
Jupyter经验分享
前言
因为最近的业务问题,需要对大批量的数据进行数据处理。Pycharm在数据处理中比较繁琐,会面临大批量的运行,调试,代码修改。将为了提升数据处理效率,我们采用更专业saas平台:Jupyter Notebook,我更贴切的叫它草稿本。可能很多同学会使用anaconda,但我个人不建议这么做,因为anaconda很难解耦,没办法真正掌握jupyter轻量级的特点。今天就jupyter的轻量灵活分享一下我的经验。
安装Jupyter
创建虚拟环境python -m venv venv,进入虚拟环境venv\Scripts\activate
2、安装Jupyterpip install jupyter
3、启动Jupyerjupyter notebook,红色箭头所指就是Jupyter的访问地址,此处必须带上token
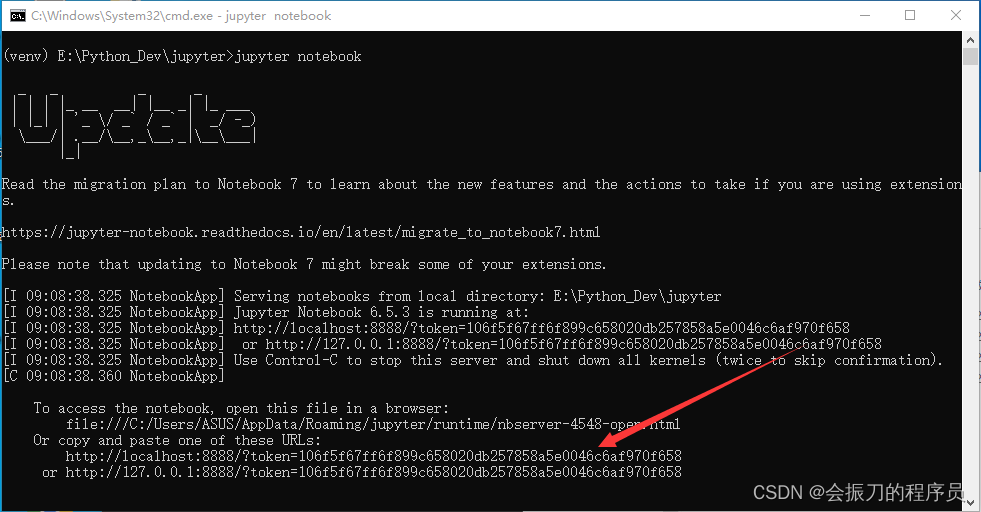
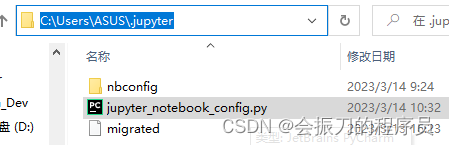
