
目录
前言
要想看懂instant-ngp的cuda代码,需要先对NeRF系列有足够深入的了解,原始的NeRF版本是基于tensorflow的,今天读的是MIT博士生Yen-Chen Lin实现的pytorch版本的代码。
代码链接:https://github.com/yenchenlin/nerf-pytorch
因为代码量比较大,所以我们先使用一个思维导图对项目逻辑进行梳理,然后逐个文件解析。为了保持思路连贯,我们会一次贴上整个函数的内容并逐行注释,然后贴相关的公式和示意图到代码段的下方。

run_nerf.py
一切都从这个文件开始,让我们先来看看有哪些参数需要设置。
config_parser()
先是一些基本参数
# 生成config.txt文件 parser.add_argument('--config', is_config_file=True, help='config file path') # 指定实验名称 parser.add_argument("--expname", type=str, help='experiment name') # 指定输出目录 parser.add_argument("--basedir", type=str, default='./logs/', help='where to store ckpts and logs') # 指定数据目录 parser.add_argument("--datadir", type=str, default='./data/llff/fern', help='input data directory')然后是一些训练相关的参数
# training options # 设置网络的深度,即网络的层数 parser.add_argument("--netdepth", type=int, default=8, help='layers in network') # 设置网络的宽度,即每一层神经元的个数 parser.add_argument("--netwidth", type=int, default=256, help='channels per layer') parser.add_argument("--netdepth_fine", type=int, default=8, help='layers in fine network') parser.add_argument("--netwidth_fine", type=int, default=256, help='channels per layer in fine network') # batch size,光束的数量 parser.add_argument("--N_rand", type=int, default=32*32*4, help='batch size (number of random rays per gradient step)') # 学习率 parser.add_argument("--lrate", type=float, default=5e-4, help='learning rate') # 指数学习率衰减 parser.add_argument("--lrate_decay", type=int, default=250, help='exponential learning rate decay (in 1000 steps)') # 并行处理的光线数量,如果溢出则减少 parser.add_argument("--chunk", type=int, default=1024*32, help='number of rays processed in parallel, decrease if running out of memory') # 并行发送的点数 parser.add_argument("--netchunk", type=int, default=1024*64, help='number of pts sent through network in parallel, decrease if running out of memory') # 一次只能从一张图片中获取随机光线 parser.add_argument("--no_batching", action='store_true', help='only take random rays from 1 image at a time') # 不要从保存的模型中加载权重 parser.add_argument("--no_reload", action='store_true', help='do not reload weights from saved ckpt') # 为粗网络重新加载特定权重 parser.add_argument("--ft_path", type=str, default=None, help='specific weights npy file to reload for coarse network')然后是一些渲染时的参数
# rendering options # 每条射线的粗样本数 parser.add_argument("--N_samples", type=int, default=64, help='number of coarse samples per ray') # 每条射线附加的细样本数 parser.add_argument("--N_importance", type=int, default=0, help='number of additional fine samples per ray') # 抖动 parser.add_argument("--perturb", type=float, default=1., help='set to 0. for no jitter, 1. for jitter') parser.add_argument("--use_viewdirs", action='store_true', help='use full 5D input instead of 3D') # 默认位置编码 parser.add_argument("--i_embed", type=int, default=0, help='set 0 for default positional encoding, -1 for none') # 多分辨率 parser.add_argument("--multires", type=int, default=10, help='log2 of max freq for positional encoding (3D location)') # 2D方向的多分辨率 parser.add_argument("--multires_views", type=int, default=4, help='log2 of max freq for positional encoding (2D direction)') # 噪音方差 parser.add_argument("--raw_noise_std", type=float, default=0., help='std dev of noise added to regularize sigma_a output, 1e0 recommended') # 不要优化,重新加载权重和渲染render_poses路径 parser.add_argument("--render_only", action='store_true', help='do not optimize, reload weights and render out render_poses path') # 渲染测试集而不是render_poses路径 parser.add_argument("--render_test", action='store_true', help='render the test set instead of render_poses path') # 下采样因子以加快渲染速度,设置为 4 或 8 用于快速预览 parser.add_argument("--render_factor", type=int, default=0, help='downsampling factor to speed up rendering, set 4 or 8 for fast preview')还有一些参数
# training options parser.add_argument("--precrop_iters", type=int, default=0, help='number of steps to train on central crops') parser.add_argument("--precrop_frac", type=float, default=.5, help='fraction of img taken for central crops') # dataset options parser.add_argument("--dataset_type", type=str, default='llff', help='options: llff / blender / deepvoxels') # # 将从测试/验证集中加载 1/N 图像,这对于像 deepvoxels 这样的大型数据集很有用 parser.add_argument("--testskip", type=int, default=8, help='will load 1/N images from test/val sets, useful for large datasets like deepvoxels') ## deepvoxels flags parser.add_argument("--shape", type=str, default='greek', help='options : armchair / cube / greek / vase') ## blender flags parser.add_argument("--white_bkgd", action='store_true', help='set to render synthetic data on a white bkgd (always use for dvoxels)') parser.add_argument("--half_res", action='store_true', help='load blender synthetic data at 400x400 instead of 800x800') ## llff flags # LLFF下采样因子 parser.add_argument("--factor", type=int, default=8, help='downsample factor for LLFF images') parser.add_argument("--no_ndc", action='store_true', help='do not use normalized device coordinates (set for non-forward facing scenes)') parser.add_argument("--lindisp", action='store_true', help='sampling linearly in disparity rather than depth') parser.add_argument("--spherify", action='store_true', help='set for spherical 360 scenes') parser.add_argument("--llffhold", type=int, default=8, help='will take every 1/N images as LLFF test set, paper uses 8') # logging/saving options parser.add_argument("--i_print", type=int, default=100, help='frequency of console printout and metric loggin') parser.add_argument("--i_img", type=int, default=500, help='frequency of tensorboard image logging') parser.add_argument("--i_weights", type=int, default=10000, help='frequency of weight ckpt saving') parser.add_argument("--i_testset", type=int, default=50000, help='frequency of testset saving') parser.add_argument("--i_video", type=int, default=50000, help='frequency of render_poses video saving')train()
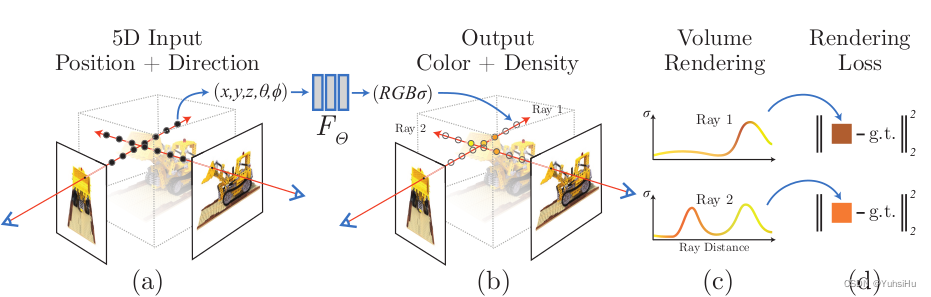
