
本文小编为大家详细介绍“go zero微服务高在请求量下怎么优化”,内容详细,步骤清晰,细节处理妥当,希望这篇“go zero微服务高在请求量下怎么优化”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
本地缓存
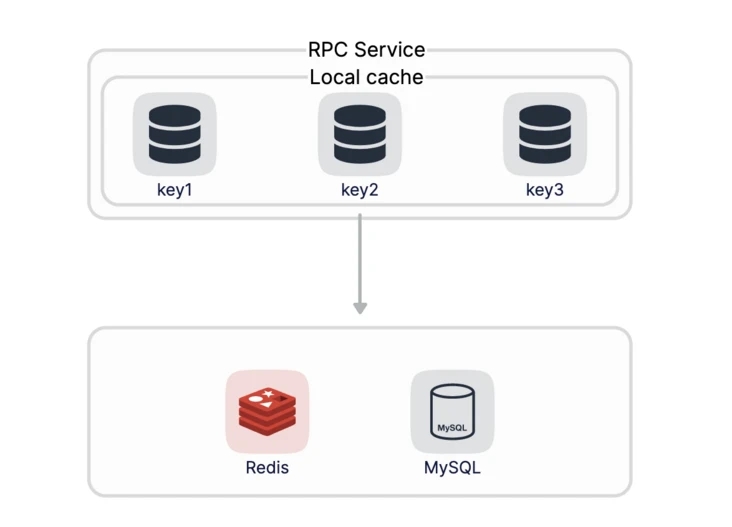
当我们遇到极端热点数据查询的时候,这个时候就要考虑本地缓存了。热点本地缓存主要部署在应用服务器的代码中,用于阻挡热点查询对于Redis等分布式缓存或者数据库的压力。
在我们的商城中,首页Banner中会放一些广告商品或者推荐商品,这些商品的信息由运营在管理后台录入和变更。这些商品的请求量非常大,即使是Redis也很难扛住,所以这里我们可以使用本地缓存来进行优化。
在product库中先建一张商品运营表product_operation,为了简化只保留必要字段,product_id为推广运营的商品id,status为运营商品的状态,status为1的时候会在首页Banner中展示该商品。
CREATE TABLE `product_operation` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT, `product_id` bigint unsigned NOT NULL DEFAULT 0 COMMENT '商品id', `status` int NOT NULL DEFAULT '1' COMMENT '运营商品状态 0-下线 1-上线', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `ix_update_time` (`update_time`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品运营表';本地缓存的实现比较简单,我们可以使用map来自己实现,在go-zero的collection中提供了Cache来实现本地缓存的功能,我们直接拿来用,重复造轮子从来不是一个明智的选择,localCacheExpire为本地缓存过期时间,Cache提供了Get和Set方法,使用非常简单
localCache, err := collection.NewCache(localCacheExpire)先从本地缓存中查找,如果命中缓存则直接返回。没有命中缓存的话需要先从数据库中查询运营位商品id,然后再聚合商品信息,最后回塞到本地缓存中。详细代码逻辑如下:
func (l *OperationProductsLogic) OperationProducts(in *product.OperationProductsRequest) (*product.OperationProductsResponse, error) { opProducts, ok := l.svcCtx.LocalCache.Get(operationProductsKey) if ok { return &product.OperationProductsResponse{Products: opProducts.([]*product.ProductItem)}, nil } pos, err := l.svcCtx.OperationModel.OperationProducts(l.ctx, validStatus) if err != nil { return nil, err } var pids []int64 for _, p := range pos { pids = append(pids, p.ProductId) } products, err := l.productListLogic.productsByIds(l.ctx, pids) if err != nil { return nil, err } var pItems []*product.ProductItem for _, p := range products { pItems = append(pItems, &product.ProductItem{ ProductId: p.Id, Name: p.Name, }) } l.svcCtx.LocalCache.Set(operationProductsKey, pItems) return &product.OperationProductsResponse{Products: pItems}, nil}使用grpurl调试工具请求接口,第一次请求cache miss后,后面的请求都会命中本地缓存,等到本地缓存过期后又会重新回源db加载数据到本地缓存中
