
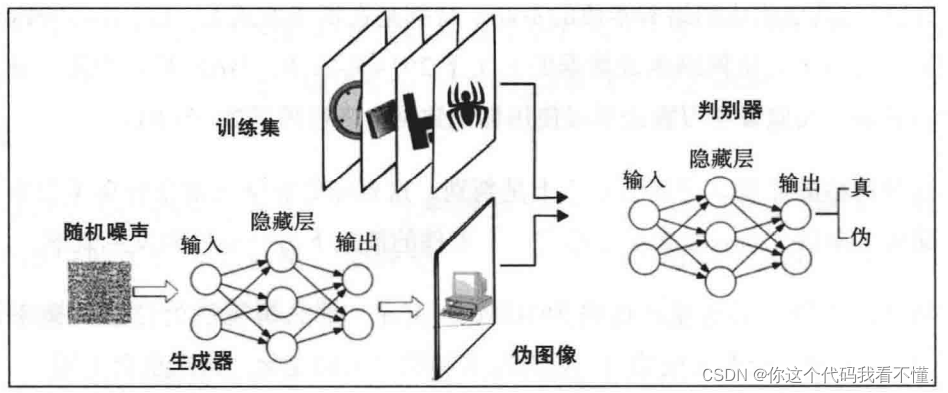
GAN介绍
理解GAN的直观方法是从博弈论的角度来理解它。GAN由两个参与者组成,即一个生成器和一个判别器,它们都试图击败对方。生成备从分巾中狄取一些随机噪声,并试图从中生成一些类似于输出的分布。生成器总是试图创建与真实分布没有区别的分布。也就是说,伪造的输出看起来应该是真实的图像。 然而,如果没有显式训练或标注,那么生成器将无法判别真实的图像,并且其唯一的来源就是随机浮点数的张量。
之后,GAN将在博弈中引入另一个参与者,即判别器。判别器仅负责通知生成器其生成的输出看起来不像真实图像,以便生成器更改其生成图像的方式以使判别器确信它是真实图像。 但是判别器总是可以告诉生成器其生成的图像不是真实的,因为判别器知道图像是从生成器生成的。为了解决这个事情,GAN将真实的图像引入博弈中,并将判别器与生成器隔离。现在,判别器从一组真实图像中获取一个图像,并从生成器中获取一个伪图像,而它必须找出每个图像的来源。
最初,判别器什么都不知道,而是随机预测结果。 但是,可以将判别器的任务修改为分类任务。判别器可以将输入图像分类为原始图像或生成图像,这是二元分类。同样,我们训练判别器网络以正确地对图像进行分类,最终,通过反向传播,判别器学会了区分真实图像和生成图像。
代码实例
数据集简介:
本次实验我们选用花卉数据集做图像的生成,本数据集共六类。

模型训练
训练判别器:
对于真图片,输出尽可能是1
对于假图片,输出尽可能是0
训练生成器:
对于假图片,输出尽可能是1
1、训练生成器时,无须调整判别器的参数;训练判别器时,无须调整生成器的参数。
2、在训练判别器时,需要对生成器生成的图片用detach操作进行计算图截断,避免反向传播将梯度传到生成器中。因为在训练判别器时我们不需要训练生成器,也就不需要生成器的梯度。
3、在训练判别器时,需要反向传播两次,一次是希望把真图片判为1,一次是希望把假图片判为0。也可以将这两者的数据放到一个batch中,进行一次前向传播和一次反向传播即可。
4、对于假图片,在训练判别器时,我们希望它输出0;而在训练生成器时,我们希望它输出1.因此可以看到一对看似矛盾的代码 error_d_fake = criterion(output, fake_labels)和error_g = criterion(output, true_labels)。判别器希望能够把假图片判别为fake_label,而生成器则希望能把他判别为true_label,判别器和生成器互相对抗提升。
import osimport torchfrom torch.utils.data import Dataset, DataLoaderfrom dataloader import MyDatasetfrom model import Generator, Discriminatorimport torchvisionimport numpy as npimport matplotlib.pyplot as pltif __name__ == '__main__': LR = 0.0002 EPOCH = 1000 # 50 BATCH_SIZE = 40 N_IDEAS = 100 EPS = 1e-10 TRAINED = False #path = r'./data/image' train_data = MyDataset(path=path, resize=96, Len=10000, img_type='jpg') train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) torch.cuda.empty_cache() if TRAINED: G = torch.load('G.pkl').cuda() D = torch.load('D.pkl').cuda() else: G = Generator(N_IDEAS).cuda() D = Discriminator(3).cuda() optimizerG = torch.optim.Adam(G.parameters(), lr=LR) optimizerD = torch.optim.Adam(D.parameters(), lr=LR) for epoch in range(EPOCH): tmpD, tmpG = 0, 0 for step, x in enumerate(train_loader): x = x.cuda() rand_noise = torch.randn((x.shape[0], N_IDEAS, 1, 1)).cuda() G_imgs = G(rand_noise) D_fake_probs = D(G_imgs) D_real_probs = D(x) p_d_fake = torch.squeeze(D_fake_probs) p_d_real = torch.squeeze(D_real_probs) D_loss = -torch.mean(torch.log(p_d_real + EPS) + torch.log(1. - p_d_fake + EPS)) G_loss = -torch.mean(torch.log(p_d_fake + EPS)) # D_loss = -torch.mean(torch.log(D_real_probs) + torch.log(1. - D_fake_probs)) # G_loss = torch.mean(torch.log(1. - D_fake_probs)) optimizerD.zero_grad() D_loss.backward(retain_graph=True) optimizerD.step() optimizerG.zero_grad() G_loss.backward(retain_graph=True) optimizerG.step() tmpD_ = D_loss.cpu().detach().data tmpG_ = G_loss.cpu().detach().data tmpD += tmpD_ tmpG += tmpG_ tmpD /= (step + 1) tmpG /= (step + 1) print( 'epoch %d avg of loss: D: %.6f, G: %.6f' % (epoch, tmpD, tmpG) ) # if (epoch+1) % 5 == 0: select_epoch = [1, 5, 10, 20, 50, 80, 100, 150, 200, 400, 500, 800, 999, 1500, 2000, 3000, 4000, 5000, 6000, 8000, 9999] if epoch in select_epoch:plt.imshow(np.squeeze(G_imgs[0].cpu().detach().numpy().transpose((1, 2, 0))) * 0.5 + 0.5) plt.savefig('./result1/_%d.png' % epoch) torch.save(G, 'G.pkl') torch.save(D, 'D.pkl')下面是训练多次的效果





