
本篇内容主要讲解“Linux多核并行编程关键技术是什么”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Linux多核并行编程关键技术是什么”吧!
多核并行编程的背景
在摩尔定律失效之前,提升处理器性能通过主频提升、硬件超线程等技术就能满足应用需要。随着主频提升慢慢接近撞上光速这道墙,摩尔定律开始逐渐失效,多核集成为处理器性能提升的主流手段。现在市面上已经很难看到单核的处理器,就是这一发展趋势的佐证。要充分发挥多核丰富的计算资源优势,多核下的并行编程就不可避免,Linux kernel就是一典型的多核并行编程场景。但多核下的并行编程却挑战多多。
多核并行编程的挑战
目前主流的计算机都是冯诺依曼架构,即共享内存的计算模型,这种过程计算模型对并行计算并不友好。下图是一种典型的计算机硬件体系架构。
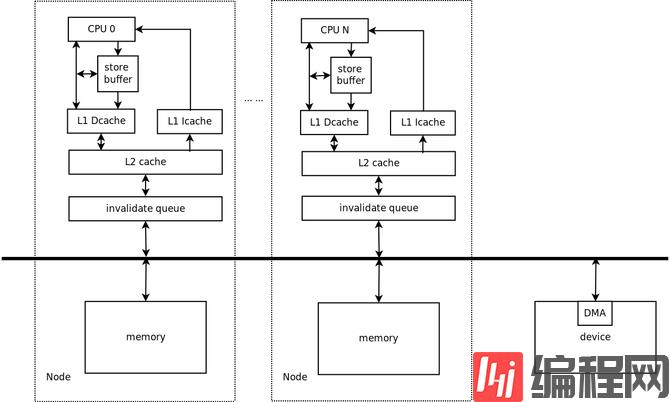
这种架构中,有如下设计特点:
·多个CPU核改善处理器的计算处理能力;
·多级cache改善CPU访问主存的效率;
·各个CPU都有本地内存(NUMA(非一致性内存访问)),进一步改善CPU访问主存的效率;
·store buffer模块改善cache write由于应答延迟而造成的写停顿问题;
·invalidate queue模块改善使无效应答的时延,把使无效命令放入queue后就立即发送应答;
外设DMA支持直接访问主存,改善CPU使用效率;
这些硬件体系设计特点也引入很多问题,最大的问题就是cache一致性问题和乱序执行问题。
cache一致性问题由cache一致性协议MESI解决,MESI由硬件保证,对软件来说是透明的。MESI协议保证所有CPU对单个cache line中单个变量修改的顺序保持一致,但不保证不同变量的修改在所有CPU上看到的是相同顺序。这就造成了乱序。不仅如此,乱序的原因还有很多:
·store buffer引起的延迟处理,会造成乱序;
·invalidate queue引起的延迟处理,会造成乱序;
·编译优化,会造成乱序;
·分支预测、多流水线等CPU硬件优化技术,会造成乱序;
·外设DMA,会造成数据乱序;
这种情况造成,就连简单的++运算操作的原子性都无法保证。这些问题必须采用多核并行编程新的技术手段来解决。
多核并行编程关键技术
锁技术
Linux kernel提供了多种锁机制,如自旋锁、信号量、互斥量、读写锁、顺序锁等。各种锁的简单比较如下,具体实现和使用细节这里就不展开了,可以参考《Linux内核设计与实现》等书的相关章节。
·自旋锁,不休眠,无进程上下文切换开销,可以用在中断上下文和临界区小的场合;
·信号量,会休眠,支持同时多个并发体进入临界区,可以用在可能休眠或者长的临界区的场合;
·互斥量,类似与信号量,但只支持同时只有一个并发体进入临界区;
·读写锁,支持读并发,写写/读写间互斥,读会延迟写,对读友好,适用读侧重场合;
·顺序锁,支持读并发,写写/读写间互斥,写会延迟读,对写友好,适用写侧重场合;
锁技术虽然能有效地提供并行执行下的竞态保护,但锁的并行可扩展性很差,无法充分发挥多核的性能优势。锁的粒度太粗会限制扩展性,粒度太细会导致巨大的系统开销,而且设计难度大,容易造成死锁。除了并发可扩展性差和死锁外,锁还会引入很多其他问题,如锁惊群、活锁、饥饿、不公平锁、优先级反转等。不过也有一些技术手段或指导原则能解决或减轻这些问题的风险。
·按统一的顺序使用锁(锁的层次),解决死锁问题;
·指数后退,解决活锁/饥饿问题;
·范围锁(树状锁),解决锁惊群问题;
·优先级继承,解决优先级反转问题 ;
原子技术
原子技术主要是解决cache不一致性和乱序执行对原子访问的破坏问题。主要的原子原语有:
ACCESS_ONECE():只限制编译器对内存访问的优化;
barrier():只限制编译器的乱序优化;
smb_wmb():写内存屏障,刷新store buffer,同时限制编译器和CPU的乱序优化;
smb_rmb():读内存屏障,刷新invalidate queue,同时限制编译器和CPU的乱序优化;
smb_mb():读写内存屏障,同时刷新store buffer和invalidate queue,同时限制编译器和CPU的乱序优化;
atomic_inc()/atomic_read()等:整型原子操作;
多提一句的是,atomic_inc()原语为了保证原子性,需要对cache进行刷新,而缓存行在多核体系下传播相当耗时,其多核下的并行可扩展性差。
无锁技术
上一小节中所提到的原子技术,是无锁技术中的一种,除此之外,无锁技术还包括RCU、Hazard pointer等。值得一提的是,这些无锁技术都基于内存屏障实现的。
Hazard pointer主要用于对象的生命周期管理,类似引用计数,但比引用计数有更好的并行可扩展性;
RCU适用的场景很多,其可以替代:读写锁、引用计数、垃圾回收器、等待事物结束等,而且有更好的并行扩展性。但RCU也有一些不适用的场景,如写侧重;临界区长;临界区内休眠等场景。
不过,所有的无锁原语也只能解决读端的并行可扩展性问题,写端的并行可扩展性只能通过数据分割技术来解决。
数据分割技术
分割数据结构,减少共享数据,是解决并行可扩展性的根本办法。对分割友好(即并行友好)的数据结构有:
·数组
·哈希表
·基树(Radix Tree)/稀疏数组
·跳跃列表(skip list)
使用这些便于分割的数据结构,有利于我们通过数据分割来改善并行可扩展性。
除了使用合适的数据结构外,合理的分割指导规则也很重要:
·读写分割:以读为主的数据与以写为主的数据分开;
·路径分割:按独立的代码执行路径来分割数据;
·专项分割:把经常更新的数据绑定到指定的CPU/线程中;
·所有权分割:按CPU/线程个数对数据结构进行分割,把数据分割到per-cpu/per-thread中;
4种分割规则中,所有权分割是分割最彻底的。
到此,相信大家对“Linux多核并行编程关键技术是什么”有了更深的了解,不妨来实际操作一番吧!这里是编程网网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!








