
Linux grep命令具体使用方法是什么,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
Linux grep 命令用于查找文件里符合条件的字符串,grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。
grep [-abcEFGhHilLnqrsvVwxy][-A][-B][-C][-d][-e][-f][--help][范本样式][文件或目录...]参数:
-a 或 –text : 不要忽略二进制的数据。
-A 或 –after-context= : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b 或 –byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B 或 –before-context= : 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c 或 –count : 计算符合样式的列数。
-C 或 –context=或- : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d 或 –directories= : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e 或 –regexp= : 指定字符串做为查找文件内容的样式。
-E 或 –extended-regexp : 将样式为延伸的正则表达式来使用。
-f 或 –file= : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F 或 –fixed-regexp : 将样式视为固定字符串的列表。
-G 或 –basic-regexp : 将样式视为普通的表示法来使用。
-h 或 –no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H 或 –with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
-i 或 –ignore-case : 忽略字符大小写的差别。
-l 或 –file-with-matches : 列出文件内容符合指定的样式的文件名称。
-L 或 –files-without-match : 列出文件内容不符合指定的样式的文件名称。
-n 或 –line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
-o 或 –only-matching : 只显示匹配PATTERN 部分。
-q 或 –quiet或–silent : 不显示任何信息。
-r 或 –recursive : 此参数的效果和指定”-d recurse”参数相同。
-s 或 –no-messages : 不显示错误信息。
-v 或 –invert-match : 显示不包含匹配文本的所有行。
-V 或 –version : 显示版本信息。
-w 或 –word-regexp : 只显示全字符合的列。
