
目前互联网上充斥着大量的关于RESTfulAPI(为了方便,以后API和RESTfulAPI一个意思)如何设计的文章,然而却没有一个”万能“的设计标准:如何鉴权?API格式如何?你的API是否应该加入版本信息?当你开始写一个app的时候,特别是后端模型部分已经写完的时候,你不得不殚精竭虑的设计和实现自己app的publicAPI部分。因为一旦发布,对外发布的API将会很难改变。
即使如此,Facebook、谷歌、Github、Netflix和几个其他的科技巨头已经允许开发者和其产品通过API调用他们的数据,并为他们提供平台。即使你不是写API的专业人士,拥有精美的API也对你的应用程序有好处。
关于设计API的最好方法,网络上有较长一段时间的争论,但官方也没有对此给出解释。
API是一个接口,通过它许多开发者可与数据交互。设计优良的API使用起来很方便,并给开发者的工作带来便利。API是开发者的GUI,如果它设计不合理,开发者会将它替换。所以,开发者的经验是衡量API质量的最重要的指标。

一、术语
以下是与RESTAPI相关的重要术语:
资源(Resource)是一个对象或对某物的表示。它有一些相关联的数据,并有一组方法进行操作。例如:动物,学校和员工是资源。这些资源都有着删除,添加,更新操作。
集合(Collection)是一系列资源,例如:公司集合是很多公司的集合。
URL(统一资源定位符)是一种路径,可以通过它定位资源并且也可以对它执行一些动作。
二、API设计的基本要求
1.当标准合理的时候遵守标准。
2.API应该对程序员友好,并且在浏览器地址栏容易输入。
3.API应该简单,直观,容易使用的同时优雅。
4.API应该具有足够的灵活性来支持上层ui。
5.API设计权衡上述几个原则。
三、使用RESTfulURLs和action.
虽然前面我说没有一个万能的API设计标准。但确实有一个被普遍承认和遵守:RESTfu设计原则。它被RoyFelding提出(在他的”基于网络的软件架构“论文中第五章)。而REST的核心原则是将你的API拆分为逻辑上的资源。这些资源通过http被操作(GET,POST,PUT,DELETE)。
四、那么我应该如何拆分出这些资源呢?
显然从API用户的角度来看,”资源“应该是个名词。即使你的内部数据模型和资源已经有了很好的对应,API设计的时候你仍然不需要把它们一对一的都暴露出来。这里的关键是隐藏内部资源,暴露必需的外部资源。
在SupportFu里,资源是ticket、user、group。
一旦定义好了要暴露的资源,你可以定义资源上允许的操作,以及这些操作和你的API的对应关系:
1.GET/tickets#获取ticket列表
2.GET/tickets/12#查看某个具体的ticket
3.POST/tickets#新建一个ticket
4.PUT/tickets/12#更新ticket12.
5.DELETE/tickets/12#删除ticekt12
可以看出使用REST的好处在于可以充分利用http的强大实现对资源的CURD功能。而这里你只需要一个endpoint:/tickets,再没有其他什么命名规则和url规则了,cool!
五、API端点(路径)
为了更好理解,我们给公司写API,这些公司都有一些员工。/getAllEmployees是对员工列表进行回应的API。公司其他API大致如下:
/addNewEmployee
/updateEmployee
/deleteEmployee
/deleteAllEmployees
/promoteEmployee
/promoteAllEmployees
并且将有大量的和这些操作不同的API端点,它们包含大量冗余的行为。因此,当API数量增加时,这些API端点将很难维护。
哪里不对?
每个URL代表一种资源(Resource),所以URL中只能有名词,不能有动词。API路径/addNewEmployee包含了操作addNew和资源名称Employee。
那么怎样算是正确的方式?
/companies是一个很好的不包含操作的例子。但是问题来了,我们该怎样告诉服务器我们要进行的操作呢?新增,删除,还是更新?
这时HTTP方法(GET,POST,DELETE,PUT)(也称为动词)就可以起到作用了。
资源在API端点中应该总是复数,如果我们想访问资源的一个实例,我们可以传递URL中的id。
方法GET路径/companies是获取所有公司的列表。
方法GET路径/companies/34是获取公司34的详细信息。
方法DELETE路径/companies/34是删除公司34.
在其他的一些使用案例中,如果我们有一些资源在某个资源之下,例如,一个公司的员工,那么在这样的例子中API的endpoint(端点)就应该是这样的:
GET/companies/3/employees可以取得编号为3的公司的员工列表
GET/companies/3/employees/45可以取得编号为3的公司的45号员工的细节信息
DELETE/companies/3/employees/45可以删除编号为3的公司的45号员工
POST/companies可以创建一个新公司并返回新创建公司的细节信息
现在这样,API是不是更严谨和一致了呢?
