
图片来自 Pexels
我将围绕如下两个话题展开:
- 为什么要从 MongoDB 迁移到 Elasticsearch?
- 如何从 MongoDB 迁移到 Elasticsearch?
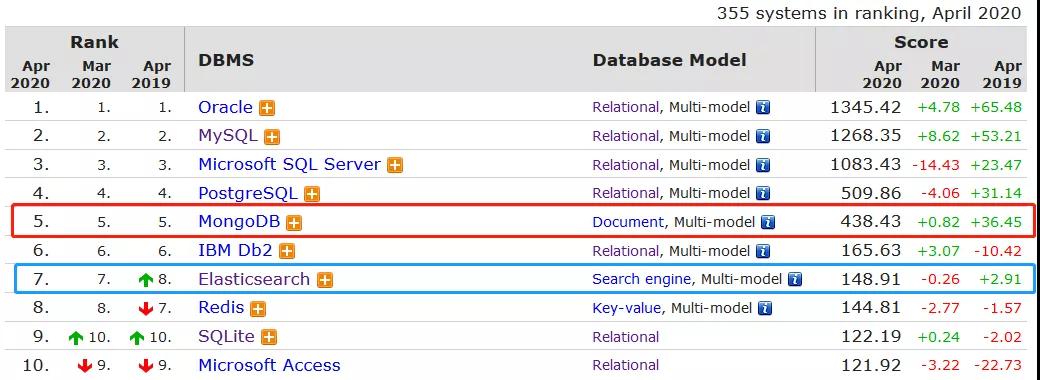
MongoDB 与 Elasticsearch 热度排名
现状背景
MongoDB 本身定位与关系型数据库竞争,但工作中几乎没有见到哪个项目会将核心业务系统的数据放在上面,依然选择传统的关系型数据库。
项目背景
公司所在物流速运行业,业务系统复杂且庞大,用户操作者很多,每日有大量业务数据产生,同时业务数据会有很多次流转状态变化。
为了便于记录追踪分析,系统操作日志记录项目应运而生,考虑到原有的日均数据量,操作日志数据基于 MongoDB 存储。
操作日志记录系统需要记录两种数据,如下说明:
①变更主数据,什么人在什么时间在系统哪个模块做了什么操作,数据编号是什么,操作跟踪编号是什么。
- {
- "dataId": 1,
- "traceId": "abc",
- "moduleCode": "crm_01",
- "operateTime": "2019-11-11 12:12:12",
- "operationId": 100,
- "operationName": "张三",
- "departmentId": 1000,
- "departmentName": "客户部",
- "operationContent": "拜访客户。。。"
- }
②变更从数据,实际变更数据的变化前后,此类数据条数很多,一行数据多个字段变更就记录多条。
- [
- {
- "dataId": 1,
- "traceId": "abc",
- "moduleCode": "crm_01",
- "operateTime": "2019-11-11 12:12:12",
- "operationId": 100,
- "operationName": "张三",
- "departmentId": 1000,
- "departmentName": "客户部",
- "operationContent": "拜访客户",
-
- "beforeValue": "20",
- "afterValue": "30",
- "columnName": "customerType"
- },
- {
- "dataId": 1,
- "traceId": "abc",
- "moduleCode": "crm_01",
- "operateTime": "2019-11-11 12:12:12",
- "operationId": 100,
- "operationName": "张三",
- "departmentId": 1000,
- "departmentName": "客户部",
- "operationContent": "拜访客户",
-
- "beforeValue": "2019-11-02",
- "afterValue": "2019-11-10",
- "columnName": "lastVisitDate"
- }
- ]
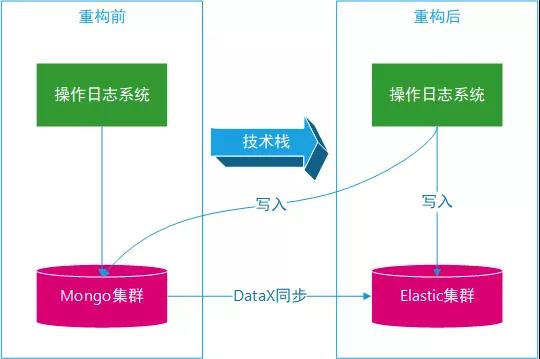
项目架构
项目架构描述如下:
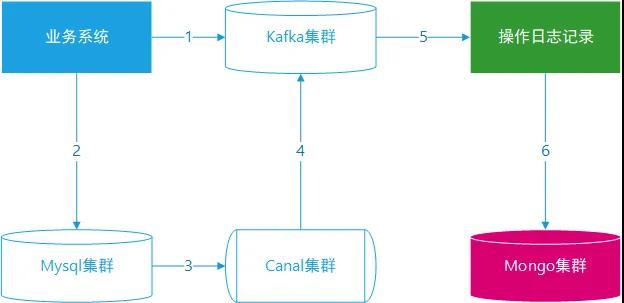
- 业务系统新增或者编辑数据,产生操作日志记录发送到 Kafka 集群,基于 dataid 字段作为 key。
- 新增或编辑数据实际存储到 MySQL 数据库。
- Canal 集群订阅 MySQL 集群,按照业务系统模块配置监控的数据库与表。
