
目录
我们的MySQL数据库已经在linux系统中成功安装运行了,但如果要在windows系统上管理数据库,那么我们还需要学习navicat 这个管理数据库的工具。
navicat premium-15官方下载
https://www.navicat.com.cn/download/navicat-premium
选择合适的版本进行下载
详细的下载、安装可以参考以下文章
1、登录


2、连接数据库失败情况
这里可能会出现登录失败的情况,如果你是学习阶段,开的虚拟机和navicat跑在一台机器上,排除数据库没有开启成功、主机防火墙未设置策略或未关闭(错误码1130)等问题,可能存在的问题是windows主机没有开启telnet功能,需要做如下设置

create user 'wxg'@'localhost' identified by password '名文'; 用名文创建数据库新用户
select user from mysql.user\G 查看数据库用户

3、登录数据库需要授权
没有对数据库用户授权登录时会报错

对用户进行一个网段进行授权
grant all privileges on *.* to 'wxg'@'192.168.100.%' identified by '123456';
#将所有数据库的所有表(*.*)的所有权限(all privileges),授予通过 一个网段 ip(%)访问的用户,密码为123456,如果要限制所有机器可以访问,将网段换成相应的%即可
这样就可以成功登录
flush privileges; 刷新权限
#当然,给root用户设置任何host都可以登录明显是不安全的




1、数据库的基本操作
通过右键点击,我们可以创建、编辑、删除......数据库更改数据库和表的属性



和数据库表内容信息一样

2、对表进行操作
右键test库下的“表”,选择新建数据表,或右击一个已存在的表点击“设计表”,进入一个编辑表的窗口。在这里对表进行表结构的展示和编辑,可以插入字段并定义字段类型和长度,设置主键、设置默认值,是否为“null”等,相当于describe和alter操作。




在这个界面创建外键,我们先清空表内容(最好创建表的时候设置,否则会报错),所关联的主表的主键和foreign key需要在类型、长度上保持一致,同时外键不可以设置自增、无符号、填充零

3、sql 语句管理数据库
在navicat中,也可以点击新建查询,在命令行中输入SQL语句的方式管理数据库中的数据,并可以使用Tab键对命令进行补全

4、用户管理
点击用户进入用户的管理界面,在这里可以直观的看到当前数据库(非单个库)的所有用户,也可以对他们进行更改密码,新建、删除 ,权限设置,以及可登录的主机设置(文章开头的设置)。 
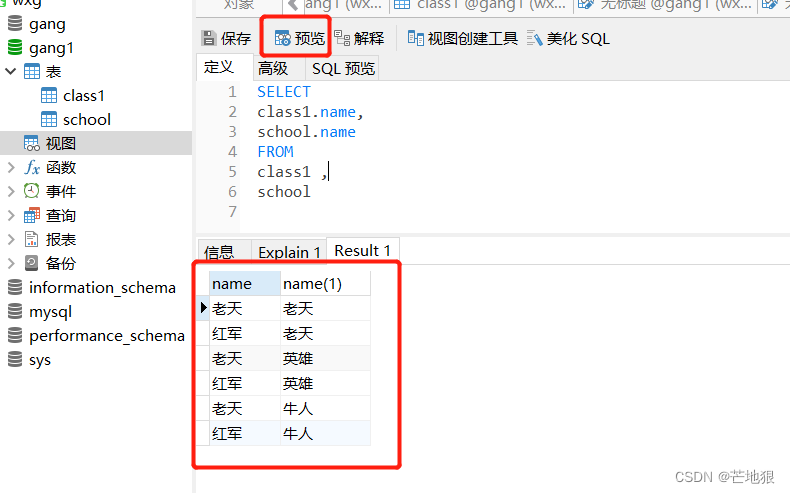
5、 视图的创建
创建一个表




