻辑,所以本文重点介绍窗口算子计算的逻辑。
先来看看 sql 窗口整体处理流程。其实与 datastream 处理流程基本一致,但只是少了 Evictor。如下图所示。
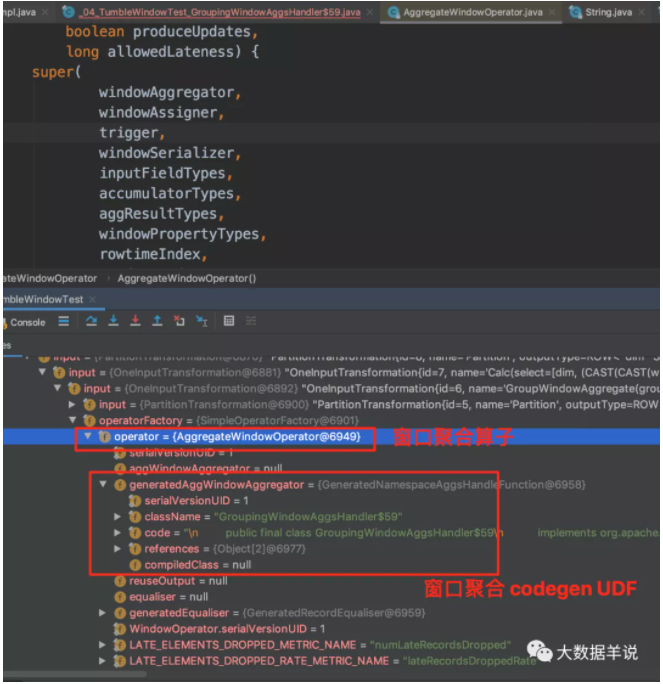
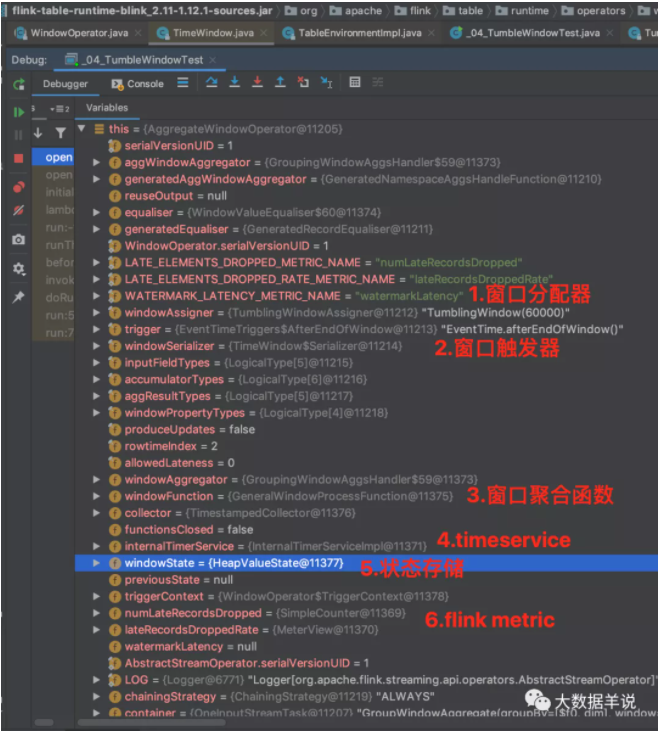
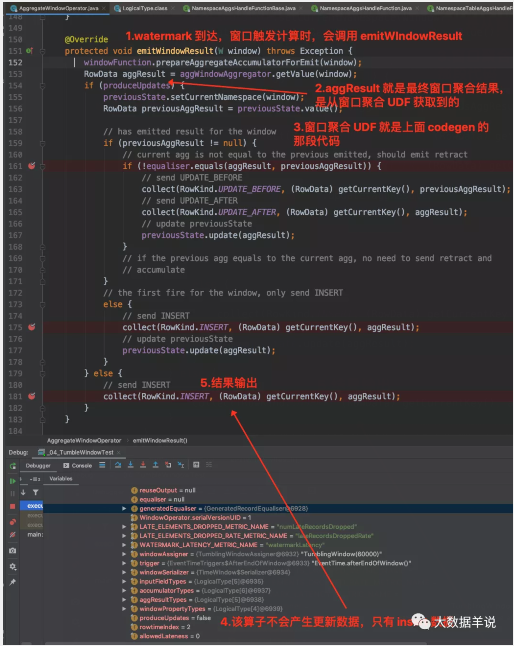
接着来看看上述 sql 生成的窗口聚合算子 AggregateWindowOperator,截图中属性也很清晰。
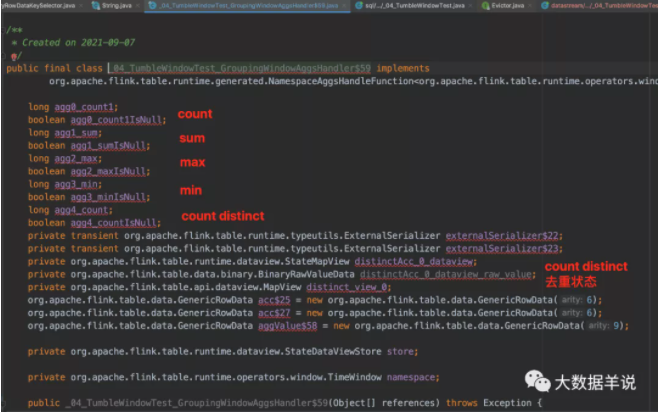
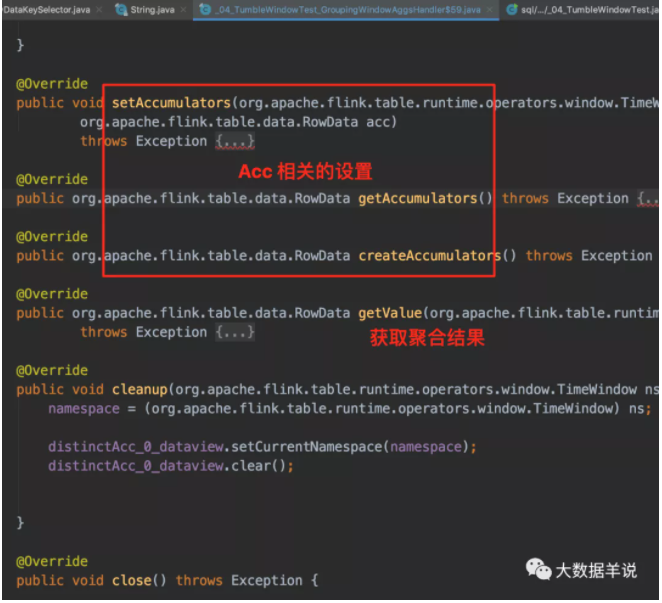