完整代码如下:
# import osimport torchimport torch.nn as nnimport torchvision as tvfrom torch.autograd import Variableimport tqdmimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签plt.rcParams['axes.unicode_minus'] = False# dir = '... your path/faces/'dir = './data/train_data'# path = []## for fileName in os.listdir(dir):# path.append(fileName) # len(path)=51223noiseSize = 100 # 噪声维度n_generator_feature = 64 # 生成器feature map数n_discriminator_feature = 64 # 判别器feature map数batch_size = 50d_every = 1 # 每一个batch训练一次discriminatorg_every = 5 # 每五个batch训练一次generatorclass NetGenerator(nn.Module): def __init__(self): super(NetGenerator,self).__init__() self.main = nn.Sequential( # 神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行 nn.ConvTranspose2d(noiseSize, n_generator_feature * 8, kernel_size=4, stride=1, padding=0, bias=False), nn.BatchNorm2d(n_generator_feature * 8), nn.ReLU(True), # (n_generator_feature * 8) × 4 × 4 (1-1)*1+1*(4-1)+0+1 = 4 nn.ConvTranspose2d(n_generator_feature * 8, n_generator_feature * 4, kernel_size=4, stride=2, padding=1, bias=False), nn.BatchNorm2d(n_generator_feature * 4), nn.ReLU(True), # (n_generator_feature * 4) × 8 × 8 (4-1)*2-2*1+1*(4-1)+0+1 = 8 nn.ConvTranspose2d(n_generator_feature * 4, n_generator_feature * 2, kernel_size=4, stride=2, padding=1, bias=False), nn.BatchNorm2d(n_generator_feature * 2), nn.ReLU(True), # (n_generator_feature * 2) × 16 × 16 nn.ConvTranspose2d(n_generator_feature * 2, n_generator_feature, kernel_size=4, stride=2, padding=1, bias=False), nn.BatchNorm2d(n_generator_feature), nn.ReLU(True), # (n_generator_feature) × 32 × 32 nn.ConvTranspose2d(n_generator_feature, 3, kernel_size=5, stride=3, padding=1, bias=False), nn.Tanh() # 3 * 96 * 96 ) def forward(self, input): return self.main(input)class NetDiscriminator(nn.Module): def __init__(self): super(NetDiscriminator,self).__init__() self.main = nn.Sequential( nn.Conv2d(3, n_discriminator_feature, kernel_size=5, stride=3, padding=1, bias=False), nn.LeakyReLU(0.2, inplace=True), # n_discriminator_feature * 32 * 32 nn.Conv2d(n_discriminator_feature, n_discriminator_feature * 2, kernel_size=4, stride=2, padding=1, bias=False), nn.BatchNorm2d(n_discriminator_feature * 2), nn.LeakyReLU(0.2, inplace=True), # (n_discriminator_feature*2) * 16 * 16 nn.Conv2d(n_discriminator_feature * 2, n_discriminator_feature * 4, kernel_size=4, stride=2, padding=1, bias=False), nn.BatchNorm2d(n_discriminator_feature * 4), nn.LeakyReLU(0.2, inplace=True), # (n_discriminator_feature*4) * 8 * 8 nn.Conv2d(n_discriminator_feature * 4, n_discriminator_feature * 8, kernel_size=4, stride=2, padding=1, bias=False), nn.BatchNorm2d(n_discriminator_feature * 8), nn.LeakyReLU(0.2, inplace=True), # (n_discriminator_feature*8) * 4 * 4 nn.Conv2d(n_discriminator_feature * 8, 1, kernel_size=4, stride=1, padding=0, bias=False), nn.Sigmoid() # 输出一个概率 ) def forward(self, input): return self.main(input).view(-1)def train(): for i, (image,_) in tqdm.tqdm(enumerate(dataloader)): # type((image,_)) = , len((image,_)) = 2 * 256 * 3 * 96 * 96 real_image = Variable(image) real_image = real_image.cuda() if (i + 1) % d_every == 0: optimizer_d.zero_grad() output = Discriminator(real_image) # 尽可能把真图片判为True error_d_real = criterion(output, true_labels) error_d_real.backward() noises.data.copy_(torch.randn(batch_size, noiseSize, 1, 1)) fake_img = Generator(noises).detach() # 根据噪声生成假图 fake_output = Discriminator(fake_img) # 尽可能把假图片判为False error_d_fake = criterion(fake_output, fake_labels) error_d_fake.backward() optimizer_d.step() if (i + 1) % g_every == 0: optimizer_g.zero_grad() noises.data.copy_(torch.randn(batch_size, noiseSize, 1, 1)) fake_img = Generator(noises) # 这里没有detach fake_output = Discriminator(fake_img) # 尽可能让Discriminator把假图片判为True error_g = criterion(fake_output, true_labels) error_g.backward() optimizer_g.step()def show(num): fix_fake_imags = Generator(fix_noises) fix_fake_imags = fix_fake_imags.data.cpu()[:64] * 0.5 + 0.5 # x = torch.rand(64, 3, 96, 96) fig = plt.figure(1) i = 1 for image in fix_fake_imags: ax = fig.add_subplot(8, 8, eval('%d' % i)) # plt.xticks([]), plt.yticks([]) # 去除坐标轴 plt.axis('off') plt.imshow(image.permute(1, 2, 0)) i += 1 plt.subplots_adjust(left=None, # the left side of the subplots of the figure right=None, # the right side of the subplots of the figure bottom=None, # the bottom of the subplots of the figure top=None, # the top of the subplots of the figure wspace=0.05, # the amount of width reserved for blank space between subplots hspace=0.05) # the amount of height reserved for white space between subplots) plt.suptitle('第%d迭代结果' % num, y=0.91, fontsize=15) plt.savefig("images/%dcgan.png" % num)if __name__ == '__main__': transform = tv.transforms.Compose([ tv.transforms.Resize(96), # 图片尺寸, transforms.Scale transform is deprecated tv.transforms.CenterCrop(96), tv.transforms.ToTensor(), tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 变成[-1,1]的数 ]) dataset = tv.datasets.ImageFolder(dir, transform=transform) dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4, drop_last=True) # module 'torch.utils.data' has no attribute 'DataLoder' print('数据加载完毕!') Generator = NetGenerator() Discriminator = NetDiscriminator() optimizer_g = torch.optim.Adam(Generator.parameters(), lr=2e-4, betas=(0.5, 0.999)) optimizer_d = torch.optim.Adam(Discriminator.parameters(), lr=2e-4, betas=(0.5, 0.999)) criterion = torch.nn.BCELoss() true_labels = Variable(torch.ones(batch_size)) # batch_size fake_labels = Variable(torch.zeros(batch_size)) fix_noises = Variable(torch.randn(batch_size, noiseSize, 1, 1)) noises = Variable(torch.randn(batch_size, noiseSize, 1, 1)) # 均值为0,方差为1的正态分布 if torch.cuda.is_available() == True: print('Cuda is available!') Generator.cuda() Discriminator.cuda() criterion.cuda() true_labels, fake_labels = true_labels.cuda(), fake_labels.cuda() fix_noises, noises = fix_noises.cuda(), noises.cuda() plot_epoch = [1,5,10,50,100,200,500,800,1000,1500,2000,2500,3000] for i in range(3000): # 最大迭代次数 train() print('迭代次数:{}'.format(i)) if i in plot_epoch: show(i)来源地址:https://blog.csdn.net/weixin_45807161/article/details/123776427