结论:路径应该包含资源的复数形式,HTTP方法应该定义成各种行为在资源上执行。
六、HTTP方法(动词)
HTTP定义了几组方法,这些方法给出了对资源要执行的操作类型。
URL是一个句子,其中资源是名词,HTTP方法是动词。
主要的HTTP方法如下:
GET方法从资源请求数据,不产生多余结果。
例如:/companies/3/employees会返回公司3的所有雇员列表。
POST方法请求服务器在数据库中创建资源,这主要用于提交Web表单时。
例如:/companies/3/employees创建一个公司3的新雇员。
POST是非幂等的,这意味着多个请求将会有不同的效果。
PUT方法请求服务器更新资源或创建资源(如果不存在的话)。
例如:/companies/3/employees/john将请求服务器在公司3的雇员集合中更新或在不存在的情况下创建关于john的资源。
PUT是幂等的,这意味着多次请求具有相同的效果。
DELETE方法将请求的资源或实例从数据库中删除。
例如:/companies/3/employees/john/将请求服务器从公司3的雇员集中删除john资源。
HTTP中还有很多其他方法,我们将在另一篇文章中讨论。
七、HTTP响应状态码
当客户端通过API向服务器发起请求时,无论请求是失败的、通过的还是错误的,客户端应该获得反馈。HTTP状态码是一堆标准化的数值码,在不同的情况下具有不同的解释。服务器应始终返回正确的状态码。
以下是HTTP状态码的主要分类:
2xx(成功类别)
这些状态代码表示请求的操作已被服务器接收到并成功处理。
200Ok:标准的HTTP响应,表示GET、PUT或POST的处理成功。
201Created:在创建新实例时,应返回此状态代码。例如,使用POST方法创建一个新的实例,应该始终返回201状态码。
204内容不存在:表示请求已被成功处理,但并未返回任何内容。
DELETE算是其中一个很好的例子。
APIDELETE/companies/43/employees/2将删除员工2,作为响应,我们不需要在该API的响应正文中的任何数据,因为我们明确地要求系统将其删除。如果有任何错误发生,例如,如果员工2在数据库中不存在,那么响应码将不是2xx对应的成功类别,而是4xx客户端错误类别。
3xx(重定向类别)
304未修改:表示客户端的响应已经在其缓存中。因此,不需要再次传送相同的数据。
4xx(客户端错误类别)
这些状态代码表示客户端发起了错误的请求。
400错误请求:表示客户端的请求没有被处理,因为服务器不能理解客户端请求的是什么。
401未授权:表示客户端不被允许访问该资源,需要使用指定凭证重新请求。
403禁止访问:表示请求是有效的并且客户端已通过身份验证,但客户端不被允许以任何理由访问对应页面或资源。例如有时授权的客户端不被允许访问服务器上的目录。
404未找到:表示所请求的资源现在不可用。
410资源不可用:表示所请求的资源后续不再可用,该资源已被移动。
5xx(服务器错误类别)
500是服务器内部错误,表示请求已经被接收到了,但服务器被要求处理某些未预设的请求而完全混乱。
503服务不可用表示服务器已关闭或无法接收和处理请求。大多数情况是服务器正在进行维护。
八、字段套管约定
您可以遵循任何套管约定,但要确保其在应用程序中一致。如果请求主体或响应类型是JSON,那么请按照camelCase(驼峰命名法)来保持一致。
九、搜索、排序、过滤和分页
这些行为都只是针对一个数据集进行的查询。由于还没有一套新的API来处理这些行为。因此,我们需要向GET方法的API附加查询参数。
我们来理解几个例子看它们是如何实现这些行为的。
排序(sorting),客户端想要获得排序后的公司列表,GET/companies端点应当接受多个查询排序参数。
例如,GET/companies?sort=rank_asc将根据等级以升序的方式对公司进行排序。
过滤(Filtering),用来过滤数据集,我们可以通过查询参数传递不同的选项。
例如,GET/companies?category=banking&location=india将根据公司类别为银行以及所处位置为印度来过滤公司的列表数据。
搜索(Searching),当需要在公司列表中搜索公司名称时,API端点应当是GET/companies?search=DigitalMckinsey。
分页(Pagination),当数据集太大时,我们将数据集分成更小的块,这样有助于提高性能,并且更易于处理响应。例如,GET/companies?page=23表示获取第23页的公司列表。
如果在GET方法中附加了很多查询参数,会造成URI太长,服务器可能会响应414的HTTP状态,表示这个URI太长,在这种情况下,我们也可以将参数传递给POST方法的请求体中。
十、限制API返回值的域
有时候API使用者不需要所有的结果,在进行横向限制的时候(例如值返回API结果的前十项)还应该可以进行纵向限制。并且这个功能能有效的提高网络带宽使用率和速度。可以使用fields查询参数来限制返回的域例如:
GET/ticketsfields=id,subject,customer_name,updated_at&state=open&sort=-updated_at
十一、更新和创建操作应该返回资源
PUT、POST、PATCH操作在对资源进行操作的时候常常有一些副作用:例如created_at,updated_at时间戳。为了防止用户多次的API调用(为了进行此次的更新操作),我们应该会返回更新的资源(updatedrepresentation.)例如:在POST操作以后,返回201created状态码,并且包含一个指向新资源的url作为返回头
十二、是否需要“HATEOAS“
网上关于是否允许用户创建新的url有很大的异议(注意不是创建资源产生的url)。为此REST制定了HATEOAS来描述了和endpoint进行交互的时候,行为应该在资源的metadata返回值里面进行定义。
十三、只提供json作为返回格式
现在开始比较一下XML和json了。XML即冗长,难以阅读,又不适合各种编程语言解析。当然XML有扩展性的优势,但是如果你只是将它来对内部资源串行化,那么他的扩展优势也发挥不出来。很多应用(youtube,twitter,box)都已经开始抛弃XML了,我也不想多费口舌。给了google上的趋势图吧:
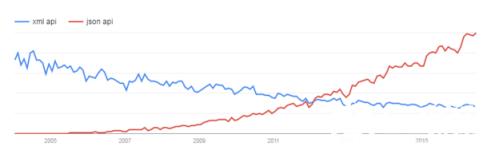
当然如果的你使用用户里面企业用户居多,那么可能需要支持XML。如果是这样的话你还有另外一个问题:你的http请求中的media类型是应该和accept头同步还是和url?为了方便(browserexplorability),应该是在url中(用户只要自己拼url就好了)。如果这样的话最好的方法是使用.xml或者.json的后缀。
十四、版本控制
当你的API被开始被广泛使用后,突然升级API会打破现有的产品、服务。
如果有任何重大的中断更新,我们可以将新的API集命名为v2或v1.x.x
小编结语:
更多内容尽在编程学习网教育!