- Canal 将监控到的变更业务数据发送到 Kafka 集群,基于 dataid 字段作为 key。
- 操作日志系统从 Kafka 获取主记录数据与从记录数据。
- 操作日志系统写入数据到 MongoDB,同时需要反查询。
操作日志记录业务流程说明
MongoDB 架构
集群架构说明:
- 服务器配置 8c/32gb/500gb ssd。
- Router 路由服务器部署了 3 个节点。
- Config 配置服务器部署了 3 个节点。
- Shard 分片服务器部署了 9 个节点。
- 主操作记录设计 3 个分片。
- 从操作记录设计 3 个分片。
问题说明:MongoDB 的信徒们可能怀疑我们没有使用好,或者我们的运维能力欠缺,或者认为我们有 Elasticsearch 的高手在。
不是这样的,弃用 MongoDB 选择 Elasticsearch 其实并非技术偏见问题,而是我们的实际场景需求,原因如下:
①搜索查询
项目背景:
- MongoDB 内部采用 B-Tree 作为索引结构,此索引基于最左优先原则,且必须保证查询顺序与索引字段的顺序一致才有效,这个即是优点,但在现在复杂业务场景也是致命的。
- 业务系统查询操作日志记录会有很多过滤条件,且查询条件是任意组合的,现有 MongoDB 是不支持的,或者说所有关系型数据库都不支持,如果要支持,得创建好多组合的 B+ 数索引,想法很不理智。
- 同时主记录与从记录中有很多字符类的数据,这些数据查询即要支持精确查询,也要支持全文检索,这几个方面 MongoDB 功能很单一,性能也很糟糕,业务系统查询时经常超时,反倒是 Elasticsearch 非常合适。
②技术栈成熟度
项目背景:
- 分片与副本实现问题,MongoDB 集合数据在设计时是需要绑定到具体的机器实例的,哪些分片分布在哪些节点上,哪些副本分布在哪些节点上。
这些都需要在配置集群时就要绑定死,跟传统的关系型数据库做分库分表本质上没有什么两样,其实现在很多数据产品的集群还是这种模式偏多,比如 Redis-cluster,ClickHouse 等。
而 Elasticsearch 的集群与分片和副本没有直接的绑定关系,可以任意的平衡调整,且节点的性能配置也可以很容易差异化。
- 操作日志数据量增加很快,单日写入超过千万条,不用多久,运维人员就需要对服务器进行扩容,且相对 Elasticsearch 复杂很多。
- MongoDB 单集合数据量超过 10 亿条,此情况下即使简单条件查询性能也不理想,不如 Elasticsearch 倒排索引快。
- 公司对于 ES 与 MongoDB 技术栈的经验积累不同,Elasticsearch 在很多项目中运用,非常核心的项目也是大量运用。
对于其技术与运维经验更丰富,而 MongoDB 如果除去核心业务场景,几乎找不到合适的切入口,实际没有人敢在核心项目中使用 MongoDB,这就很尴尬。
③文档格式相同
MongoDB 与 Elasticsearch 都属于文档型数据库,Bson 类同与 Json,_objectid与_id 原理一样,所以主数据与从数据迁移到 Elasticsearch 平台,数据模型几乎无需变化。
迁移方案
异构数据系统迁移,主要围绕这两大块内容展开:
- 上层应用系统迁移,原来是针对 MongoDB 的语法规则,现在要修改为面向 Elasticsearch 语法规则。
- 下层 MongoDB 数据迁移到 Elasticsearch。
①Elastic 容量评估
原有 MongoDB 集群采用了 15 台服务器,其中 9 台是数据服务器,迁移到 Elastic 集群需要多少台服务器?
