
本篇内容介绍了“python怎么利用多线程+队列技术爬取中介网互联网网站排行榜”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
目标站点分析
本次要抓取的目标站点为:中介网,这个网站提供了网站排行榜、互联网网站排行榜、中文网站排行榜等数据。
网站展示的样本数据量是 :58341。
采集页面地址为 https://www.zhongjie.com/top/rank_all_1.html,
UI如下所示:
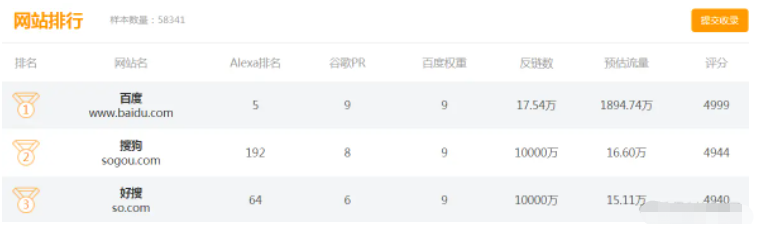
由于页面存在一个【尾页】超链接,所以直接通过该超链接获取累计页面即可。
其余页面遵循简单分页规则:
https://www.zhongjie.com/top/rank_all_1.htmlhttps://www.zhongjie.com/top/rank_all_2.html基于此,本次Python爬虫的解决方案如下,页面请求使用 requests 库,页面解析使用 lxml,多线程使用 threading 模块,队列依旧采用 queue 模块。
编码时间
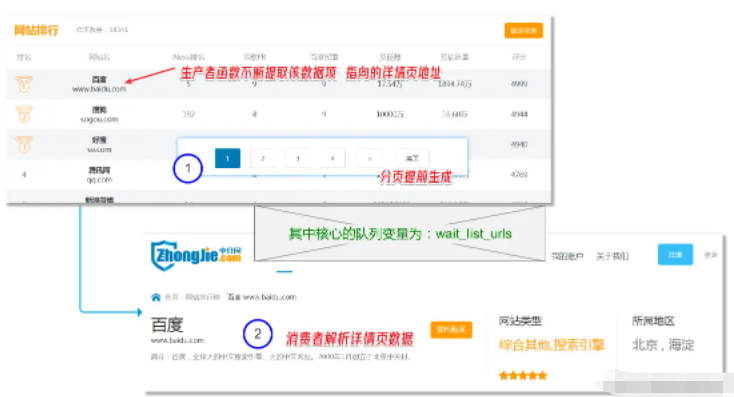
在正式编码前,先通过一张图将逻辑进行梳理。
本爬虫编写步骤文字描述如下:
预先请求第一页,解析出总页码;
通过生产者不断获取域名详情页地址,添加到队列中;
消费者函数从队列获取详情页地址,解析目标数据。
总页码的生成代码非常简单
def get_total_page():# get_headers() 函数,可参考开源代码分享数据 res = requests.get( 'https://www.zhongjie.com/top/rank_all_1.html', headers=get_headers(), timeout=5) element = etree.HTML(res.text) last_page = element.xpath("//a[@class='weiye']/@href")[0] pattern = re.compile('(\d+)') page = pattern.search(last_page) return int(page.group(1))总页码生成完毕,就可以进行多线程相关编码,本案例未编写存储部分代码,留给你自行完成啦,
完整代码如下所示:
from queue import Queueimport timeimport threadingimport requestsfrom lxml import etreeimport randomimport redef get_headers(): uas = [ "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)", "Mozilla/5.0 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)" ] ua = random.choice(uas) headers = { "user-agent": ua } return headersdef get_total_page(): res = requests.get( 'https://www.zhongjie.com/top/rank_all_1.html', headers=get_headers(), timeout=5) element = etree.HTML(res.text) last_page = element.xpath("//a[@class='weiye']/@href")[0] pattern = re.compile('(\d+)') page = pattern.search(last_page) return int(page.group(1))# 生产者def producer(): while True: # 取一个分类ID url = urls.get() urls.task_done() if url is None: break res = requests.get(url=url, headers=get_headers(), timeout=5) text = res.text element = etree.HTML(text) links = element.xpath('//a[@class="copyright_title"]/@href') for i in links: wait_list_urls.put("https://www.zhongjie.com" + i)# 消费者def consumer(): while True: url = wait_list_urls.get() wait_list_urls.task_done() if url is None: break res = requests.get(url=url, headers=get_headers(), timeout=5) text = res.text element = etree.HTML(text)# 数据提取,更多数据提取,可自行编写 xpath title = element.xpath('//div[@class="info-head-l"]/h2/text()') link = element.xpath('//div[@class="info-head-l"]/p[1]/a/text()') description = element.xpath('//div[@class="info-head-l"]/p[2]/text()') print(title, link, description)if __name__ == "__main__": # 初始化一个队列 urls = Queue(maxsize=0) last_page = get_total_page() for p in range(1, last_page + 1): urls.put(f"https://www.zhongjie.com/top/rank_all_{p}.html") wait_list_urls = Queue(maxsize=0) # 开启2个生产者线程 for p_in in range(1, 3): p = threading.Thread(target=producer) p.start() # 开启2个消费者线程 for p_in in range(1, 2): p = threading.Thread(target=consumer) p.start()“python怎么利用多线程+队列技术爬取中介网互联网网站排行榜”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!