4、默认为8888端口。为确保jupyter有这个配置文件,执行jupyter notebook --generate-config生成一下。生成的配置文件在C盘中如图所示:
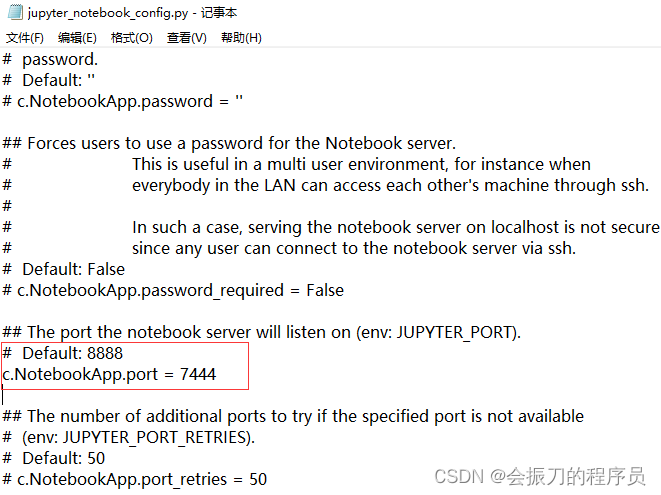
进入jupyter_notebook_config.py,修改端口即可
Jupyter的使用
创建jupyter文件
创建file文件或者floder文件夹都可以,'.ipynb’后缀就是jupyter的文件
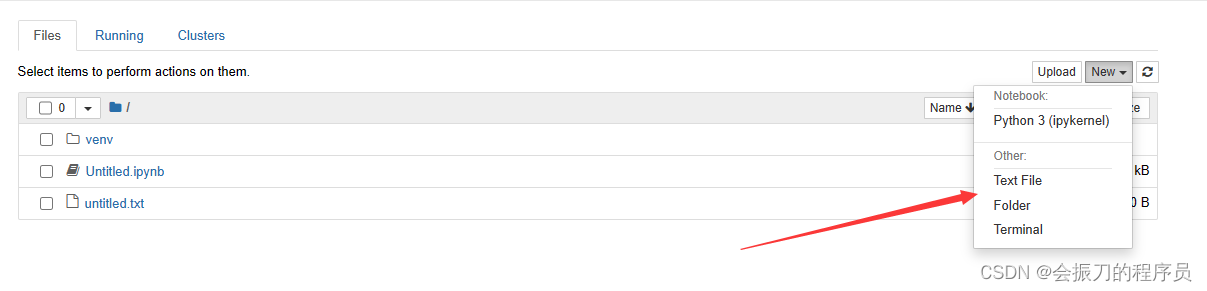
注意:创建文件的路径问题-------启动jupyter时的路径为根路径
分块运行
输入一段代码,shift+回车就可以自动执行代码片
清理运行结果
根据图中导向键选中即可
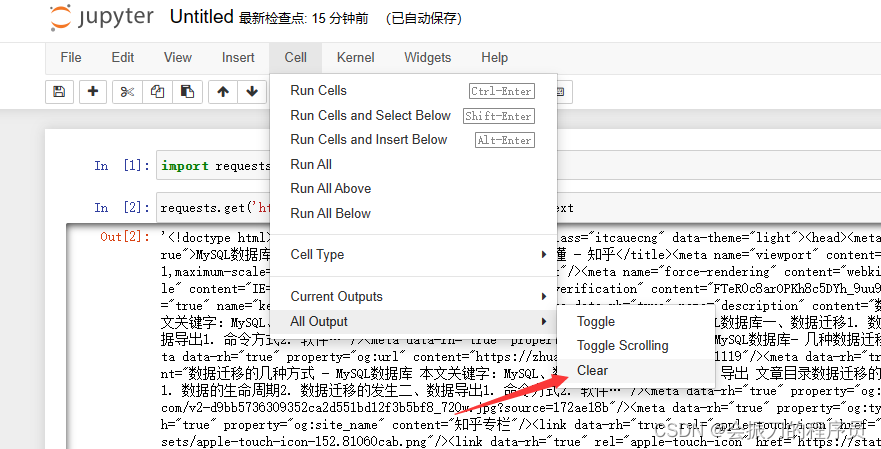
合并上下文
在我们处理完所有的数据之后,我们通常需要合并上下文,然后全文复制粘贴到Pycharm或vscode中。选中所有的代码块shift+m即可
