
再实际开发应用中总会面临导入大批量数据插入数据库、数据迁移、同步等操作在java 后台执行,执行效率的优化问题随之而来!比如如何快速往MySQL数据库中导入1000万数据
MySQL中新建一张user表,为了方便演示只保留id、昵称、年龄3个字段,建表语句;

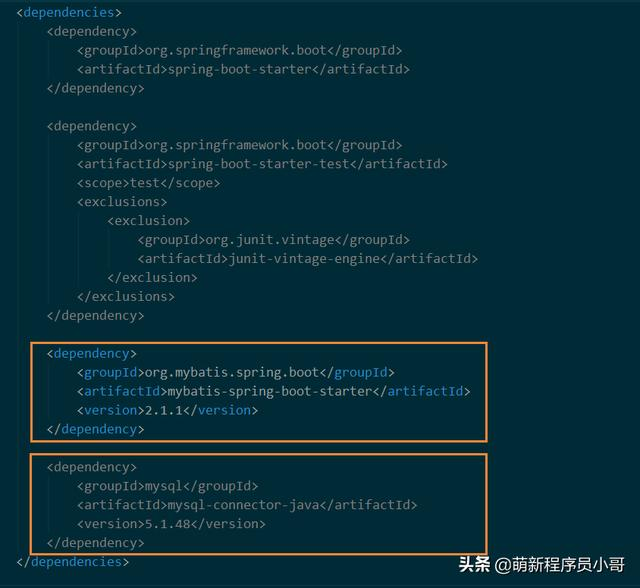
再次打开pom.xml文件,添加mybatis generator插件用于自动生成mapper映射文件;

上一步添加了mybatis generator插件之后还不能直接使用,还需要在项目resources目录下新建一个配置文件generatorConfig.xml,里面主要需要配置数据库连接信息、Model文件生成目录、Mapper文件生成目录、以及xml文件生成目录;

打开resources目录下的application.properties(或是application.yml)文件,添加一下mybatis相关配置和项目数据库连接配置;