训练过程的控制。开始训练,先把5D输入进行编码,然后交给MLP得到4D的数据(颜色和体素的密度),然后进行体渲染得到图片,再和真值计算L2 loss。
def train(): parser = config_parser() args = parser.parse_args() # Load data K = None if args.dataset_type == 'llff': # shape: images[20,378,504,3] poses[20,3,5] render_poses[120,3,5] images, poses, bds, render_poses, i_test = load_llff_data(args.datadir, args.factor, recenter=True, bd_factor=.75, spherify=args.spherify) # hwf=[378,504,focal] poses每个batch的每一行最后一个元素拿出来 hwf = poses[0,:3,-1] # shape: poses [20,3,4] hwf给出去之后把每一行的第5个元素删掉 poses = poses[:,:3,:4] print('Loaded llff', images.shape, render_poses.shape, hwf, args.datadir) if not isinstance(i_test, list): i_test = [i_test] if args.llffhold > 0: print('Auto LLFF holdout,', args.llffhold) i_test = np.arange(images.shape[0])[::args.llffhold] # 验证集和测试集相同 i_val = i_test # 剩下的部分当作训练集 i_train = np.array([i for i in np.arange(int(images.shape[0])) if (i not in i_test and i not in i_val)]) print('DEFINING BOUNDS') # 定义边界值 if args.no_ndc: near = np.ndarray.min(bds) * .9 far = np.ndarray.max(bds) * 1. else: # 没说就是0-1 near = 0. far = 1. print('NEAR FAR', near, far) elif args.dataset_type == 'blender': images, poses, render_poses, hwf, i_split = load_blender_data(args.datadir, args.half_res, args.testskip) print('Loaded blender', images.shape, render_poses.shape, hwf, args.datadir) i_train, i_val, i_test = i_split near = 2. far = 6. if args.white_bkgd: images = images[...,:3]*images[...,-1:] + (1.-images[...,-1:]) else: images = images[...,:3] elif args.dataset_type == 'LINEMOD': images, poses, render_poses, hwf, K, i_split, near, far = load_LINEMOD_data(args.datadir, args.half_res, args.testskip) print(f'Loaded LINEMOD, images shape: {images.shape}, hwf: {hwf}, K: {K}') print(f'[CHECK HERE] near: {near}, far: {far}.') i_train, i_val, i_test = i_split if args.white_bkgd: images = images[...,:3]*images[...,-1:] + (1.-images[...,-1:]) else: images = images[...,:3] elif args.dataset_type == 'deepvoxels': images, poses, render_poses, hwf, i_split = load_dv_data(scene=args.shape, basedir=args.datadir, testskip=args.testskip) print('Loaded deepvoxels', images.shape, render_poses.shape, hwf, args.datadir) i_train, i_val, i_test = i_split hemi_R = np.mean(np.linalg.norm(poses[:,:3,-1], axis=-1)) near = hemi_R-1. far = hemi_R+1. else: print('Unknown dataset type', args.dataset_type, 'exiting') return # Cast intrinsics to right types H, W, focal = hwf H, W = int(H), int(W) hwf = [H, W, focal] if K is None: K = np.array([ [focal, 0, 0.5*W], [0, focal, 0.5*H], [0, 0, 1] ]) if args.render_test: render_poses = np.array(poses[i_test]) # Create log dir and copy the config file basedir = args.basedir expname = args.expname os.makedirs(os.path.join(basedir, expname), exist_ok=True) f = os.path.join(basedir, expname, 'args.txt') with open(f, 'w') as file: # 把参数统一放到./logs/expname/args.txt for arg in sorted(vars(args)): attr = getattr(args, arg) file.write('{} = {}\n'.format(arg, attr)) if args.config is not None: f = os.path.join(basedir, expname, 'config.txt') with open(f, 'w') as file: file.write(open(args.config, 'r').read()) # Create nerf model # 创建模型 render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer = create_nerf(args) global_step = start bds_dict = { 'near' : near, 'far' : far, } # 本来都是dict类型,都有9个元素,加了bds之后就是11个元素了 render_kwargs_train.update(bds_dict) render_kwargs_test.update(bds_dict) # Move testing data to GPU render_poses = torch.Tensor(render_poses).to(device) # Short circuit if only rendering out from trained model # 只渲染并生成视频 if args.render_only: print('RENDER ONLY') with torch.no_grad(): if args.render_test: # render_test switches to test poses images = images[i_test] else: # Default is smoother render_poses path images = None testsavedir = os.path.join(basedir, expname, 'renderonly_{}_{:06d}'.format('test' if args.render_test else 'path', start)) os.makedirs(testsavedir, exist_ok=True) print('test poses shape', render_poses.shape) rgbs, _ = render_path(render_poses, hwf, K, args.chunk, render_kwargs_test, gt_imgs=images, savedir=testsavedir, render_factor=args.render_factor) print('Done rendering', testsavedir) imageio.mimwrite(os.path.join(testsavedir, 'video.mp4'), to8b(rgbs), fps=30, quality=8) return # Prepare raybatch tensor if batching random rays N_rand = args.N_rand # 4096 use_batching = not args.no_batching if use_batching: # For random ray batching print('get rays') # 获取光束, rays shape:[20,2,378,504,3] rays = np.stack([get_rays_np(H, W, K, p) for