具体生成的窗口聚合代码 GroupingWindowAggsHandler$59。
计算逻辑 GroupingWindowAggsHandler$59#accumulate。
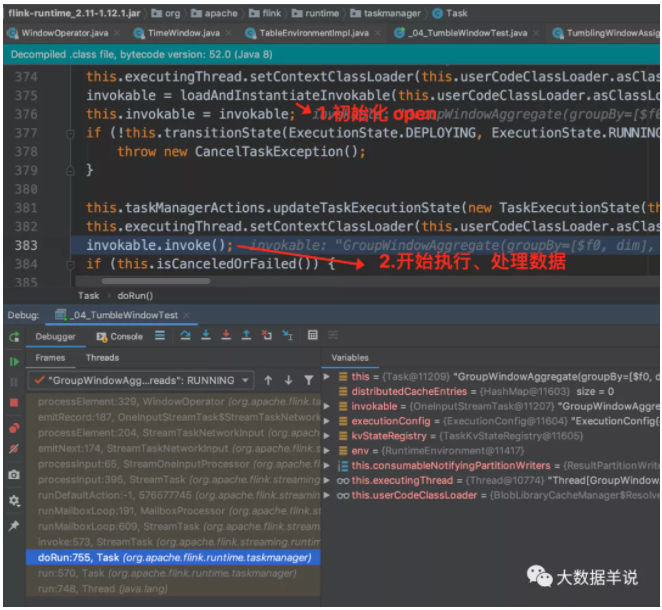
上面那段都是在 flink 客户端初始化处理的。包括窗口算子的初始化等。
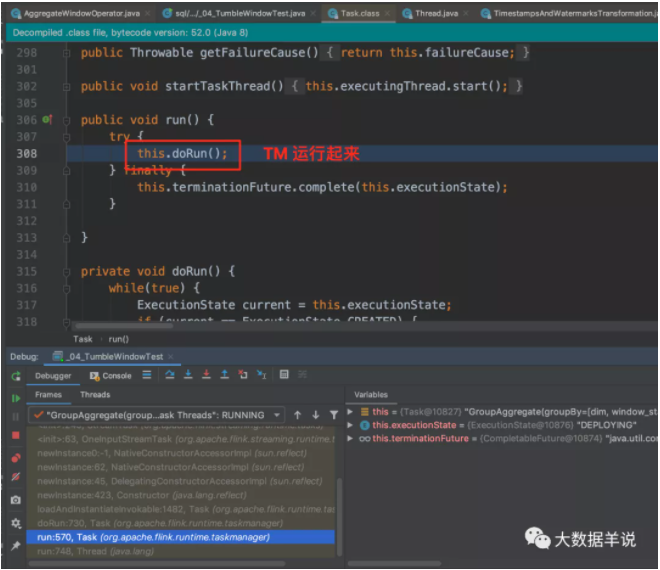
下面这段处理逻辑是在 flink TM 运行时开始执行的,包括窗口算子资源的初始化以及运行逻辑。就到了正式的数据处理环节了。
窗口算子 Task 运行。
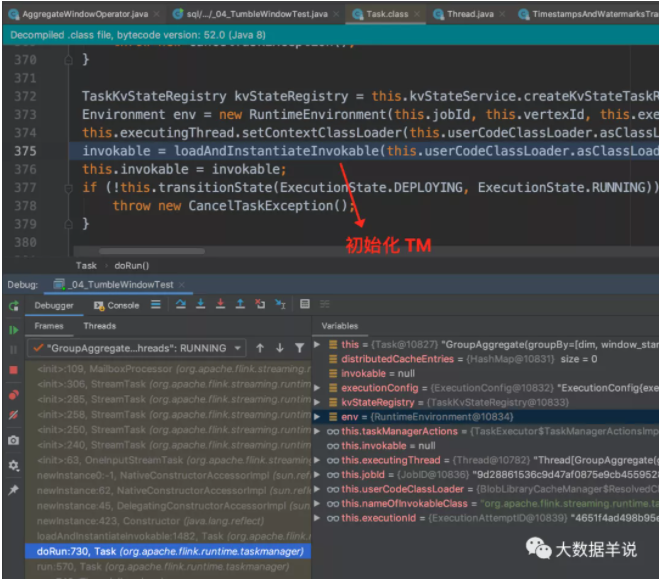
窗口算子 Task 初始化。