-x –line-regexp : 只显示全列符合的列。
-y : 此参数的效果和指定”-i”参数相同。

grep支持基本正则表达式: 基本正则表达式
grep -E 也支持扩展正则表达式:扩展正则表达式
grep 支持的字符
[:digit:] : 所有数字,相当于 0-9 或者 \d
[:lower:] :所有的小写字母
[:upper:]:所有的大写字母
[:alpha:] :所有的字母
[:alnum:] :相当于[0-9a-zA-Z]
[:space:] :空白字符,相当于 \s
[:punct:] :所有标点符号
grep -E 或 egrep 支持的字符
\s:匹配任何空白字符,包括空格、制表符、换页符等,与[ \f\n\r\t\v ] 等效
\S:匹配任何非空白字符,与 [ ^\f\n\r\t\v ] 等效
\w:匹配任何字类字符,包括下划线,与 [A-Za-z0-9_] 等效
\W:匹配任何非单词字符,与[ ^A-Za-z0-9_] 等效
grep -P 支持的字符
\d :数字字符匹配,等效于 [0-9]
举例
1、匹配 eg.text 中以 # 开头,且后面跟了至少一个空白字符,而后又跟了任意非空白字符的行 grep "^#[[:space:]]\{1,\}[^[:space:]]" eg.text 拆开 grep "^# [[:space:]] \{1,\} [^[:space:]]" eg.text grep -E "^#\s\{1,\}\S" eg.text 拆开 grep -E "^# \s \{1,\} \S" eg.text 2、匹配 eg.text 中以 包含了 :一个数字: 的行 grep ":[[:digit:]]:" eg.text 拆开 grep ": [[:digit:]] :" eg.text grep -P ":\d:" eg.text 拆开 grep -P ": \d :" eg.text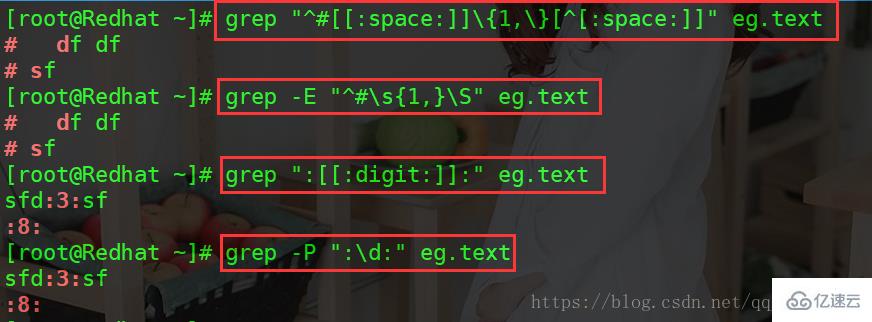
分组的例子
grep "l..e.*l..er" test.txt grep "\(l..e\).*\1r" test.txt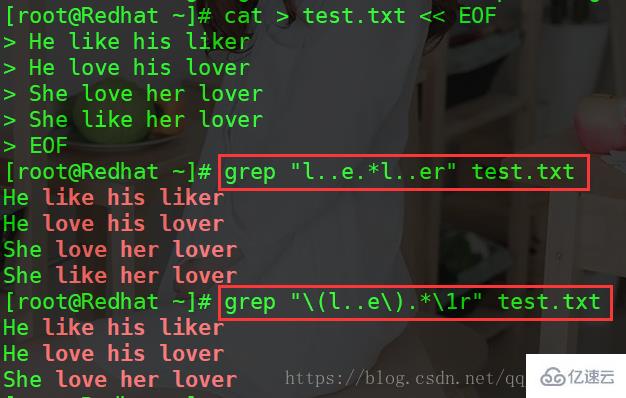
匹配 1-255 的数字
grep -E "\" num.txt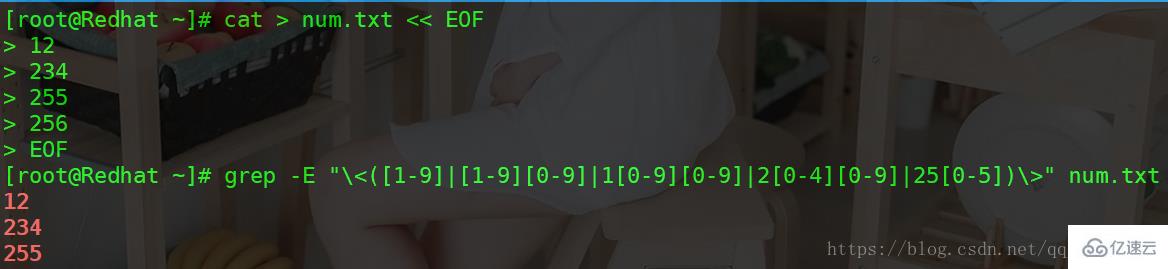
匹配Email地址:任意长度数字字母@任意长度数字字母
grep -E "^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$" email.txt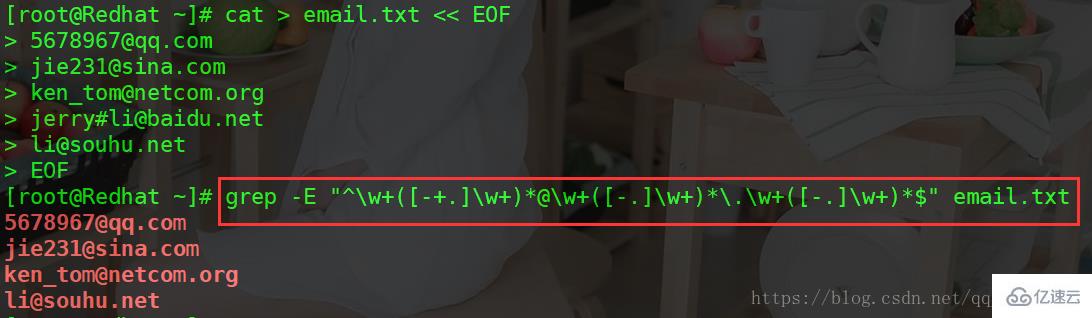
匹配手机号码,把手机号码是1[3|4|5|8]后面接9位数字的过滤出来
grep -E "\" tel.txt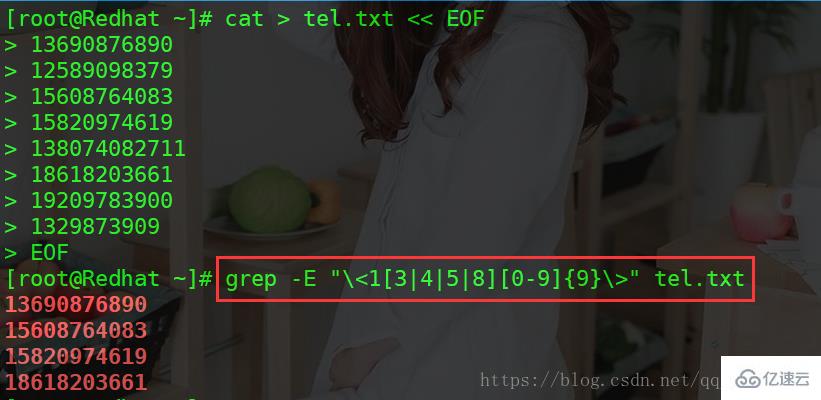
看完上述内容,你们掌握Linux grep命令具体使用方法是什么的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注编程网行业资讯频道,感谢各位的阅读!