p in poses[:,:3,:4]], 0) # [N, ro+rd, H, W, 3] print('done, concats') # 沿axis=1拼接,rayss_rgb shape:[20,3,378,504,3] rays_rgb = np.concatenate([rays, images[:,None]], 1) # [N, ro+rd+rgb, H, W, 3] # 改变shape,rays_rgb shape:[20,378,504,3,3] rays_rgb = np.transpose(rays_rgb, [0,2,3,1,4]) # [N, H, W, ro+rd+rgb, 3] # rays_rgb shape:[N-测试样本数目=17,378,504,3,3] rays_rgb = np.stack([rays_rgb[i] for i in i_train], 0) # train images only # 得到了(N-测试样本数目)*H*W个光束,rays_rgb shape:[(N-test)*H*W,3,3] rays_rgb = np.reshape(rays_rgb, [-1,3,3]) # [(N-test)*H*W, ro+rd+rgb, 3] rays_rgb = rays_rgb.astype(np.float32) print('shuffle rays') # 打乱这个光束的顺序 np.random.shuffle(rays_rgb) print('done') i_batch = 0 # Move training data to GPU if use_batching: images = torch.Tensor(images).to(device) poses = torch.Tensor(poses).to(device) if use_batching: rays_rgb = torch.Tensor(rays_rgb).to(device) N_iters = 200000 + 1 print('Begin') print('TRAIN views are', i_train) print('TEST views are', i_test) print('VAL views are', i_val) # Summary writers # writer = SummaryWriter(os.path.join(basedir, 'summaries', expname)) # 默认训练200000次 start = start + 1 for i in trange(start, N_iters): time0 = time.time() # Sample random ray batch if use_batching: # Random over all images # 取一个batch, batch shape:[4096,3,3] batch = rays_rgb[i_batch:i_batch+N_rand] # [B, 2+1, 3*?] # 转换0维和1维的位置[ro+rd+rgb,4096,3] batch = torch.transpose(batch, 0, 1) # shape: batch_rays shape[ro+rd,4096,3] target_s[4096,3]对应的是rgb batch_rays, target_s = batch[:2], batch[2] i_batch += N_rand # 如果所有样本都遍历过了则打乱数据 if i_batch >= rays_rgb.shape[0]: print("Shuffle data after an epoch!") rand_idx = torch.randperm(rays_rgb.shape[0]) rays_rgb = rays_rgb[rand_idx] i_batch = 0 else: # Random from one image img_i = np.random.choice(i_train) target = images[img_i] target = torch.Tensor(target).to(device) pose = poses[img_i, :3,:4] if N_rand is not None: rays_o, rays_d = get_rays(H, W, K, torch.Tensor(pose)) # (H, W, 3), (H, W, 3) if i < args.precrop_iters: dH = int(H//2 * args.precrop_frac) dW = int(W//2 * args.precrop_frac) coords = torch.stack( torch.meshgrid(torch.linspace(H//2 - dH, H//2 + dH - 1, 2*dH), torch.linspace(W//2 - dW, W//2 + dW - 1, 2*dW) ), -1) if i == start: print(f"[Config] Center cropping of size {2*dH} x {2*dW} is enabled until iter {args.precrop_iters}") else: coords = torch.stack(torch.meshgrid(torch.linspace(0, H-1, H), torch.linspace(0, W-1, W)), -1) # (H, W, 2) coords = torch.reshape(coords, [-1,2]) # (H * W, 2) select_inds = np.random.choice(coords.shape[0], size=[N_rand], replace=False) # (N_rand,) select_coords = coords[select_inds].long() # (N_rand, 2) rays_o = rays_o[select_coords[:, 0], select_coords[:, 1]] # (N_rand, 3) rays_d = rays_d[select_coords[:, 0], select_coords[:, 1]] # (N_rand, 3) batch_rays = torch.stack([rays_o, rays_d], 0) target_s = target[select_coords[:, 0], select_coords[:, 1]] # (N_rand, 3) ##### Core optimization loop ##### # chunk=4096,batch_rays[2,4096,3] # 返回渲染出的一个batch的rgb,disp(视差图),acc(不透明度)和extras(其他信息) # rgb shape [4096, 3]刚好可以和target_s 对应上 # disp shape 4096,对应4096个光束 # acc shape 4096, 对应4096个光束 # extras 是一个dict,含有5个元素 shape:[4096,64,4] rgb, disp, acc, extras = render(H, W, K, chunk=args.chunk, rays=batch_rays, verbose=i < 10, retraw=True, **render_kwargs_train) optimizer.zero_grad() # 求RGB的MSE img_loss shape:[20,378,504,3] img_loss = img2mse(rgb, target_s) # trans shape:[4096,64] trans = extras['raw'][...,-1] loss = img_loss # 计算PSNR shape:[1] psnr = mse2psnr(img_loss) # 在extra里面的一个元素,求损失并加到整体损失上 if 'rgb0' in extras: img_loss0 = img2mse(extras['rgb0'], target_s) loss = loss + img_loss0 psnr0 = mse2psnr(img_loss0) loss.backward() optimizer.step() # NOTE: IMPORTANT! ### update learning rate ### decay_rate = 0.1 decay_steps = args.lrate_decay * 1000 new_lrate = args.lrate * (decay_rate ** (global_step / decay_steps)) for param_group in optimizer.param_groups: param_group['lr'] = new_lrate ################################ dt = time.time()-time0 # print(f"Step: {global_step}, Loss: {loss}, Time: {dt}") ##### end ##### # Rest is logging # 保存ckpt if i%args.i_weights==0: path = os.path.join(basedir, expname, '{:06d}.tar'.format(i)) torch.save({ 'global_step': global_step, 'network_fn_state_dict': render_kwargs_train['network_fn'].state_dict(), 'network_fine_state_dict': render_kwargs_train['network_fine'].state_dict(), 'optimizer_state_dict': optimizer.state_dict(), }, path) print('Saved checkpoints at', path) # 输出mp4视频 if i%args.i_video==0 and i > 0: # Turn on testing mode # reder_poses用来合成视频 with torch.no_grad(): rgbs, disps = render_path(render_poses, hwf, K, args.chunk, render_kwargs_test) print('Done, saving', rgbs.shape, disps.shape) moviebase = os.path.join(basedir, expname, '{}_spiral_{:06d}_'.format(expname, i)) imageio.mimwrite(moviebase + 'rgb.mp4', to8b(rgbs), fps=30, quality=8) imageio.mimwrite(moviebase + 'disp.mp4', to8b(disps / np.max(disps)), fps=30, quality=8) # if args.use_viewdirs: # render_kwargs_test['c2w_staticcam'] = render_poses[0][:3,:4] # with torch.no_grad(): # rgbs_still, _ = render_path(render_poses, hwf, args.chunk, render_kwargs_test) # render_kwargs_test['c2w_staticcam'] = None # imageio.mimwrite(moviebase + 'rgb_still.mp4', to8b(rgbs_still), fps=30, quality=8) # 保存测试数据集 if i%args.i_testset==0 and i > 0: testsavedir = os.path.join(basedir, expname, 'testset_{:06d}'.format(i)) os.makedirs(testsavedir, exist_ok=True) print('test poses shape', poses[i_test].shape) with torch.no_grad(): render_path(torch.Tensor(poses[i_test]).to(device), hwf, K, args.chunk, render_kwargs_test, gt_imgs=images[i_test], savedir=testsavedir) print('Saved test set') if i%args.i_print==0: tqdm.write(f"[TRAIN] Iter: {i} Loss: {loss.item()} PSNR: {psnr.item()}") """ print(expname, i, psnr.numpy(), loss.numpy(), global_step.numpy()) print('iter time {:.05f}'.format(dt)) with tf.contrib.summary.record_summaries_every_n_global_steps(args.i_print): tf.contrib.summary.scalar('loss', loss) tf.contrib.summary.scalar('psnr', psnr) tf.contrib.summary.histogram('tran', trans) if args.N_importance > 0: tf.contrib.summary.scalar('psnr0', psnr0) if i%args.i_img==0: # Log a rendered validation view to Tensorboard img_i=np.random.choice(i_val) target = images[img_i] pose = poses[img_i, :3,:4] with torch.no_grad(): rgb, disp, acc, extras = render(H, W, focal, chunk=args.chunk, c2w=pose,**render_kwargs_test) psnr = mse2psnr(img2mse(rgb, target)) with tf.contrib.summary.record_summaries_every_n_global_steps(args.i_img): tf.contrib.summary.image('rgb', to8b(rgb)[tf.newaxis]) tf.contrib.summary.image('disp', disp[tf.newaxis,...,tf.newaxis]) tf.contrib.summary.image('acc', acc[tf.newaxis,...,tf.newaxis]) tf.contrib.summary.scalar('psnr_holdout', psnr) tf.contrib.summary.image('rgb_holdout', target[tf.newaxis]) if args.N_importance > 0: with tf.contrib.summary.record_summaries_every_n_global_steps(args.i_img): tf.contrib.summary.image('rgb0', to8b(extras['rgb0'])[tf.newaxis]) tf.contrib.summary.image('disp0', extras['disp0'][tf.newaxis,...,tf.newaxis]) tf.contrib.summary.image('z_std', extras['z_std'][tf.newaxis,...,tf.newaxis]) """ global_step += 1梳理完train,我们来重点看一下train当中调用过的几个函数
create_nerf()
先调用get_embedder获得一个对应的embedding函数,然后构建NeRF模型
def create_nerf(args): """Instantiate NeRF's MLP model. """ embed_fn, input_ch = get_embedder(args.multires, args.i_embed) input_ch_views = 0 embeddirs_fn = None if args.use_viewdirs: embeddirs_fn, input_ch_views = get_embedder(args.multires_views, args.i_embed) output_ch = 5 if args.N_importance > 0 else 4 skips = [4] # 构建模型 model = NeRF(D=args.netdepth, W=args.netwidth, input_ch=input_ch, output_ch=output_ch, skips=skips, input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device) # 梯度 grad_vars = list(model.parameters()) model_fine = None if args.N_importance > 0: # 需要精细网络 model_fine = NeRF(D=args.netdepth_fine, W=args.netwidth_fine, input_ch=input_ch, output_ch=output_ch, skips=skips, input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device) grad_vars += list(model_fine.parameters()) network_query_fn = lambda inputs, viewdirs, network_fn : run_network(inputs, viewdirs, network_fn, embed_fn=embed_fn, embeddirs_fn=embeddirs_fn, netchunk=args.netchunk) # Create optimizer optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999)) start = 0 basedir = args.basedir expname = args.expname ########################## # Load checkpoints if args.ft_path is not None and args.ft_path!='None': ckpts = [args.ft_path] else: ckpts = [os.path.join(basedir, expname, f) for f in sorted(os.listdir(os.path.join(basedir, expname))) if 'tar' in f] print('Found ckpts', ckpts) if len(ckpts) > 0 and not args.no_reload: ckpt_path = ckpts[-1] print('Reloading from', ckpt_path) ckpt = torch.load(ckpt_path) start = ckpt['global_step'] optimizer.load_state_dict(ckpt['optimizer_state_dict']) # Load model model.load_state_dict(ckpt['network_fn_state_dict']) if model_fine is not None: model_fine.load_state_dict(ckpt['network_fine_state_dict']) ########################## # 加载模型 render_kwargs_train = { 'network_query_fn' : network_query_fn, 'perturb' : args.perturb, 'N_importance' : args.N_importance, 'network_fine' : model_fine, 'N_samples' : args.N_samples, 'network_fn' : model, 'use_viewdirs' : args.use_viewdirs, 'white_bkgd' : args.white_bkgd, 'raw_noise_std' : args.raw_noise_std, } # NDC only good for LLFF-style forward facing data if args.dataset_type != 'llff' or args.no_ndc: print('Not ndc!') render_kwargs_train['ndc'] = False render_kwargs_train['lindisp'] = args.lindisp render_kwargs_test = {k : render_kwargs_train[k] for k in render_kwargs_train} render_kwargs_test['perturb'] = False render_kwargs_test['raw_noise_std'] = 0. return render_kwargs_train, render_kwargs_test, start, grad_vars, optimizerrender()
接下来我们看一下如何渲染,render函数返回的是光束对应的rgb图、视差图、不透明度,以及raw