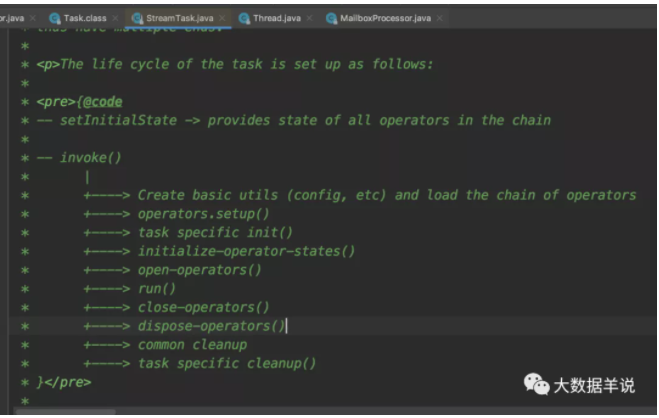
StreamTask 整体的处理流程。
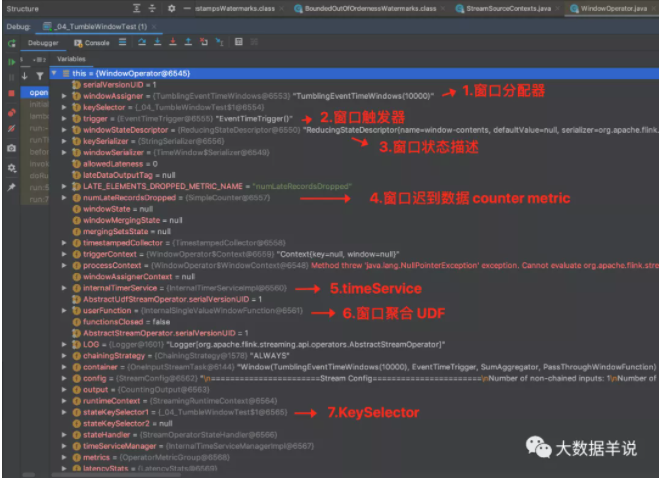
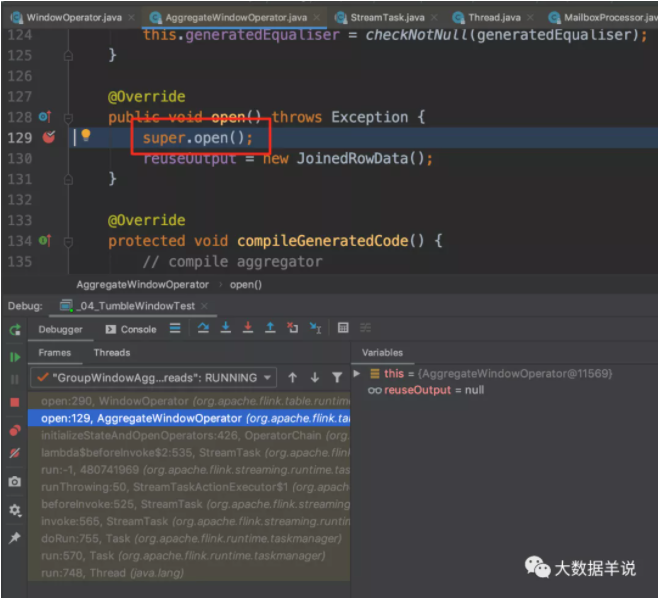
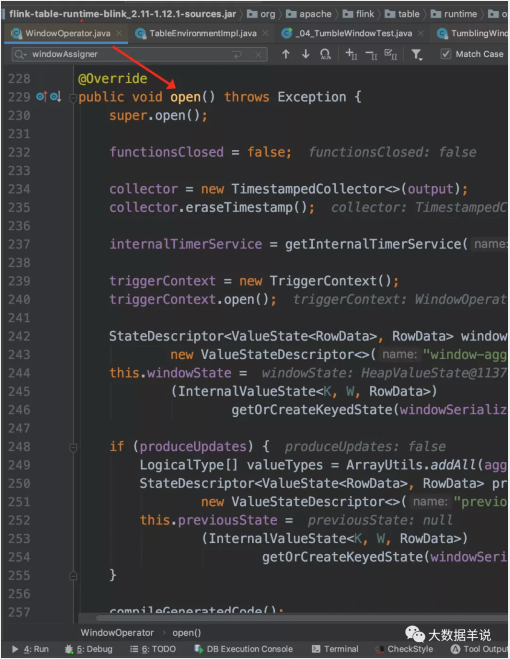
窗口算子 open 初始化。
窗口算子 open 初始化后的结果。如下图,对应的具体组件。
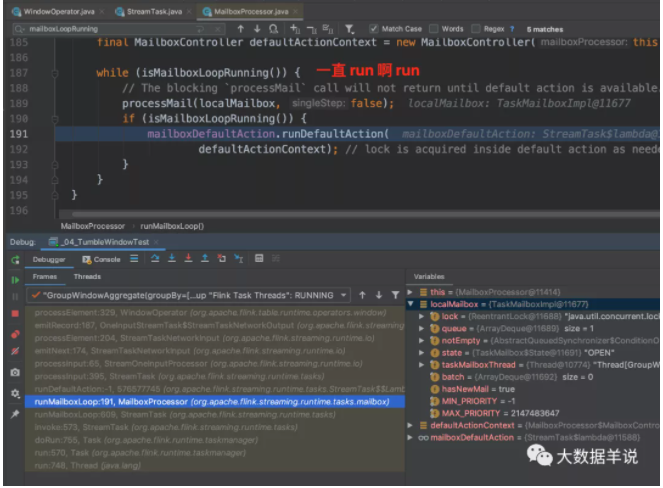
初始化完成之后,开始处理具体数据。
循环 loop,一直 run 啊 run。
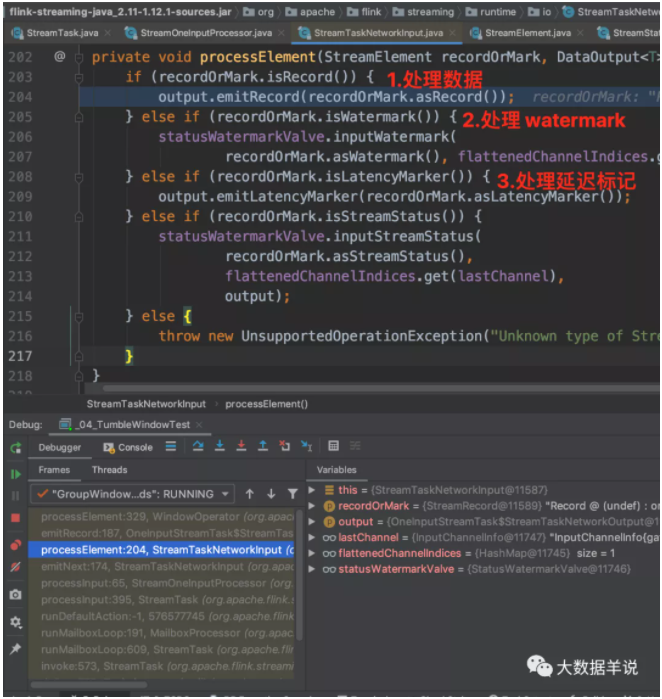
