
本篇文档将介绍pdfbox处理pdf常用方法(读取、写入、合并、拆分、写文字、写图片)。
图中为pdfbox用到的包

1.读取pdf
方法代码:
public static String ReadPdf(String inputFile){ //创建文档对象 PDDocument doc =null; String content=""; try { //加载一个pdf对象 doc =PDDocument.load(new File(inputFile)); //获取一个PDFTextStripper文本剥离对象 PDFTextStripper textStripper =new PDFTextStripper(); content=textStripper.getText(doc); System.out.println("内容:"+content); System.out.println("全部页数"+doc.getNumberOfPages()); //关闭文档 doc.close(); } catch (Exception e) { e.printStackTrace(); } return content; }测试用例:
public static void main(String[] args) throws Exception { String content = ReadPdf("C:\\pdfFolder\\target.pdf"); System.out.println("内容如下:\n" + content);}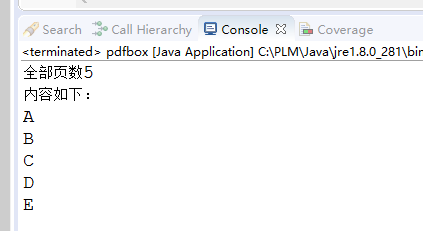
2.写入pdf
2.1写文字
方法代码:
public static void InsertPageContent (String inputFilePath, String outputFilePath, Integer pageNum, String message) throws Exception { File inputPDFFile = new File(inputFilePath); File outputPDFFile = new File(outputFilePath); // the document PDDocument doc = null; try{ doc = PDDocument.load(inputPDFFile); PDPageTree allPages = doc.getDocumentCatalog().getPages(); PDFont font = PDType1Font.HELVETICA_BOLD; //字体大小 float fontSize = 36.0f; PDPage page = (PDPage)allPages.get(pageNum - 1); PDRectangle pageSize = page.getMediaBox(); float stringWidth = font.getStringWidth(message)*fontSize/1000f; // calculate to center of the page int rotation = page.getRotation(); boolean rotate = rotation == 90 || rotation == 270; float pageWidth = rotate ? pageSize.getHeight() : pageSize.getWidth(); float pageHeight = rotate ? pageSize.getWidth() : pageSize.getHeight(); double centeredXPosition = rotate ? pageHeight/2f : (pageWidth - stringWidth)/2f; double centeredYPosition = rotate ? (pageWidth - stringWidth)/2f : pageHeight/2f; // append the content to the existing stream PDPageContentStream contentStream = new PDPageContentStream(doc, page, true, true,true); contentStream.beginText(); // set font and font size contentStream.setFont( font, fontSize ); // set text color to red contentStream.setNonStrokingColor(255, 0, 0); if (rotate) { // rotate the text according to the page rotation contentStream.setTextRotation(Math.PI/2, centeredXPosition, centeredYPosition); } else { contentStream.setTextTranslation(centeredXPosition, centeredYPosition); } contentStream.drawString(message); contentStream.endText(); contentStream.close(); doc.save(outputPDFFile); System.out.println("成功向pdf插入文字"); } finally { if( doc != null ) { doc.close(); } } }测试用例:
public static void main(String[] args) throws Exception { String inputFilePath = "C:\\pdfFolder\\A.pdf"; String outputFilePath = "C:\\pdfFolder\\A2.pdf"; //只能写英文,写中文会报错 InsertPageContent(inputFilePath, outputFilePath, 1, "testMessage");}A.pdf:

A2.pdf:

2.2写图片
方法代码:
public static void insertImage(String inputFilePath, String imagePath, String outputFilePath, Integer pageNum) throws Exception { File inputPDFFile = new File(inputFilePath); File outputPDFFile = new File(outputFilePath); try { PDDocument doc = PDDocument.load(inputPDFFile); PDImageXObject pdImage = PDImageXObject.createFromFile(imagePath, doc); PDPage page = doc.getPage(0); //注释的这行代码会覆盖原内容,没注释的那行不会覆盖// PDPageContentStream contentStream = new PDPageContentStream(doc, page); PDPageContentStream contentStream = new PDPageContentStream(doc, page, true, true, true); contentStream.drawImage(pdImage, 70, 250); contentStream.close(); doc.save(outputPDFFile); doc.close(); System.out.println("成功插入图片"); } catch (IOException e) { e.printStackTrace(); } }测试用例:
public static void main(String[] args) throws Exception { String inputFilePath = "C:\\pdfFolder\\A.pdf"; String outputFilePath = "C:\\pdfFolder\\A2.pdf"; String imagePath = "C:\\pdfFolder\\pic.jpg"; insertImage(inputFilePath, imagePath, outputFilePath, 1);}A.pdf:

pic.jpg:

A2.pdf:

3.合并pdf
方法代码:
public static void MergePdf(List pathList, String targetPDFPath) throws Exception { List inputStreams = new ArrayList<>(); for(String path : pathList) { inputStreams.add(new FileInputStream(new File(path))); } PDFMergerUtility mergePdf = new PDFMergerUtility(); File file = new File(targetPDFPath); if (!file.exists()) { file.delete(); } mergePdf.addSources(inputStreams); mergePdf.setDestinationFileName(targetPDFPath); mergePdf.mergeDocuments(); for (InputStream in : inputStreams) { if (in != null) { in.close(); } } } 测试用例:
public static void main(String[] args) throws Exception { List pathList = new ArrayList(); String targetPDFPath = "C:\\pdfFolder\\target.pdf"; pathList.add("C:\\pdfFolder\\A.pdf"); pathList.add("C:\\pdfFolder\\B.pdf"); pathList.add("C:\\pdfFolder\\C.pdf"); pathList.add("C:\\pdfFolder\\D.pdf"); pathList.add("C:\\pdfFolder\\E.pdf"); MergePdf(pathList, targetPDFPath); } 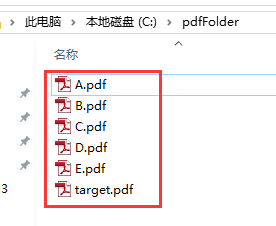
4.拆分pdf
方法代码:
public static void SpiltPdf(String sourcePdfPath, String splitPath, String splitFileName) throws Exception { int j = 1; String splitPdf = splitPath + File.separator + splitFileName + "_"; // Loading an existing PDF document File file = new File(sourcePdfPath); PDDocument document = PDDocument.load(file); // Instantiating Splitter class Splitter splitter = new Splitter(); splitter.setStartPage(1); splitter.setSplitAtPage(1); splitter.setEndPage(5); // splitting the pages of a PDF document List Pages = splitter.split(document); // Creating an iterator Iterator iterator = Pages.listIterator(); // Saving each page as an individual document while(iterator.hasNext()) { PDDocument pd = iterator.next(); String pdfName = splitPdf + j++ + ".pdf"; pd.save(pdfName); } document.close(); } 测试用例:
public static void main(String[] args) throws Exception { String sourcePdfPath = ("C:\\pdfFolder\\target.pdf"); String splitPath = ("C:\\pdfFolder"); String splitFileName = ("splitPDF"); spiltPdf(sourcePdfPath, splitPath, splitFileName);}
引用链接:
(17条消息) 使用Apache PDFBox实现拆分、合并PDF_似有风中泣的博客-CSDN博客
(17条消息) Java使用PDFBox操作PDF文件_pdfbox 打印 token_一个傻子程序媛的博客-CSDN博客
(17条消息) PDFbox基本操作_pdtype0font_静若繁花_jingjing的博客-CSDN博客
来源地址:https://blog.csdn.net/m0_58859785/article/details/129358045