def render(H, W, K, chunk=1024*32, rays=None, c2w=None, ndc=True, near=0., far=1., use_viewdirs=False, c2w_staticcam=None, **kwargs): """Render rays Args: H: int. Height of image in pixels. W: int. Width of image in pixels. focal: float. Focal length of pinhole camera. chunk: int. Maximum number of rays to process simultaneously. Used to control maximum memory usage. Does not affect final results. rays: array of shape [2, batch_size, 3]. Ray origin and direction for each example in batch. c2w: array of shape [3, 4]. Camera-to-world transformation matrix. ndc: bool. If True, represent ray origin, direction in NDC coordinates. near: float or array of shape [batch_size]. Nearest distance for a ray. far: float or array of shape [batch_size]. Farthest distance for a ray. use_viewdirs: bool. If True, use viewing direction of a point in space in model. c2w_staticcam: array of shape [3, 4]. If not None, use this transformation matrix for camera while using other c2w argument for viewing directions. Returns: rgb_map: [batch_size, 3]. Predicted RGB values for rays. disp_map: [batch_size]. Disparity map. Inverse of depth. acc_map: [batch_size]. Accumulated opacity (alpha) along a ray. extras: dict with everything returned by render_rays(). """ if c2w is not None: # c2w是相机到世界的坐标变换矩阵 # special case to render full image rays_o, rays_d = get_rays(H, W, K, c2w) else: # use provided ray batch # shape: rays[2,4096,3] rays_o[4096,3] rays_d[4096,3] rays_o, rays_d = rays if use_viewdirs: # provide ray directions as input viewdirs = rays_d if c2w_staticcam is not None: # special case to visualize effect of viewdirs rays_o, rays_d = get_rays(H, W, K, c2w_staticcam) viewdirs = viewdirs / torch.norm(viewdirs, dim=-1, keepdim=True) viewdirs = torch.reshape(viewdirs, [-1,3]).float() # sh[4096,3] sh = rays_d.shape # [..., 3] if ndc: # for forward facing scenes rays_o, rays_d = ndc_rays(H, W, K[0][0], 1., rays_o, rays_d) # Create ray batch rays_o = torch.reshape(rays_o, [-1,3]).float() rays_d = torch.reshape(rays_d, [-1,3]).float() # shape: near[4096,1] far[4096,1] 全0或全1 near, far = near * torch.ones_like(rays_d[...,:1]), far * torch.ones_like(rays_d[...,:1]) # shape:[4096,3+3+1+1=8] rays = torch.cat([rays_o, rays_d, near, far], -1) if use_viewdirs: rays = torch.cat([rays, viewdirs], -1) # Render and reshape # chunk默认值是1024*32=32768 all_ret = batchify_rays(rays, chunk, **kwargs) for k in all_ret: k_sh = list(sh[:-1]) + list(all_ret[k].shape[1:]) all_ret[k] = torch.reshape(all_ret[k], k_sh) # raw和另外三个分开 k_extract = ['rgb_map', 'disp_map', 'acc_map'] ret_list = [all_ret[k] for k in k_extract] ret_dict = {k : all_ret[k] for k in all_ret if k not in k_extract} return ret_list + [ret_dict]batchify_rays()
将光束作为一个batch,chunk是并行处理的光束数量,ret是一个chunk(1024×32=32768)的结果,all_ret是一个batch的结果
def batchify_rays(rays_flat, chunk=1024*32, **kwargs): """Render rays in smaller minibatches to avoid OOM. """ all_ret = {} # shape: rays_flat[4096,8] for i in range(0, rays_flat.shape[0], chunk): # ret是一个字典,shape:rgb_map[4096,3] disp_map[4096] acc_map[4096] raw[4096,64,4] ret = render_rays(rays_flat[i:i+chunk], **kwargs) # 每一个key对应一个list,list包含了所有的ret对应key的value for k in ret: if k not in all_ret: all_ret[k] = [] all_ret[k].append(ret[k]) all_ret = {k : torch.cat(all_ret[k], 0) for k in all_ret} return all_retrender_rays()
def render_rays(ray_batch, network_fn, network_query_fn, N_samples, retraw=False, lindisp=False, perturb=0., N_importance=0, network_fine=None, white_bkgd=False, raw_noise_std=0., verbose=False, pytest=False): """Volumetric rendering. Args: ray_batch: array of shape [batch_size, ...]. All information necessary for sampling along a ray, including: ray origin, ray direction, min dist, max dist, and unit-magnitude viewing direction. network_fn: function. Model for predicting RGB and density at each point in space. 用于预测每个点的 RGB 和密度的模型 network_query_fn: function used for passing queries to network_fn. N_samples: int. Number of different times to sample along each ray.每条射线上的采样次数 retraw: bool. If True, include model's raw, unprocessed predictions. lindisp: bool. If True, sample linearly in inverse depth rather than in depth. perturb: float, 0 or 1. If non-zero, each ray is sampled at stratified random points in time. N_importance: int. Number of additional times to sample along each ray. These samples are only passed to network_fine. network_fine: "fine" network with same spec as network_fn. white_bkgd: bool. If True, assume a white background. raw_noise_std: ... verbose: bool. If True, print more debugging info. Returns: rgb_map: [num_rays, 3]. Estimated RGB color of a ray. Comes from fine model. disp_map: [num_rays]. Disparity map. 1 / depth. acc_map: [num_rays]. Accumulated opacity along each ray. Comes from fine model. raw: [num_rays, num_samples, 4]. Raw predictions from model. rgb0: See rgb_map. Output for coarse model. disp0: See disp_map. Output for coarse model. acc0: See acc_map. Output for coarse model. z_std: [num_rays]. Standard deviation of distances along ray for each sample. """ # 从ray_batch提取需要的数据 # 光束数量默认4096 N_rays = ray_batch.shape[0] rays_o, rays_d = ray_batch[:,0:3], ray_batch[:,3:6] # [N_rays, 3] each viewdirs = ray_batch[:,-3:] if ray_batch.shape[-1] > 8 else None # shape: bounds[4096,1,2] near[4096,1] far[4096,1] bounds = torch.reshape(ray_batch[...,6:8], [-1,1,2]) near, far = bounds[...,0], bounds[...,1] # [-1,1] # 每个光束上取N_samples个点,默认64个 t_vals = torch.linspace(0., 1., steps=N_samples) if not lindisp: z_vals = near * (1.