判断记录的具体类型,然后执行不同的逻辑。
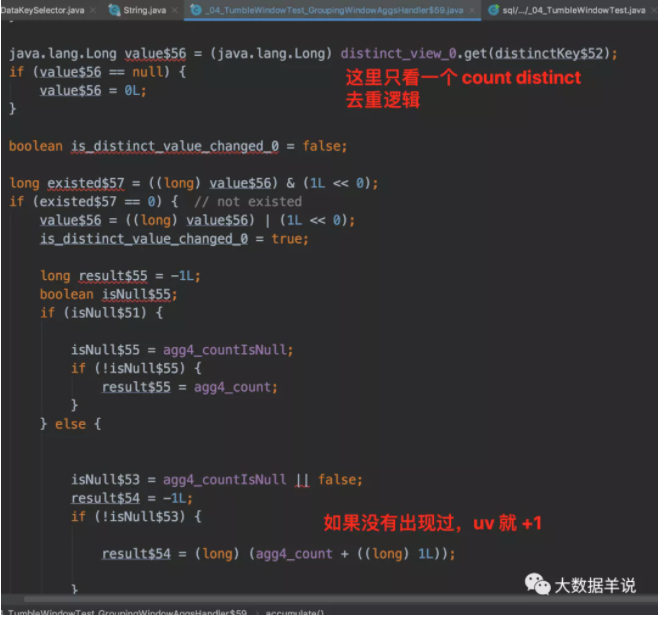
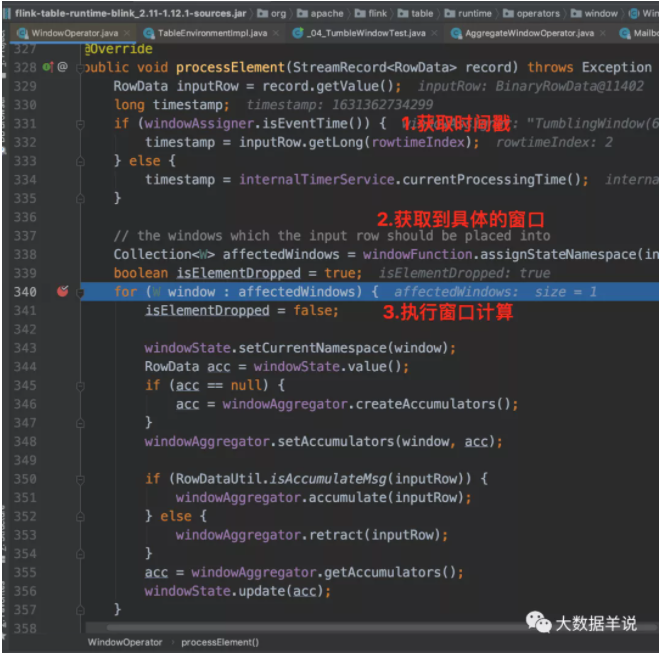
来看看处理一条数据的 processElement 方法逻辑,进行 acc 处理。代码中的的 windowAggregator 就是之前代码生成的 GroupingWindowAggsHandler$59。
- Notes:事件时间逻辑中,sql api 和 datastream api 对于数据记录时间戳存储逻辑是不一样的。datastream api:每条记录的 rowtime 是放在 StreamRecord 中的时间戳字段中的。sql api:时间戳是每次都从数据中进行获取的。算子中会维护一个下标。可以按照下标从数据中获取时间戳。