我们采取简单推算办法,如假设生产环境上某个 MongoDB 集合的数据有 10 亿条数据,我们先在测试环境上从 MongoDB 到 ES 上同步 100 万条数据。
假设这 100 万条数据占用磁盘 10G,那生产上环境上需要 1 个 T 磁盘空间,然后根据业务预期增加量扩展一定冗余。
根据初步评估,Elastic 集群设置 3 台服务器, 配置 8c/16g 内存/2T 机械磁盘。服务器数量一下从 15 台缩减到 3 台,且配置也降低不少。
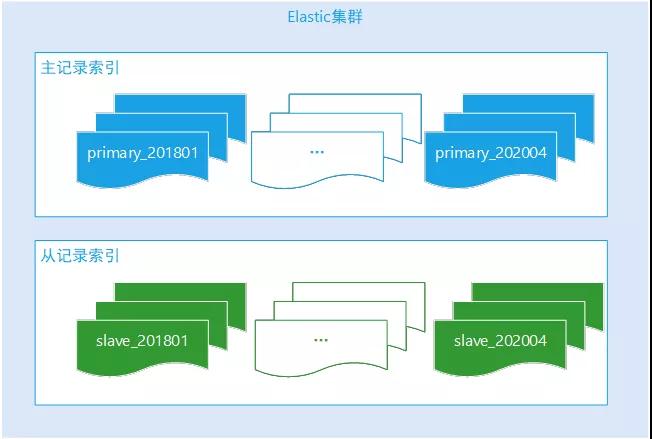
②Elastic 索引规则
系统操作日志是时序性数据,写完整后基本上无需再次修改。
操作日志记录查询主要是当月的居多,后续的历史性数据查询频率很低,根据评估,核心数据索引按月创建生成,业务查询时候必须带上操作时间范围,后端根据时间反推需要查询哪些索引。
Elastic-Api 支持多索引匹配查询,完美利用 Elastic 的特性解决跨多个月份的查询合并。对于非核心数据索引,按年创建索引生成足以。
Elastic 操作日志索引创建规则
③核心实现逻辑设计
Elasticsearch 不是关系型数据库,不具备事务的机制。
操作日志系统的数据来源都是 Kafka,消费数据是有顺序机制的,有 2 种场景特别注意,如下:
- 主数据先到操作日志系统,从数据后到,从数据写的时候先拼凑主数据记录和 Binlog 字段数据。
- 从数据先到操作日志系统,主数据后到,主数据更新从索引的相关的索引字段。
Elasticsearch 索引数据更新是近实时的刷新机制,数据提交后不能马上通过 Search-Api 查询到,主记录的数据如何更新到从记录呢?而且业务部门不规范的使用,多条主记录的 dataId 和 tracId 可能一样。
由于主数据与从数据关联字段是 dataId 和 traceId。如果主数据与从数据在同时达到操作日志系统,基于 update_by_query 命令肯定失效不 准确,主从数据也可能是多对多的关联关系,dataId 和 traceId 不能唯一决定一条记录。
Elasticsearch 其实也是一个 NoSQL 数据库,可以做 key-value 缓存。
这时新建一个 Elastic 索引作为中间缓存, 原则是主数据与从数据谁先到缓存谁,索引的 _id=(dataId+traceId)。
通过这个中间索引可以找到主数据记录的 Id 或者从记录 Id, 索引数据模型多如下,detailId 为从索引的 _id 的数组记录。
- {
- "dataId": 1,
- "traceId": "abc",
- "moduleCode": "crm_01",
- "operationId": 100,
- "operationName": "张三",
- "departmentId": 1000,
- "departmentName": "客户部",
- "operationContent": "拜访客户",
- "detailId": [
- 1,
- 2,
- 3,
- 4,
- 5,
- 6
- ]
- }
前面我们讲过主记录和从记录都是一个 Kafka 的分区上,我们拉一批数据的时候,操作 ES 用的用到的核心 API:
- #批量获取从索引的记录
- _mget
- #批量插入
- bulk
- #批量删除中间临时索引
- _delete_by_query
迁移过程
①数据迁移
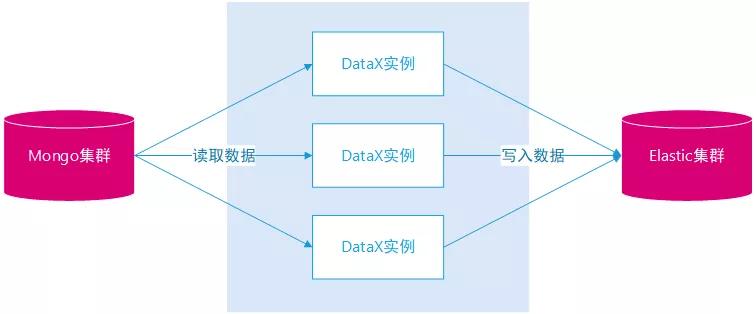