~ grpcurl -plaintext -d '{}' 127.0.0.1:8081 product.Product.OperationProducts{ "products": [ { "productId": "32", "name": "电风扇6" }, { "productId": "31", "name": "电风扇5" }, { "productId": "33", "name": "电风扇7" } ]}注意,并不是所有信息都适用于本地缓存,本地缓存的特点是请求量超高,同时业务上能够允许一定的不一致,因为本地缓存一般不会主动做更新操作,需要等到过期后重新回源db后再更新。所以在业务中要视情况而定看是否需要使用本地缓存。
自动识别热点数据
首页Banner场景是由运营人员来配置的,也就是我们能提前知道可能产生的热点数据,但有些情况我们是不能提前预知数据会成为热点的。
所以就需要我们能自适应地自动的识别这些热点数据,然后把这些数据提升为本地缓存。
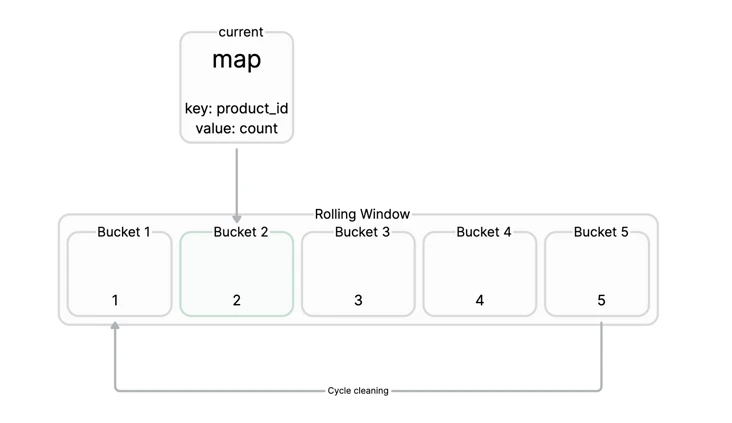
我们维护一个滑动窗口,比如滑动窗口设置为10s,就是要统计这10s内有哪些key被高频访问,一个滑动窗口中对应多个Bucket,每个Bucket中对应一个map,map的key为商品的id,value为商品对应的请求次数。
接着我们可以定时的(比如10s)去统计当前所有Buckets中的key的数据,然后把这些数据导入到大顶堆中,轻而易举的可以从大顶堆中获取topK的key,我们可以设置一个阈值,比如在一个滑动窗口时间内某一个key访问频次超过500次,就认为该key为热点key,从而自动地把该key升级为本地缓存。
缓存使用技巧
下面介绍一些缓存使用的小技巧
key的命名要尽量易读,即见名知意,在易读的前提下长度要尽可能的小,以减少资源的占用,对于value来说可以用int就尽量不要用string,对于小于N的value,redis内部有shared_object缓存。
在redis使用hash的情况下进行key的拆分,同一个hash key会落到同一个redis节点,hash过大的情况下会导致内存以及请求分布的不均匀,考虑对hash进行拆分为小的hash,使得节点内存均匀避免单节点请求热点。
为了避免不存在的数据请求,导致每次请求都缓存miss直接打到数据库中,进行空缓存的设置。
缓存中需要存对象的时候,序列化尽量使用protobuf,尽可能减少数据大小。
新增数据的时候要保证缓存务必存在的情况下再去操作新增,使用Expire来判断缓存是否存在。
对于存储每日登录场景的需求,可以使用BITSET,为了避免单个BITSET过大或者热点,可以进行sharding。
在使用sorted set的时候,避免使用zrange或者zrevrange返回过大的集合,复杂度较高。
在进行缓存操作的时候尽量使用PIPELINE,但也要注意避免集合过大。
避免超大的value。
缓存尽量要设置过期时间。
慎用全量操作命令,比如Hash类型的HGETALL、Set类型的SMEMBERS等,这些操作会对Hash和Set的底层数据结构进行全量扫描,如果数据量较多的话,会阻塞Redis主线程。
获取集合类型的全量数据可以使用SSCAN、HSCAN等命令分批返回集合中的数据,减少对主线程的阻塞。
慎用MONITOR命令,MONITOR命令会把监控到的内容持续写入输出缓冲区,如果线上命令操作很多,输出缓冲区很快就会溢出,会对Redis性能造成影响。
生产环境禁用KEYS、FLUSHALL、FLUSHDB等命令。
读到这里,这篇“go zero微服务高在请求量下怎么优化”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注编程网行业资讯频道。