-t_vals) + far * (t_vals) else: z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals)) z_vals = z_vals.expand([N_rays, N_samples]) if perturb > 0.: # get intervals between samples mids = .5 * (z_vals[...,1:] + z_vals[...,:-1]) upper = torch.cat([mids, z_vals[...,-1:]], -1) lower = torch.cat([z_vals[...,:1], mids], -1) # stratified samples in those intervals t_rand = torch.rand(z_vals.shape) # Pytest, overwrite u with numpy's fixed random numbers if pytest: np.random.seed(0) t_rand = np.random.rand(*list(z_vals.shape)) t_rand = torch.Tensor(t_rand) z_vals = lower + (upper - lower) * t_rand # 光束打到的位置(采样点),可用来输入网络查询颜色和密度 shape: pts[4096,64,3] pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples, 3] # raw = run_network(pts) # 根据pts,viewdirs进行前向计算。raw[4096,64,4],最后一个维是RGB+density。 raw = network_query_fn(pts, viewdirs, network_fn) # 这一步相当于是在做volume render,将光束颜色合成图像上的点 rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest) # 下面是有精细网络的情况,会再算一遍上述步骤,然后也封装到ret if N_importance > 0: # 保存前面的值 rgb_map_0, disp_map_0, acc_map_0 = rgb_map, disp_map, acc_map # 重新采样光束上的点 z_vals_mid = .5 * (z_vals[...,1:] + z_vals[...,:-1]) z_samples = sample_pdf(z_vals_mid, weights[...,1:-1], N_importance, det=(perturb==0.), pytest=pytest) z_samples = z_samples.detach() z_vals, _ = torch.sort(torch.cat([z_vals, z_samples], -1), -1) pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples + N_importance, 3] run_fn = network_fn if network_fine is None else network_fine # raw = run_network(pts, fn=run_fn) raw = network_query_fn(pts, viewdirs, run_fn) rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest) # 不管有无精细网络都要 # shape: rgb_map[4096,3] disp_map[4096] acc_map[4096] ret = {'rgb_map' : rgb_map, 'disp_map' : disp_map, 'acc_map' : acc_map} if retraw: ret['raw'] = raw if N_importance > 0: ret['rgb0'] = rgb_map_0 ret['disp0'] = disp_map_0 ret['acc0'] = acc_map_0 ret['z_std'] = torch.std(z_samples, dim=-1, unbiased=False) # [N_rays] for k in ret: if (torch.isnan(ret[k]).any() or torch.isinf(ret[k]).any()) and DEBUG: print(f"! [Numerical Error] {k} contains nan or inf.") return retraw2outputs()
把模型的预测转化为有实际意义的表达,输入预测、时间和光束方向,输出光束颜色、视差、密度、每个采样点的权重和深度
def raw2outputs(raw, z_vals, rays_d, raw_noise_std=0, white_bkgd=False, pytest=False): """Transforms model's predictions to semantically meaningful values. Args: raw: [num_rays, num_samples along ray, 4]. Prediction from model. z_vals: [num_rays, num_samples along ray]. Integration time. rays_d: [num_rays, 3]. Direction of each ray. Returns: rgb_map: [num_rays, 3]. Estimated RGB color of a ray. disp_map: [num_rays]. Disparity map. Inverse of depth map. acc_map: [num_rays]. Sum of weights along each ray. weights: [num_rays, num_samples]. Weights assigned to each sampled color. depth_map: [num_rays]. Estimated distance to object. """ raw2alpha = lambda raw, dists, act_fn=F.relu: 1.-torch.exp(-act_fn(raw)*dists) dists = z_vals[...,1:] - z_vals[...,:-1] dists = torch.cat([dists, torch.Tensor([1e10]).expand(dists[...,:1].shape)], -1) # [N_rays, N_samples] dists = dists * torch.norm(rays_d[...,None,:], dim=-1) # 获取模型预测的每个点的颜色 rgb = torch.sigmoid(raw[...,:3]) # [N_rays, N_samples, 3] noise = 0. if raw_noise_std > 0.: noise = torch.randn(raw[...,3].shape) * raw_noise_std # Overwrite randomly sampled data if pytest if pytest: np.random.seed(0) noise = np.random.rand(*list(raw[...,3].shape)) * raw_noise_std noise = torch.Tensor(noise) # 给密度加噪音 alpha = raw2alpha(raw[...,3] + noise, dists) # [N_rays, N_samples] # weights = alpha * tf.math.cumprod(1.-alpha + 1e-10, -1, exclusive=True) weights = alpha * torch.cumprod(torch.cat([torch.ones((alpha.shape[0], 1)), 1.-alpha + 1e-10], -1), -1)[:, :-1] rgb_map = torch.sum(weights[...,None] * rgb, -2) # [N_rays, 3] depth_map = torch.sum(weights * z_vals, -1) disp_map = 1./torch.max(1e-10 * torch.ones_like(depth_map), depth_map / torch.sum(weights, -1)) acc_map = torch.sum(weights, -1) if white_bkgd: rgb_map = rgb_map + (1.-acc_map[...,None]) return rgb_map, disp_map, acc_map, weights, depth_maprender_path()
根据pose等信息获得颜色和视差
def render_path(render_poses, hwf, K, chunk, render_kwargs, gt_imgs=None, savedir=None, render_factor=0): H, W, focal = hwf if render_factor!=0: # Render downsampled for speed H = H//render_factor W = W//render_factor focal = focal/render_factor rgbs = [] disps = [] t = time.time() for i, c2w in enumerate(tqdm(render_poses)): print(i, time.time() - t) t = time.time() rgb, disp, acc, _ = render(H, W, K, chunk=chunk, c2w=c2w[:3,:4], **render_kwargs) rgbs.append(rgb.cpu().numpy()) disps.append(disp.cpu().numpy()) if i==0: print(rgb.shape, disp.shape) """ if gt_imgs is not None and render_factor==0: p = -10. * np.log10(np.mean(np.square(rgb.cpu().numpy() - gt_imgs[i]))) print(p) """ if savedir is not None: rgb8 = to8b(rgbs[-1]) filename = os.path.join(savedir, '{:03d}.png'.format(i)) imageio.imwrite(filename, rgb8) rgbs = np.stack(rgbs, 0) disps = np.stack(disps, 0) return rgbs, dispsrun_nerf_helpers.py
这个里面写了一些必要的函数
class NeRF()
这个类用于创建model,alpha输出的是密度,rgb是颜色,一个batch是1024个光束,也就是一个光束采样64个点
