
文章目录
- 数据库系统与概念 (6th) 第三章习题
- 实践习题
- 1. 使用大学模式,用SQL写出如下查询。
- 2. 假设给你一个关系grade_points( grade, points), 它提供从takes关系中用字母表示的成绩等级到数字表示的得分之间的转换。例如,“A" 等级可指定为对应于4分,“A-”对应于3.7分,“B+”对应于3.3分,“B”对应于3分,等等。学生在某门课程(课程段)上所获得的等级分值被定义为该课程段的学分乘以该生得到的成绩等级所对应的数字表示的得分。给定上述关系和我们的大学模式,用SQL写出下面的每个查询。为简单起见,可以假设没有任何takes元组在grade上取null值。
- 3. 使用大学模式,用SQL写出如下插人、删除和更新语句。
- 4. 考虑图3-18中的保险公司数据库,其中加下划线的是主码。为这个关系数据库构造出如下SQL查询:
- 5. 假设有关系 marks(ID, score) , 我们希望基于如下标准为学生评定等级:
- 6. SQL的like 运算符是大小写敏感的, 但字符串上的lower( )函数可用来实现大小写不敏感的匹配。
- 7. 考虑SQL 查询
- 8. 考虑图3-19中的银行数据库,其中加下划线的是主码。为这个关系数据库构造出如下SQL查询:
- 9. 考虑图3-20的雇员数据库,其中加下划线的是主码。为下面每个查询写出SQL表达式:
- 10. 考虑图3-20的关系数据库,给出下面每个查询的SQL表达式:
- 习题
- 11. 使用大学模式,请用 SQL 写出如下查询:
- 12. 使用大学模式, 用SQL写出如下查询。
- 13. 写出对应于图3-18中模式的SQL DDL,在数据类型上做合理的假设,确保声明主码和外码。
- 14. 考虑图 3-18中的保险公司数据库,其中加下划线的是主码。对这个关系数据库构造如下的SQL查询:
- 15. 考虑图3-19 中的银行数据库,其中加下划线的是主码。为这个关系数据库构直出如下SQL查询:
- 16. 考虑图3-20中的雇员数据库,其中主码被加了下划线。请给出下面每个查询的SQL表达式。
- 17. 考虑图3-19中的雇员数据库。请给出下面每个查询的SQL表达式。
- 18. 请给出图3-19的雇员数据库的 SQL模式定义。为每个属性选择合适的域, 并为每个关系模式选择合适的主码。引人任何合理的外码约束。
- 19. 列出两个原因,说明为什么空值可能被引入到数据库中。
- 20. 证明在 SQL中,<>all 等价于 not in.
- 21. 给出图 3-20 中雇员数据库的 SQL 模式定义。为每个属性选择合适的域,并为每个关系模式选择合适的主码。
- 22. 考虑图3.21中的图书馆教据率。用SQL写出如下查询:
- 23. 不使用 unique结构,重写下面的 where语句:
- 24. 考虑查询:
- 25. 考虑查询:
实践习题
1. 使用大学模式,用SQL写出如下查询。
(建议在一个数据库上实际运行这些查询,使用我们在本书的你用内机式,用S工提供的拜本数据,上述网站还提供了如何建立一个数据库和加载样本数能的说明。)
-
找出Comp. Sci. 系开设的具有3个学分的课程名称。
select titlefrom coursewhere dept_name='Comp. Sci.' and credits=3; -
找出名叫Einstein的教师所教的所有学生的标识,保证结果中没有重复。
select distinct student.namefrom student natural join takeswhere (course_id, sec_id, semester, year) in (select course_id, sec_id, semester, yearfrom instructor natural join teacheswhere name="Einstein"); -
找出教师的最高工资。
select max(salary)from instructor; -
找出工资最高的所有教师(可能有不止一一位 教师具有相同的工资)。
select name, salaryfrom instructorwhere salary = (select max(salary)from instructor); -
找出2018年春季开设的每个课程段的选课人数。
select course_id, sec_id, semester, year, count(*)from takeswhere semester='Spring' and year=2018group by course_id, sec_id, semester, year; -
从2018年春季开设的所有课程段中,找出最多的选课人数。
select max(stu_num)from (select course_id, sec_id, semester, year, count(*)from takeswhere semester='Spring' and year=2018group by course_id, sec_id, semester, year) as tmp(course_id, sec_id, semester, year, stu_num) -
找出在2018年春季拥有最多选课人数的课程段。