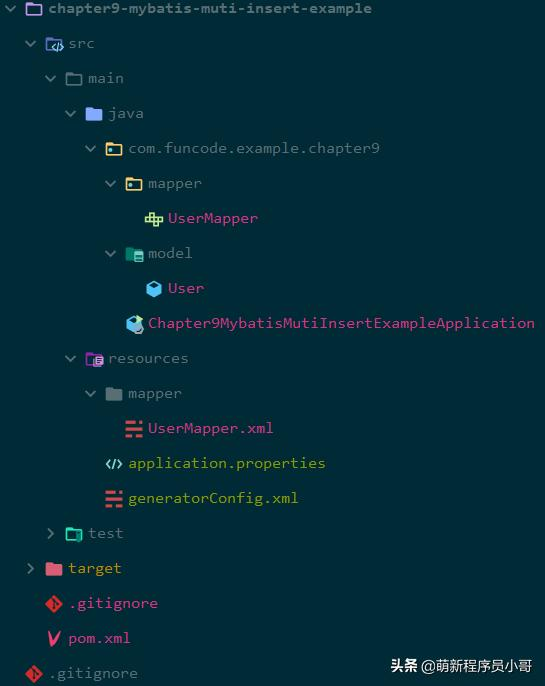
展示一下项目的完整结构
首先我们用Mybatis来测试一下,看看插入1000万条数据需要多长时间。
实现步骤:
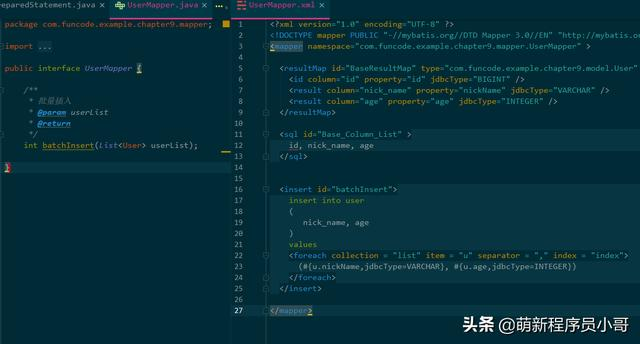
在UserMapper.java和UserMapper.xml文件中实现批量插入方法;
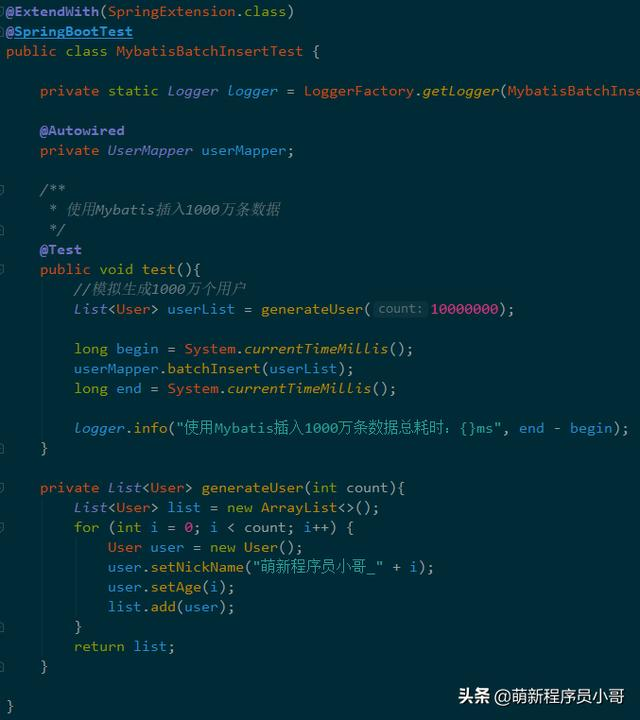
新建一个Test测试类实现随机生成1000万用户记录,并调用上步已经实现的批量插入方法将数据插入到MySQL数据库;
接下来就是正式测试了,没想到中间出了不少问题,在这里说明一下并附上解决方案。
问题一:Java堆内存爆了!
原因分析:由于要生成1000万条用户记录,需要申请大量Java的堆内存,已经超出JVM设置的最大堆内存大小,导致OutOfMemoryError报错:
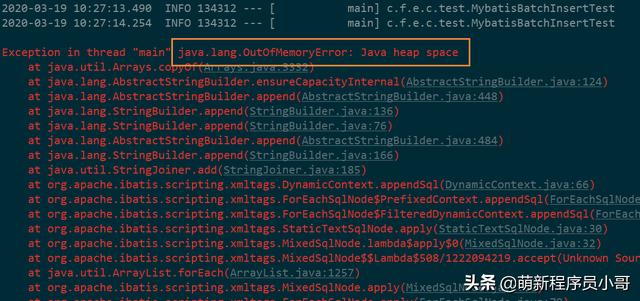
解决办法:增加堆内存。
JVM设置堆内存有两个参数:
- -Xms 用于设置堆内存初始值,一般建议设置为和最大值一样;
- -Xmx 用于设置堆内存最大值,默认值为物理内存的1/4;
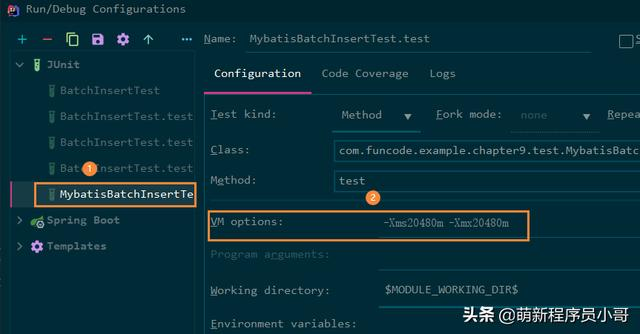
因为我的电脑是32G内存,也就是说默认最大堆内存有8G,8G都不够的话,那我直接来个20G试试,IDEA菜单栏依次打开Run -> Edit Configurations:
修改步骤:
- 选中我们的测试类
- 在右边找到VM options选项,输入-Xms20480m -Xmx20480m
问题二:MySQL报错:Packet for query is too large
原因分析:因为发送到MySQL的数据量过大,超出了设置的最大值,导致报错:
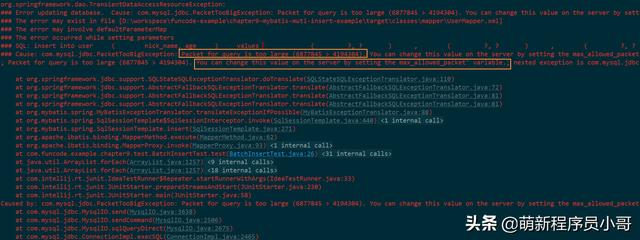
解决方案:修改MySQL服务器max_allowed_packet属性。
修改步骤:
- 直接在MySQL安装目录下找到my.ini文件,在[mysqld]下面添加一行max_allowed_packet = 4G
- 通过MySQL客户端工具修改,这里以我常用的MySQL Workbench客户端来修改,菜单栏找到Server -> Options File,点击切换Networking标签:
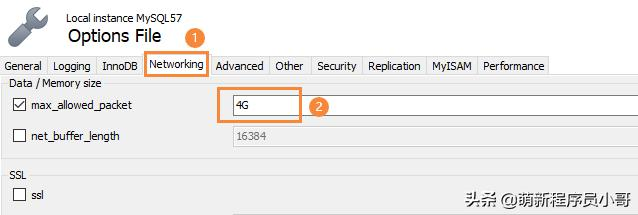
Tip:不论哪种方式,修改完都要记得重启MySQL,否则修改不生效哦。
我们来看下执行结果:

结果:
使用Mybatis插入1000万条数据到MySQL数据库共花费了199.8秒!
这结果是快还是慢?我们来具体分析一下耗时分布情况。
分析:
方法:
JDBC驱动中有一个profileSQL属性,可以跟踪记录SQL执行时间,附上官方文档介绍:

所以我们需要将数据库连接加上profileSQL=true属性。
再次看下执行结果:

其中,duration指的是SQL执行的时间,也就是说MySQL服务器执行具体SQL语句的时间其实只有82.3秒,我们上面统计到Mybatis插入1000万条数据花了近200秒的时间,那么这中间的100多秒都干嘛去了?
分析控制台输出的日志之后我发现了蹊跷所在:从程序调用Mybatis的批量插入方法开始,到MySQL服务器执行SQL,这中间正好差了100多秒,会是巧合吗?
打断点Debug追踪到Mybatis解析SQL语句的方法:
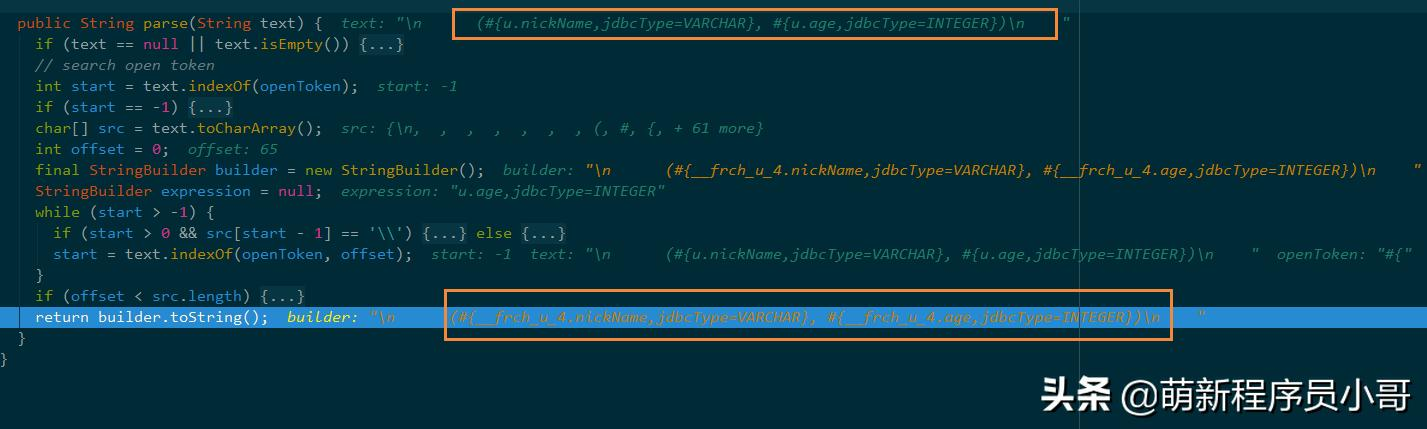
这parse方法首先会读取我们xml文件里的SQL模版拿到参数及参数类型信息,拼接生成SQL语句。
每条数据循环一次,那1000W条数据就要循环解析1000万次,不慢才怪!
注意: MySQL的JDBC连接的url中要加rewriteBatchedStatements参数,并保证5.1.13以上版本的驱动,才能实现高性能的批量插入 MySQL JDBC驱动在默认情况下会无视executeBatch()语句,把我们期望批量执行的一组SQL语句拆散,一条一条地发给MySQL数据库,批量插入实际上是单条插入,直接造成较低的性能 url: jdbc:mysql://127.0.0.1:3306/test1?allowMultiQueries=true&rewriteBatchedStatements=true //allowMultiQueries=true,允许一次性执行多条SQL,批量插入时必须在连接地址后面加allowMultiQueries=true这个参数 //rewriteBatchedStatements=true,批量将数据传给MySQL,数据库会更高性能的执行批量处理,MySQL数据库版本在5.1.13以上,才能实现高性能的批量插入
接下来使用Spring框架的JdbcTemplate来测试一下。
实现步骤:
- 同样的我们新建一个测试类,并用JdbcTemplate实现一个批量插入方法;