class NeRF(nn.Module): def __init__(self, D=8, W=256, input_ch=3, input_ch_views=3, output_ch=4, skips=[4], use_viewdirs=False): """ """ super(NeRF, self).__init__() self.D = D self.W = W # 输入的通道 self.input_ch = input_ch # 输入的视角 self.input_ch_views = input_ch_views self.skips = skips self.use_viewdirs = use_viewdirs self.pts_linears = nn.ModuleList( [nn.Linear(input_ch, W)] + [nn.Linear(W, W) if i not in self.skips else nn.Linear(W + input_ch, W) for i in range(D-1)]) ### Implementation according to the official code release (https://github.com/bmild/nerf/blob/master/run_nerf_helpers.py#L104-L105) self.views_linears = nn.ModuleList([nn.Linear(input_ch_views + W, W//2)]) ### Implementation according to the paper # self.views_linears = nn.ModuleList( # [nn.Linear(input_ch_views + W, W//2)] + [nn.Linear(W//2, W//2) for i in range(D//2)]) if use_viewdirs: self.feature_linear = nn.Linear(W, W) self.alpha_linear = nn.Linear(W, 1) self.rgb_linear = nn.Linear(W//2, 3) else: self.output_linear = nn.Linear(W, output_ch) def forward(self, x): input_pts, input_views = torch.split(x, [self.input_ch, self.input_ch_views], dim=-1) h = input_pts for i, l in enumerate(self.pts_linears): h = self.pts_linears[i](h) h = F.relu(h) if i in self.skips: h = torch.cat([input_pts, h], -1) if self.use_viewdirs: alpha = self.alpha_linear(h) feature = self.feature_linear(h) h = torch.cat([feature, input_views], -1) for i, l in enumerate(self.views_linears): h = self.views_linears[i](h) h = F.relu(h) rgb = self.rgb_linear(h) outputs = torch.cat([rgb, alpha], -1) else: outputs = self.output_linear(h) return outputs def load_weights_from_keras(self, weights): assert self.use_viewdirs, "Not implemented if use_viewdirs=False" # Load pts_linears for i in range(self.D): idx_pts_linears = 2 * i self.pts_linears[i].weight.data = torch.from_numpy(np.transpose(weights[idx_pts_linears])) self.pts_linears[i].bias.data = torch.from_numpy(np.transpose(weights[idx_pts_linears+1])) # Load feature_linear idx_feature_linear = 2 * self.D self.feature_linear.weight.data = torch.from_numpy(np.transpose(weights[idx_feature_linear])) self.feature_linear.bias.data = torch.from_numpy(np.transpose(weights[idx_feature_linear+1])) # Load views_linears idx_views_linears = 2 * self.D + 2 self.views_linears[0].weight.data = torch.from_numpy(np.transpose(weights[idx_views_linears])) self.views_linears[0].bias.data = torch.from_numpy(np.transpose(weights[idx_views_linears+1])) # Load rgb_linear idx_rbg_linear = 2 * self.D + 4 self.rgb_linear.weight.data = torch.from_numpy(np.transpose(weights[idx_rbg_linear])) self.rgb_linear.bias.data = torch.from_numpy(np.transpose(weights[idx_rbg_linear+1])) # Load alpha_linear idx_alpha_linear = 2 * self.D + 6 self.alpha_linear.weight.data = torch.from_numpy(np.transpose(weights[idx_alpha_linear])) self.alpha_linear.bias.data = torch.from_numpy(np.transpose(weights[idx_alpha_linear+1]))get_rays_np()
获得光束的方法
def get_rays_np(H, W, K, c2w): # 生成网格点坐标矩阵,i和j分别表示每个像素的坐标 i, j = np.meshgrid(np.arange(W, dtype=np.float32), np.arange(H, dtype=np.float32), indexing='xy') dirs = np.stack([(i-K[0][2])/K[0][0], -(j-K[1][2])/K[1][1], -np.ones_like(i)], -1) # Rotate ray directions from camera frame to the world frame # 将光线方向从相机旋转到世界 rays_d = np.sum(dirs[..., np.newaxis, :] * c2w[:3,:3], -1) # dot product, equals to: [c2w.dot(dir) for dir in dirs] # Translate camera frame's origin to the world frame. It is the origin of all rays. # 将相机框架的原点转换为世界框架,它是所有光线的起源 rays_o = np.broadcast_to(c2w[:3,-1], np.shape(rays_d)) return rays_o, rays_dndc_rays()
把光线的原点移动到near平面
def ndc_rays(H, W, focal, near, rays_o, rays_d): # Shift ray origins to near plane t = -(near + rays_o[...,2]) / rays_d[...,2] rays_o = rays_o + t[...,None] * rays_d # Projection o0 = -1./(W/(2.*focal)) * rays_o[...,0] / rays_o[...,2] o1 = -1./(H/(2.*focal)) * rays_o[...,1] / rays_o[...,2] o2 = 1. + 2. * near / rays_o[...,2] d0 = -1./(W/(2.*focal)) * (rays_d[...,0]/rays_d[...,2] - rays_o[...,0]/rays_o[...,2]) d1 = -1./(H/(2.*focal)) * (rays_d[...,1]/rays_d[...,2] - rays_o[...,1]/rays_o[...,2]) d2 = -2. * near / rays_o[...,2] rays_o = torch.stack([o0,o1,o2], -1) rays_d = torch.stack([d0,d1,d2], -1) return rays_o, rays_d接下来我们了解一下数据是怎么读取的
load_llff.py
_load_data()
def _load_data(basedir, factor=None, width=None, height=None, load_imgs=True): # 读取npy文件 poses_arr = np.load(os.path.join(basedir, 'poses_bounds.npy')) poses = poses_arr[:, :-2].reshape([-1, 3, 5]).transpose([1,2,0]) bds = poses_arr[:, -2:].transpose([1,0]) # 单张图片 img0 = [os.path.join(basedir, 'images', f) for f in sorted(os.listdir(os.path.join(basedir, 'images'))) \ if f.endswith('JPG') or f.endswith('jpg') or f.endswith('png')][0] # 获取单张图片的shape sh = imageio.imread(img0).shape sfx = '' if factor is not None: sfx = '_{}'.format(factor) _minify(basedir, factors=[factor]) factor = factor elif height is not None: factor = sh[0] / float(height) width = int(sh[1] / factor) _minify(basedir, resolutions=[[height, width]]) sfx = '_{}x{}'.format(width, height) elif width is not None: factor = sh[1] / float(width) height = int(sh[0] / factor) _minify(basedir, resolutions=[[height, width]]) sfx = '_{}x{}'.format(width, height) else: factor = 1 imgdir = os.path.join(basedir, 'images' + sfx) if not os.path.exists(imgdir): print( imgdir, 'does not exist, returning' ) return # 包含了目标数据的路径 imgfiles = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir)) if f.endswith('JPG') or f.endswith('jpg') or f.endswith('png')] if poses.shape[-1] != len(imgfiles): print( 'Mismatch between imgs {} and poses {} !!!!'