6、表的导入与导出

导出 全部记录

选择格式




开始导出

在保存的excel表打开查看

7、数据库的备份
选择备份

新建备份

开始备份
8、还原备份

1、事务特性
日志文件(redo log 和 undo log)
锁技术
MVCC
事务ACID特性:
原子性:Atomicity当前事务的操作要么同时成功,要么同时失败。由undo log来保证
一致性:Consistency使用事务的最终目的,事务完成前、后,数据必须处于一致状态,由业务代码正确逻辑保证
隔离性:Isolation在事务并发执行时,他们内部的操作不能相互干扰
持久性:Durability一旦提交了事务,它对数据库的改变就应该是永久的。由redo log日志来保证
redo 日志
前面还提到了持久性是靠redo log来保证的,那么redo log是什么,为什么可以保证mysql里的数据不丢失的呢该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log),前者是在内存中,后者在磁盘中。
redo是innodb引擎特有的,记录了事务里对数据的修改,由于只记录了修改,大大减小的IO频率。一个事务会包含许多SQL,而一条SQL修改语句,会产生很多组redo,而这一组(学名:Mini-Transaction)才是写入的最小单元。mysql 为了提升性能不会把每次的修改都实时同步到磁盘,而是会先存到Boffer Pool(缓冲池)里头,把这个当作缓存来用。然后使用后台线程去做缓冲池和磁盘之间的同步。那么问题来了,如果还没来的及同步的时候宕机或断电了怎么办?这样会导致丢部分已提交事务的修改信息!所以就引入了redo log来记录已成功提交事务的修改信息,并且会把redo log持久化到磁盘,系统重启之后再读取redo log恢复最新数据。
2、测试提交事务
InnoDB四种隔离级别:read uncommit(有脏读问题)、read commit(有不可重复读问题)、repeatable read(有幻读问题)、serializable(解决前三种问题,但效率过低)丢失更新
read uncommit(有脏读问题)
两个事务同时对同一个数据进行只读不提交操作,一个进行修改,一个来进行读取数据。

read committed(oracle默认隔离级别)
SELECT * FROM `class1`
begin;
UPDATE class1 set name='国人' where age=24;
SELECT * from class1;
commit; 提交事务