选择 DataX 作为数据同步工具由以下几个因素:
- 历史型数据。操作日志记录数据属于历史性的数据,记录产生之后几乎无需二次修改,等同于离线数据。
- 非持续性迁移。项目全部完工之后,原有的 MongoDB 集群会全部销毁,不会有二次迁移需求。
- 数据量问题。原有 MongoDB 操作日志数据量有几十亿条,迁移过程不能太快也不能太慢,速度太快,MongoDB 集群会出现性能问题,速度太慢,项目周期太长,增加运维的成本与复杂度。否则可以选择 Hadoop 作为中转平台的迁移。
- DataX 源码特定场景改造。如日期类型的转换、索引主键 _id 的生成、索引主键 _id 映射,支持重复同步。
- 多实例多线程并行。主数据同步部署多个实例,从数据同步也部署多个实例,单实例中配置多个 Channel。
DataX 同步数据示意图
②迁移索引设置
临时修改索引的一些设置,当数据同步完之后再修改回来,如下:
- "index.number_of_replicas": 0,
- "index.refresh_interval": "30s",
- "index.translog.flush_threshold_size": "1024M"
- "index.translog.durability": "async",
- "index.translog.sync_interval": "5s"
③应用迁移
操作日志项目采用 Spring Boot 构建,增加了自定义配置项,如下:
- #应用写入mongodb标识
- writeflag.mongodb: true
- #应用写入elasticsearch标识
- writeflag.elasticsearch: true
项目改造说明:
- 第一次上线的时候,先将 2 个写入标识设置为 true,双写 MongoDB 和 ES。
- 对于读,提供 2 个不同接口,前端自由的切换。
- 等数据迁移完,没有差异的时候,重新更改 flag 的值。
应用平衡迁移
结语
①迁移效果
弃用 MongoDB 使用 ElasticSearch 作为存储数据库,服务器从原来的 15 台 MongoDB,变成了 3 台 ElasticSearch,每月为公司节约了一大笔费用。
同时查询性能提高了 10 倍以上,而且更好的支持了各种查询,得到了业务部门的使用者,运维团队和领导的一致赞赏。
②经验总结
整个项目前后历经几个月,多位同事参与,设计、研发,数据迁移、测试、数据验证、压测等各个环节。
技术方案不是一步到位,中间也踩了很多坑,最终上线了。ES 的技术优秀特点很多,灵活的使用,才能发挥最大的威力。
作者:李猛
简介:Elastic-stack 产品深度用户,ES 认证工程师,2012 年接触 Elasticsearch,对 Elastic-Stack 开发、架构、运维等方面有深入体验,实践过多种 Elasticsearch 项目,最暴力的大数据分析应用,最复杂的业务系统应用;业余为企业提供 Elastic-stack 咨询培训以及调优实施。
编辑:陶家龙
出处:转载自微信公众号 DBAplus 社群(ID:dbaplus)









![[[322705]]](https://s5.51cto.com/oss/202004/19/ee2b8ab72fb90719b9dee7045e569ba0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}