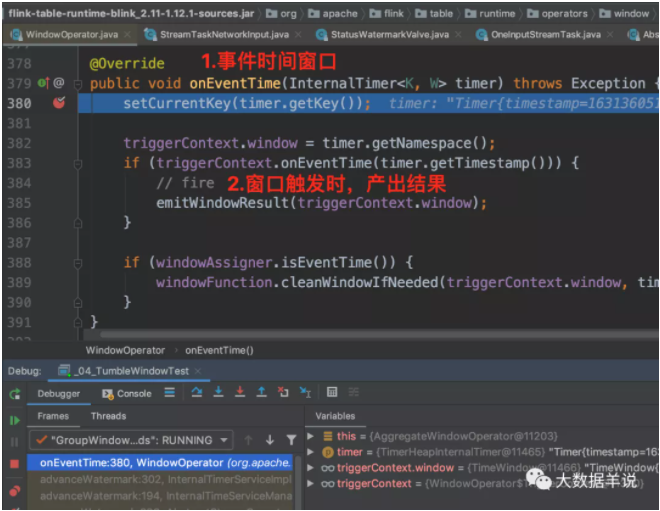
来看看 watermark 到达并且触发窗口计算时,执行 onEventTime 逻辑。
触发窗口计算时,onEventTime -> emitWindowResult,产出具体数据。
至此整个 sql tumble window 的处理逻辑也就很清楚了。和 datastream 基本上都是一致的。是不是整个逻辑就理清楚了。
5.总结与展望篇
本文主要介绍了 tumble window 聚合类指标的常见场景案例以及其底层运行原理。
而且也介绍了在查看 flink sql 任务时的一些技巧:
去 flink webui 就能看到这个任务目前在做什么。包括算子名称都会给直接展示给我们目前哪个算子在干啥事情,在处理啥逻辑。
sql 的 watermark 类型要设置为 TIMESTAMP(3)。
事件时间逻辑中,sql api 和 datastream api 对于数据记录时间戳存储逻辑是不一样的。datastream api:每条记录的 rowtime 是放在 StreamRecord 中的时间戳字段中的。sql api:时间戳是每次都从数据中进行获取的。算子中会维护一个下标。可以按照下标从数据中获取时间戳。
本文转载自微信公众号「大数据羊说」








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}