3、测试回滚事务

回滚操作
4、多个回滚点测试

MVCC(Multi-Version Concurrency Control)即多版本并发控制。是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。
在 MySQL InnoDB 中主要是为了提高数据库并发性能,用更好的方式去处理读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读
1、什么是当前读和快照读?
(1)、当前读(悲观锁的具体实现)
(select。。。lock in mode)共享锁和(select。。。for update/insert/delete)排他锁这些操作都属于当前读,他们读取的都是记录的最新版本,并且读取时还需要保证其他事务不能修改其正在读取的当前记录。
(2)、快照读(MVCC非阻塞的具体实现)
像不加锁的 select 操作就是快照读,即不加锁的非阻塞读;快照读的前提是隔离级别不是串行级别,串行级别下的快照读会退化成当前读;之所以出现快照读的情况,是基于提高并发性能的考虑,快照读的实现是基于MVCC ,可以认为 MVCC 是行锁的一个变种,但它在很多情况下,避免了加锁操作,降低了开销;既然是基于多版本,即快照读可能读到的并不一定是数据的最新版本,而有可能是之前的历史版本
2、MVCC的原理
从navicat事务的隔离级别可以发现,数据库有三种并发的场景:(读while读)(读while写)(写while写),当然,(读while读)没有什么问题,但后两者存在着冲突
隐式字段
每行记录除了我们自定义的字段外,还有数据库隐式定义的 DB_TRX_ID;DB_ROLL_PTR等字段
DB_TRX_ID
6 byte,最近修改事务 ID:记录最后一次修改该记录的事务 ID
DB_ROLL_PTR
7 byte,回滚指针,指向这条记录的上一个版本的位置(存储于 rollback segment 里)
DB_ROW_ID
6 byte,隐含的自增 ID(隐藏主键),如果数据表没有主键,InnoDB 会自动以DB_ROW_ID产生一个聚簇索引
还有一个删除 flag 隐藏字段, 既记录被更新或删除并不代表真的删除,而是删除 flag 变了
undo日志
insert undo log(事务在 insert 新记录时产生)只在rollback时需要,在事务提交后可以被立即丢弃
update undo log(事务在进行 update 或 delete 时产生)提交后直到没有事务涉及后,由purge线程统一清除
*purge:更新或者删除操作都只是设置一下老记录的 deleted_bit ,并不真正将过时的记录删除。为了节省磁盘空间,InnoDB 有专门的 purge 线程来清理 deleted_bit 为 true 的记录。为了不影响 MVCC 的正常工作,purge 线程自己也维护了一个read view(这个 read view 相当于系统中最老活跃事务的 read view );如果某个记录的 deleted_bit 为 true ,并且 DB_TRX_ID 相对于 purge 线程的 read view 可见,那么这条记录是可以被安全清除的。
不同事务或者相同事务的对同一记录的修改,会导致该记录的undo log成为一条记录版本线性表,既链表,undo log 的链首就是最新的旧记录,链尾就是最早的旧记录
两者中,insert undo log 实际上就是rollback segment中的旧纪录链,上文中navicat上我们进行的read uncommitted级别的事务在对数据进行修改时,数据库先为该行加锁(排它锁),把修改之前的该行数据拷贝到undo log中作为旧纪录,此时被修改的记录的DB_TRX_ID就会变为做此修改的事务的ID,我们默认从1开始,之后递增,而DB_ROLL_PTR则指向undo log中的副本数据(SQL语句:delete。。。),事务提交后,释放锁。
而update undo log的实现原理是,当进行数据修改的操作时,会有一个叫做COW(copy on write)的机制,还是字面意思,复制写,它的存在是为了解决一个读写并发的问题,为了让读写可以互不干扰,例如在进行update操作时,会先把要操作的行复制出一份,在复制出的行上进行数据修改,复制出的这行数据的事务id会发生更改,而回滚指针则指向了update undo log(被复制的数据),也就是进行update操作的原数据,解决了读写并发的问题同时带来了数据读取的延后性问题
Read View
三个主要属性:
trx_list (随便取的名字) 开启read view时当前活跃的(未提交)事务id集合
up_limit_id 开启read view时最小的事务id
low_limit_id 开启read view后,应该分配给下一个事务的id值,也即当前最大事务id+1
事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的 ID (当每个事务开启时,都会被分配一个 ID , 这个 ID 是递增的,所以最新的事务,ID 值越大,反之越小);主要是用来做可见性判断的, 即当我们某个事务执行快照读的时候,对该记录创建一个 Read View 读视图,通过一定条件判断当前事务能够看到哪个版本的数据,既可能是当前最新的数据,也有可能是该行记录的undo log里面的某个版本的数据
read view遵循一个可见性算法来进行判断,将要被修改的数据的最新记录中的 DB_TRX_ID(当前事务 ID )取出来,与系统当前其他活跃事务的 ID 去对比(由 Read View 维护),如果事务id 跟 Read View 的属性做了某些比较,不符合可见性,那就通过 DB_ROLL_PTR 回滚指针去取出 Undo Log 中的 DB_TRX_ID 再比较,即遍历链表的 DB_TRX_ID(从链首到链尾,即从最近的一次修改查起),直到找到满足特定条件的 DB_TRX_ID , 那么这个 DB_TRX_ID 所在的旧记录就是当前事务可见的最新老版本。
基于RR隔离级别:RW一旦创建则不可变,可以理解为一个快照,即使其中某个事务提交了(RW开启后),也不会影响当前RTX_list中的事务ID
DB_TRX_ID < up_limit_id , 当前行事务id比活跃的最小事务id还小时,当前事务对该记录的修改已经提交,因为当前事务id比活跃的最小事务id还小,不在活跃的事务之中,也就意味着该事务已经提交或回滚。也就是在生成Read View之前,事务已经提交,则这个数据是可读的;
DB_TRX_ID > low_limit_id , 修改该行的事务id大于了Read View里系统待分配的下一个事务id,说明修改该行的事务是生成该Read View之后出现的事务,这时,应该是不可见的,一个事务不可以看到未提交事务所作的数据修改(脏读)。
DB_TRX_ID 在 up_limit_id 和 low_limit_id 的范围内,分为两种情况:
(1)包含在 trx_list 中表示在开启这个read view时,该事务还是活跃的(未提交),应该不可见,否则就是脏读
(2)不包含在 trx_list 中表示在开启这个read view时,该事务已经提交了,所以可见
基于RC隔离级别:与RR相比,RC的特点是不可重复读,也就是每一次读取的都是当前最新的数据,那么RC每一次进行读取的时候会开启一个新的RW,这样就可以保证,在每次读取数据的时候,TRX_list里都是当前最新的活跃事务
来源地址:https://blog.csdn.net/m0_71521555/article/details/126982149










