
欢迎各位阅读本篇,深度学习的概念源于 人工神经网络的研究。含多隐层的 多层感知器就是一种深度学习结构。本篇文章讲述了将深度学习融入机器人领域,编程学习网教育平台提醒各位:本篇文章纯干货~因此大家一定要认真阅读本篇文章哦!
现在深度学习这么火,大家都会想着看看能不能用到自己的研究领域里。所以,将深度学习融入到机器人领域的尝试也是有的。我就自己了解的两个方面(视觉与规划)来简单介绍一下吧。
物体识别
这个其实是最容易想到的方向了,比较DL就是因为图像识别上的成果而开始火起来的。
这里可以直接把原来CNN的那几套网络搬过来用,具体工作就不说了,我之前在另一个回答amazon picking challenge(APC)2016中识别和运动规划的主流算法是什么?下有提到,2016年的『亚马逊抓取大赛』中,很多队伍都采用了DL作为物体识别算法。
物体定位
当然,机器视觉跟计算机视觉有点区别。机器人领域的视觉除了物体识别还包括物体定位(为了要操作物体,需要知道物体的位姿)。
2016年APC中,虽然很多人采用DL进行物体识别,但在物体定位方面都还是使用比较简单、或者传统的算法。似乎并未广泛采用DL。
当然,这一块也不是没人在做。我们实验室的张博士也是在做这方面尝试。我这里简单介绍一下张博士之前调研的一偏论文的工作。
Doumanoglou, Andreas, et al. "Recovering 6d object pose and predicting next-best-view in the crowd."Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.

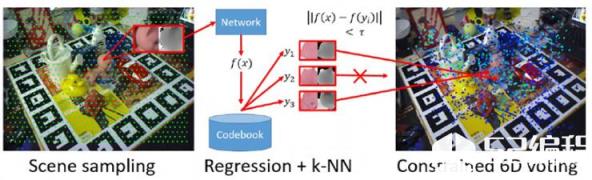
这个工作大概是这样的:对于一个物体,取很多小块RGB-D数据;每小块有一个坐标(相对于物体坐标系);然后,首先用一个自编码器对数据进行降维;之后,用将降维后的特征用于训练Hough Forest。
这样,在实际物体检测的时候,我就可以通过在物体表面采样RGB-D数据,之后,估计出一个位姿。
抓取姿态生成
这个之前在另一个问题(传统的RCNN可以大致框出定位物体在图片中的位置,但是如何将这个图片中的位置转化为物理世界的位置?)下有介绍过,放两个图

↑ Using Geometry to Detect Grasp Poses in 3DPoint Clouds
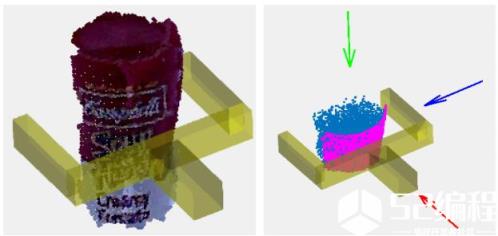
↑ High precision grasp pose detection in dense clutter
控制/规划
这一块是我现在感兴趣的地方。
简单地说,我们知道强化学习可以用来做移动机器人的路径规划。所以,理论上将,结合DL的Function Approximation 与 Policy Gradient,是有可能用来做控制或规划的。当然,现在的几个工作离取代原来的传统方法还有很长的距离要走,但是也是很有趣的尝试。
放几个工作,具体可以看他们的paper。
1.Learning monocular reactive uav control in cluttered natural environments

↑ CMU 无人机穿越森林
2. From Perception to Decision: A Data-driven Approach to End-to-end Motion Planning for Autonomous Ground Robots
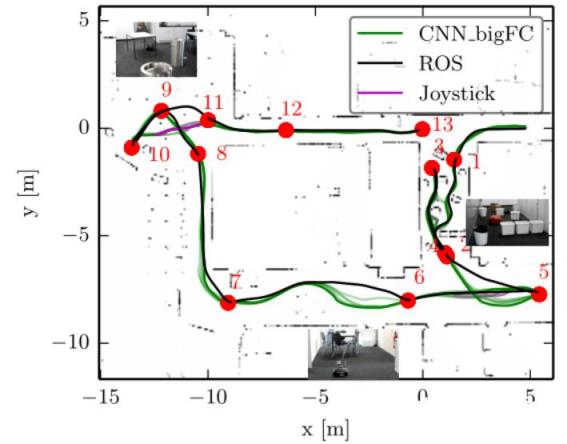
↑ ETH 室内导航
3.Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection

↑ DeepMind 物体抓取
4. End-to-end training of deep visuomotor policies
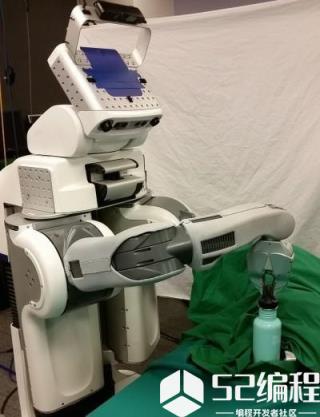
↑ Berkeley 拧瓶盖等任务
有哪些难点
1、在视觉领域,除了物体识别、还需要进行物体定位。这是一个 regression 问题,但是目前来看, regression 的精度还没办法直接用于物体操作,(可能是数据量还不够,或者说现在还没找到合适的网络结构),所以一般还需要采用ICP等算法进行最后一步匹配迭代。
2、机器人规划/控制等方面,可能存在的问题就比较多了。我之前在雷锋网『硬创公开课』直播(运动规划 | 视频篇)的时候有提到我碰到的一些问题,这里简单列在下面:
可观性问题
简单地说,我们这些不做DL理论的人,都是先默认DL的收敛、泛化能力是足够的。我们应该关心的是,要给DL喂什么数据。也就是说,在DL能力足够强的前提下,哪些数据才能让我需要解决的问题变得可观。
当然,目前的几个工作都没有提到这点,Berkeley的那个论文里是直接做了一个强假设:在给定数据(当前图像、机器人关节状态)下,状态是可观的。
实际机器人操作中,系统状态可能跟环境有关(例如物体性质),所以这一个问题应该是未来DL用在机器人上所不能绕过的一个问题。
数据量

一方面,我们不了解需要多少数据才能让问题收敛。另一方面,实际机器人进行一次操作需要耗费时间、可能会造成损害、会破坏实验条件(需要人工恢复)等,采集数据会比图像识别、语音识别难度大很多。
是否可解决
直播的时候我举了个例子,黑色障碍物位置从左到右连续变化的时候,规划算法输出的最短路径会发生突变。(具体看视频可能会比较清楚)
这对应于DL中,就是网络输入连续变化、但输出则会在某一瞬间突变。而且,最短路径可能存在多解等问题。
DL的 Function Approximattion 是否能很好地处理这一状况?
是吧,这几件事想想都很有趣,大家跟我一起入坑吧~
深度不足会出现问题
在许多情形中深度2就足够表示任何一个带有给定目标精度的函数。但是其代价是:图中所需要的节点数(比如计算和参数数量)可能变的非常大。理论结果证实那些事实上所需要的节点数随着输入的大小指数增长的函数族是存在的。
我们可以将深度架构看做一种因子分解。大部分随机选择的函数不能被有效地表示,无论是用深的或者浅的架构。但是许多能够有效地被深度架构表示的却不能被用浅的架构高效表示。一个紧的和深度的表示的存在意味着在潜在的可被表示的函数中存在某种结构。如果不存在任何结构,那将不可能很好地泛化。
大脑有一个深度架构
例如,视觉皮质得到了很好的研究,并显示出一系列的区域,在每一个这种区域中包含一个输入的表示和从一个到另一个的信号流(这里忽略了在一些层次并行路径上的关联,因此更复杂)。这个特征层次的每一层表示在一个不同的抽象层上的输入,并在层次的更上层有着更多的抽象特征,他们根据低层特征定义。
需要注意的是大脑中的表示是在中间紧密分布并且纯局部:他们是稀疏的:1%的 神经元是同时活动的。给定大量的神经元,仍然有一个非常高效地(指数级高效)表示。
认知过程逐层进行,逐步抽象
人类层次化地组织思想和概念;
人类首先学习简单的概念,然后用他们去表示更抽象的;
工程师将任务分解成多个抽象层次去处理;
学习/发现这些概念(知识工程由于没有反省而失败?)是很美好的。对语言可表达的概念的反省也建议我们一个稀疏的表示:仅所有可能单词/概念中的一个小的部分是可被应用到一个特别的输入(一个视觉场景)。
小结:深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。当然如果大家还想了解更多方面的详细内容的话呢,不妨关注编程学习网教育平台,在这个学习知识的天堂中,您肯定会有意想不到的收获的!