代码补全
编写代码时,按tab键即可。
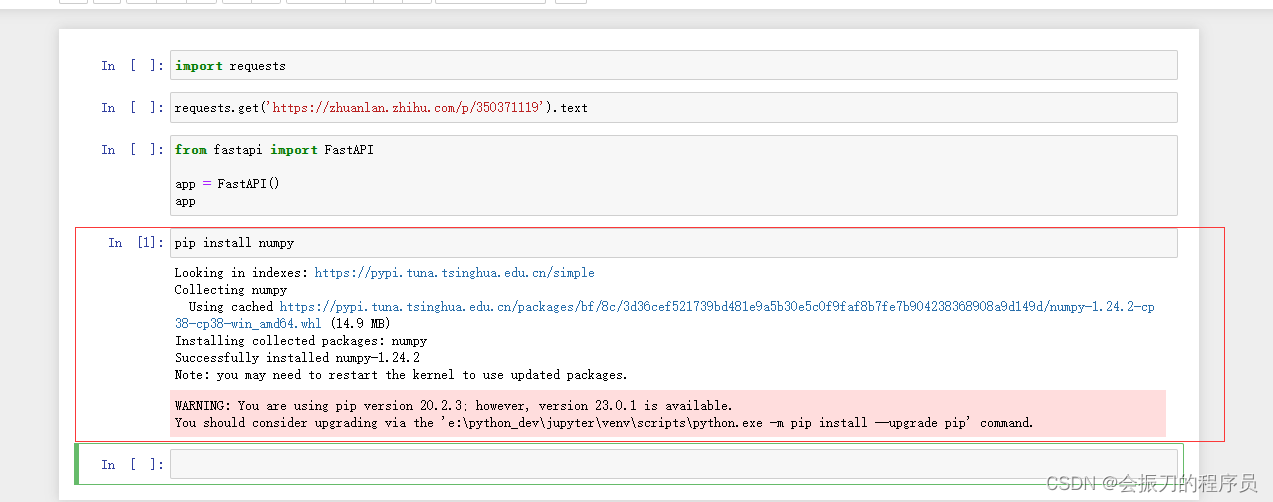
pip安装库,两种方式
正在使用jupyter时,我们难免要对库进行安装,我们只需要另起一个代码块输入pip install XXXX,然后 shift+回车执行 即可。
2、如图所示点击terminal进入命令行模式即可pip install XXX
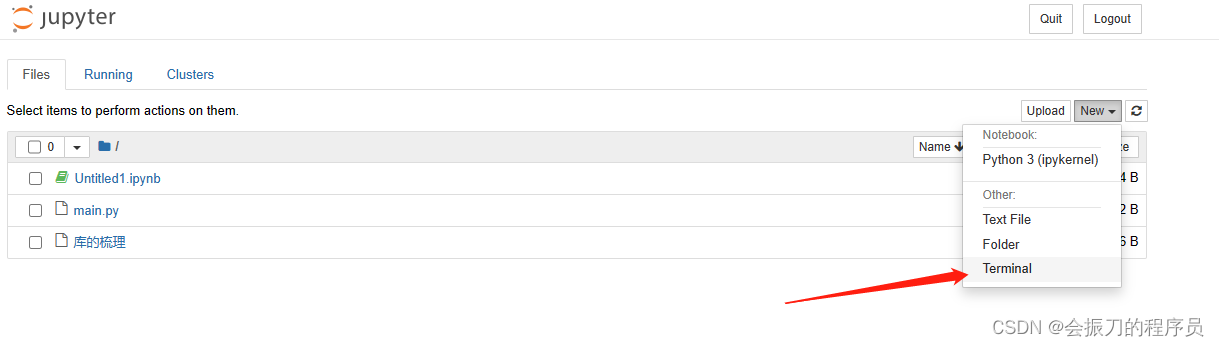
另外讲一下,因为我们是虚拟环境启动jupyter,故jupyter会使用虚拟环境中的三方库。
导出py、html或其他类文件
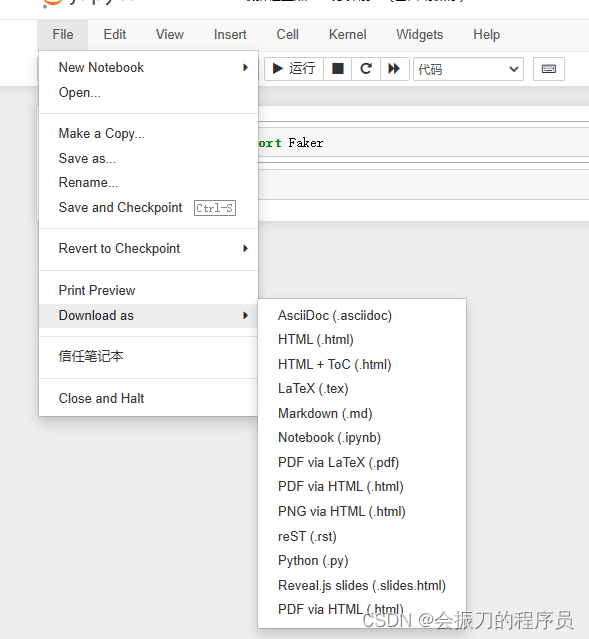
结语
jupyter是个非常好用的草稿本,数据处理的绝佳帮手。有问题欢迎留言指正!
来源地址:https://blog.csdn.net/l782060902/article/details/129499476