接下来就可以开始测试了,果然中间又出现了了问题。
问题一:调用JdbcTemplate的batchUpdate批量操作方法,结果却一条条的插数据?
首先看下控制台输出日志:
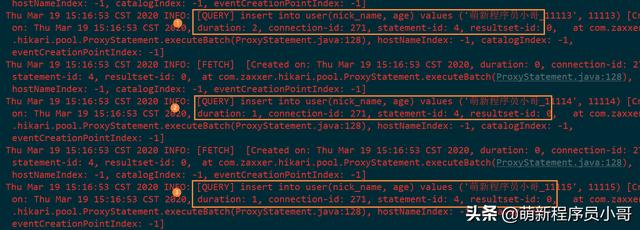
可以看到JdbcTemplate是将我们的数据一条条的发送到MySQL服务器的,每个插入耗时1毫秒,那么1秒钟可以插入1000条记录,那么1000万条数据就需要10000秒,大约需要2.78个小时。
原因分析:JDBC驱动默认不支持批量操作,会将SQL语句分拆再一条条发往MySQL服务器执行,打断点跟踪一下代码,看看是不是这样:

分析一下代码:
- 首先执行步骤1判断rewriteBatchedStatements属性,为false的话直接执行步骤5的逻辑:串行执行SQL语句,也就是一条条顺序执行;
- 如果rewriteBatchedStatements为true,那么首先会执行步骤2:判断是否为insert语句,结果为true则会改写SQL执行批量插入操作;
- 如果不是insert语句,再继续根据JDBC驱动版本以及数据量大小判断是否需要执行批量操作;
Tip:对于非insert的批量操作语句,如果数据量小于3条,那也只会一条条顺序执行,不会进行合并批量执行。
附上rewriteBatchedStatements官方文档:

大概看了一下,跟我们上面分析的一样,标示是否让JDBC驱动使用批量模式去改写SQL语句。
解决方案:数据库连接上加上rewriteBatchedStatements=true属性,开启批量操作支持。
再次看下执行结果:

结果:
使用JdbcTemplate插入1000万条数据到MySQL数据库共花费了80.1秒!
分析:
一开始由于没有开启批量操作支持,所以导致MySQL只能一条条插入数据,原因在于我对JDBC驱动不够了解,看来以后还得加强学习。
开启批量操作支持后,通过日志可以观察到真正的SQL执行时间只有67.9秒,但整个插入操作用了80.1秒,中间差的10多秒中应该就是消耗在了改写SQL语句上了。
总得来说,JdbcTemplate批量插入大量数据的效率还不错,让我有眼前一亮的感觉。
早有耳闻批量插入大量数据必须使用原生JDBC,百闻不如一见,接下来我就使用原生JDBC的方式来测试一下。
实现步骤:
- 同样的,我们新建一个测试类,并使用原生JDBC的方式实现一个批量插入方法;
接下来就可以测试了,别担心,这次肯定不会再出问题了。
来看下执行结果:
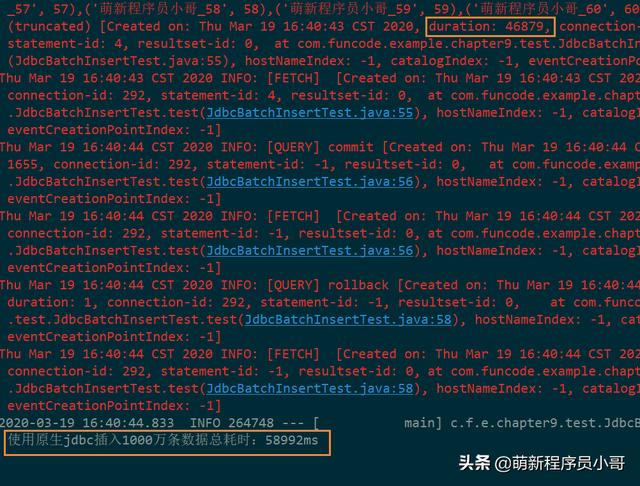
结果:使用原生JDBC的方式插入1000万条数据到MySQL数据库共花费了58.9秒!
分析:
原生JDBC写起来还是既简单又舒适啊,都多少年没写过了,但是越是简单的东西它越好用。
通过输出日志,我们可以看到整个方法执行时间为58.9秒,而SQL真正的执行时间为46.8秒,中间同样相差了10多秒,同样也是花在了改写SQL语句上,这一结果正好与上面JdbcTemplate的执行结果互相佐证,证明了我们的分析是正确的。
最后使用存储过程的方式来试一下,说实话工作以来很少写存储过程,只好临时恶补了一波知识。
实现步骤:
- 首先编写批量插入的存储过程,功能其实很简单,接收一个外部传入的表示循环次数的参数,进行循环插入数据;
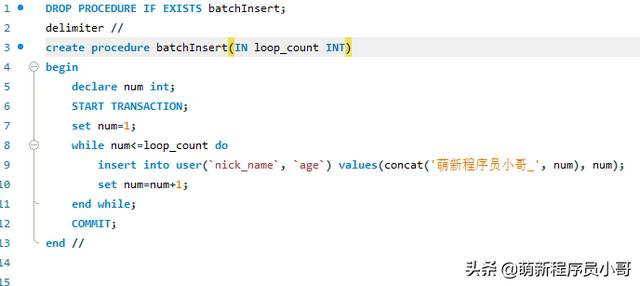
接下来我们调用存储过程,执行命令:
CALL batchInsert(10000000); 等待执行完成,看下耗时情况:
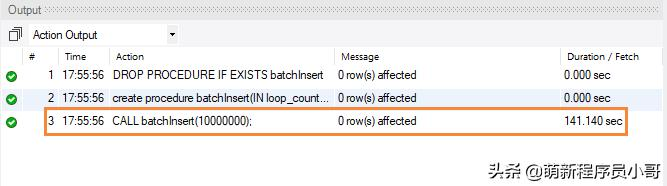
结果:
调用存储过程向MySQL数据库中批量插入1000万数据需要141.1秒。
分析:
存储过程需要141.1秒的时间我还是比较惊讶的,本来我对存储过程还是比较期待的。
仔细想想,其实存储过程用在这个场景并没有发挥出它的优势,时间长点也不奇怪。
为什么这么说?
首先我们来看看存储过程的一些特点:
- 可以封装一些复杂的业务逻辑,外部直接调用存储过程即可;
- 存储过程只在创建时编译一次,以后每次执行存储过程都不需再重新编译,使用存储过程可提高执行速度;
- 将操作直接放到数据库端执行,可以减少客户端与服务端进行网络通讯开销,提高通信效率;
其次我们再来看看存储过程用在我们场景是否合适:
- 我们使一次性提交所有数据,所以不存在多次通信增加耗时的操作,在这里存储过程的优势没有发挥出来;
- 在存储过程的insert语句中,我们使用了concat函数来拼接字符串,函数运算会降低SQL执行效率;
所以说存储过程在我们这个业务场景并没有发挥出它的优势。
面对快速往MySQL数据库中导入1000万数据这个问题,我们通过Mybatis、JdbcTemplate、原生JDBC以及存储过程4种方式分别进行测试,得出了最终结果:
插入速度:原生JDBC > JdbcTemplate > 存储过程 > Mybatis
结果分析:
Mybatis由于封装程度较高,底层有一个SQL模版解析和SQL拼接的过程,所以导致速度较慢;
存储过程一来由于本应用场景不太适合没有发挥出优势,二来由于SQL语句中加入了函数运算拖累了执行效率;
JdbcTemplate是Spring框架为了方便开发者调用对原生JDBC的一个轻度封装,虽然有点小插曲,但整体来看插入效率还可以;
转载:https://blog.csdn.net/zl1zl2zl3/article/details/105007492
来源地址:https://blog.csdn.net/javaXingzhe/article/details/129278041