.format(len(imgfiles), poses.shape[-1]) ) return sh = imageio.imread(imgfiles[0]).shape poses[:2, 4, :] = np.array(sh[:2]).reshape([2, 1]) poses[2, 4, :] = poses[2, 4, :] * 1./factor if not load_imgs: return poses, bds def imread(f): if f.endswith('png'): return imageio.imread(f, ignoregamma=True) else: return imageio.imread(f) # 读取所有图像数据并把值缩小到0-1之间 imgs = imgs = [imread(f)[...,:3]/255. for f in imgfiles] # imgs = np.stack(imgs, -1) print('Loaded image data', imgs.shape, poses[:,-1,0]) return poses, bds, imgs_minify()
这个函数主要负责创建目标分辨率的数据集
def _minify(basedir, factors=[], resolutions=[]): # 判断是否需要加载,如果不存在对应下采样或者分辨率的文件夹就需要加载 needtoload = False for r in factors: imgdir = os.path.join(basedir, 'images_{}'.format(r)) if not os.path.exists(imgdir): needtoload = True for r in resolutions: imgdir = os.path.join(basedir, 'images_{}x{}'.format(r[1], r[0])) if not os.path.exists(imgdir): needtoload = True if not needtoload: return from shutil import copy from subprocess import check_output imgdir = os.path.join(basedir, 'images') imgs = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir))] imgs = [f for f in imgs if any([f.endswith(ex) for ex in ['JPG', 'jpg', 'png', 'jpeg', 'PNG']])] imgdir_orig = imgdir wd = os.getcwd() for r in factors + resolutions: if isinstance(r, int): name = 'images_{}'.format(r) resizearg = '{}%'.format(100./r) else: name = 'images_{}x{}'.format(r[1], r[0]) resizearg = '{}x{}'.format(r[1], r[0]) imgdir = os.path.join(basedir, name) if os.path.exists(imgdir): continue print('Minifying', r, basedir) os.makedirs(imgdir) check_output('cp {}/* {}'.format(imgdir_orig, imgdir), shell=True) ext = imgs[0].split('.')[-1] args = ' '.join(['mogrify', '-resize', resizearg, '-format', 'png', '*.{}'.format(ext)]) print(args) os.chdir(imgdir) # 修改当前工作目录 check_output(args, shell=True) os.chdir(wd) if ext != 'png': check_output('rm {}/*.{}'.format(imgdir, ext), shell=True) print('Removed duplicates') print('Done') load_llff_data()
def load_llff_data(basedir, factor=8, recenter=True, bd_factor=.75, spherify=False, path_zflat=False): poses, bds, imgs = _load_data(basedir, factor=factor) # factor=8 downsamples original imgs by 8x print('Loaded', basedir, bds.min(), bds.max()) # Correct rotation matrix ordering and move variable dim to axis 0 poses = np.concatenate([poses[:, 1:2, :], -poses[:, 0:1, :], poses[:, 2:, :]], 1) poses = np.moveaxis(poses, -1, 0).astype(np.float32) imgs = np.moveaxis(imgs, -1, 0).astype(np.float32) images = imgs bds = np.moveaxis(bds, -1, 0).astype(np.float32) # Rescale if bd_factor is provided # sc是进行边界缩放的比例 sc = 1. if bd_factor is None else 1./(bds.min() * bd_factor) # pose也就要对应缩放 poses[:,:3,3] *= sc bds *= sc if recenter: # 修改pose(shape=图像数,通道数,5)前四列的值,只有最后一列(高、宽、焦距)不变 poses = recenter_poses(poses) if spherify: poses, render_poses, bds = spherify_poses(poses, bds) else: # shape=(3,5)相当于汇集了所有图像 c2w = poses_avg(poses) print('recentered', c2w.shape) print(c2w[:3,:4]) ## Get spiral # Get average pose # 3*1 up = normalize(poses[:, :3, 1].sum(0)) # Find a reasonable "focus depth" for this dataset close_depth, inf_depth = bds.min()*.9, bds.max()*5. dt = .75 mean_dz = 1./(((1.-dt)/close_depth + dt/inf_depth)) # 焦距 focal = mean_dz # Get radii for spiral path shrink_factor = .8 zdelta = close_depth * .2 # 获取所有poses的3列,shape(图片数,3) tt = poses[:,:3,3] # ptstocam(poses[:3,3,:].T, c2w).T # 求90百分位的值 rads = np.percentile(np.abs(tt), 90, 0) c2w_path = c2w N_views = 120 N_rots = 2 if path_zflat: # zloc = np.percentile(tt, 10, 0)[2] zloc = -close_depth * .1 c2w_path[:3,3] = c2w_path[:3,3] + zloc * c2w_path[:3,2] rads[2] = 0. N_rots = 1 N_views/=2 # Generate poses for spiral path # 一个list,有120(由N_views决定)个元素,每个元素shape(3,5) render_poses = render_path_spiral(c2w_path, up, rads, focal, zdelta, zrate=.5, rots=N_rots, N=N_views) render_poses = np.array(render_poses).astype(np.float32) c2w = poses_avg(poses) print('Data:') print(poses.shape, images.shape, bds.shape) # shape 图片数 dists = np.sum(np.square(c2w[:3,3] - poses[:,:3,3]), -1) # 取到值最小的索引 i_test = np.argmin(dists) print('HOLDOUT view is', i_test) images = images.astype(np.float32) poses = poses.astype(np.float32) # images (图片数,高,宽,3通道), poses (图片数,3通道,5) ,bds (图片数,2) render_poses(N_views,图片数,5),i_test为一个索引数字 return images, poses, bds, render_poses, i_testrender_path_spiral()
def render_path_spiral(c2w, up, rads, focal, zdelta, zrate, rots, N): render_poses = [] rads = np.array(list(rads) + [1.]) hwf = c2w[:,4:5] for theta in np.linspace(0., 2. * np.pi * rots, N+1)[:-1]: c = np.dot(c2w[:3,:4], np.array([np.cos(theta), -np.sin(theta), -np.sin(theta*zrate), 1.]) * rads) z = normalize(c - np.dot(c2w[:3,:4], np.array([0,0,-focal, 1.]))) render_poses.append(np.concatenate([viewmatrix(z, up, c), hwf], 1)) return render_poses来源地址:https://blog.csdn.net/YuhsiHu/article/details/124676445