select course_id, sec_id, semester, year, stu_numfrom ( select course_id, sec_id, semester, year, count(*) from takes where semester='Spring' and year=2018 group by course_id, sec_id, semester, year) as tmp(course_id, sec_id, semester, year, stu_num)where stu_num = ( select max(stu_num) from ( select course_id, sec_id, semester, year, count(*) from takes where semester='Spring' and year=2018 group by course_id, sec_id, semester, year) as tmp(course_id, sec_id, semester, year, stu_num));2. 假设给你一个关系grade_points( grade, points), 它提供从takes关系中用字母表示的成绩等级到数字表示的得分之间的转换。例如,“A" 等级可指定为对应于4分,“A-”对应于3.7分,“B+”对应于3.3分,“B”对应于3分,等等。学生在某门课程(课程段)上所获得的等级分值被定义为该课程段的学分乘以该生得到的成绩等级所对应的数字表示的得分。给定上述关系和我们的大学模式,用SQL写出下面的每个查询。为简单起见,可以假设没有任何takes元组在grade上取null值。
create table grade_points( grade varchar(2) primary key, points float(2));insert into grade_points values ("A", 4.0);insert into grade_points values ("A-", 3.7);insert into grade_points values ("B+", 3.3);insert into grade_points values ("B", 3.0);insert into grade_points values ("B-", 2.7);insert into grade_points values ("C+", 2.3);insert into grade_points values ("C", 2.0);insert into grade_points values ("C-", 1.7);insert into grade_points values ("F", 1.0);-
根据ID为12345的学生所选修的所有课程,找出该生所获得的等级分值的总和。
select sum(points*credits)from (takes natural join grade_points) join course using(course_id)where ID = "12345"; -
找出上述学生等级分值的平均值(GPA),即用等级分值的总和除以相关课程学分的总和。
select sum(points*credits)/sum(credits)from (takes natural join grade_points) join course using(course_id)where ID = "12345"; -
找出每个学生的ID和等级分值的平均值。
select ID, sum(points*credits)/sum(credits) as gpafrom (takes natural join grade_points) join course using(course_id)group by IDorder by gpa;
3. 使用大学模式,用SQL写出如下插人、删除和更新语句。
a. 给Comp. Sci. 系的每位教师涨10%的工资。
update instructorset salary = 1.1*salarywhere dept_name="Comp. Sci.";b.删除所有未开设过(即没有出现在section关系中)的课程。
delete from coursewhere course_id not in (select distinct course_idfrom section);c.把每个在tot_cred属性上取值超过100的学生作为同系的教师插入,工资为30000美元。
insert into instructorselect ID, name, dept_name, 30000from studentwhere tot_cred > 100;4. 考虑图3-18中的保险公司数据库,其中加下划线的是主码。为这个关系数据库构造出如下SQL查询:
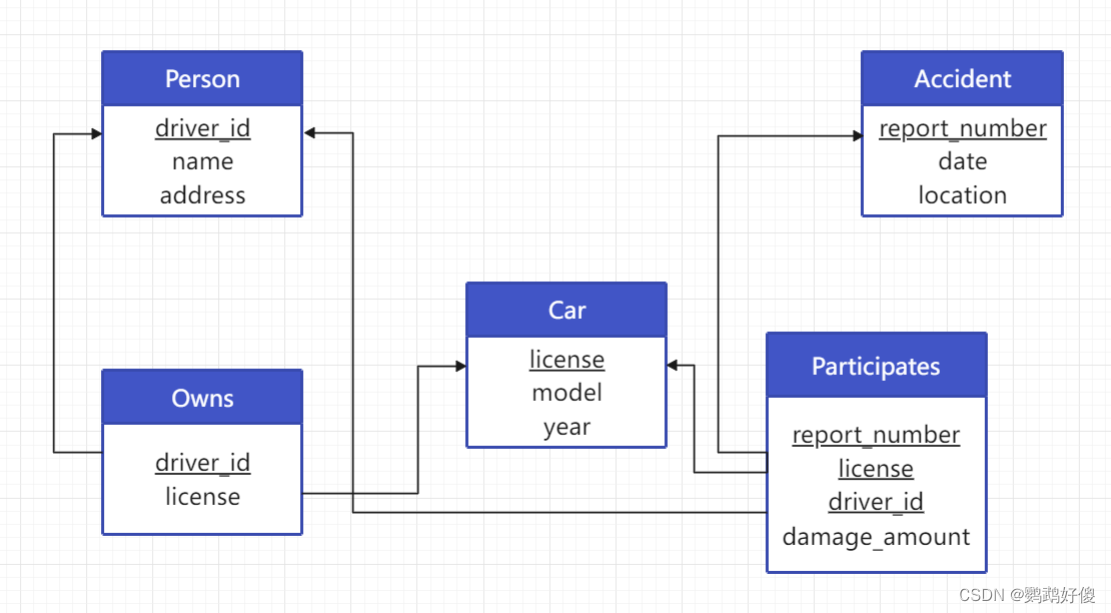
a.找出2009年其车辆出过交通事故的人员总数。
select count(distinct driver_id)from participates join accident using (report_number)where date = "2009";b.向数据库中增加一个新的事故,对每个必需的属性可以设定任意值。
insert into accident values("66666", "2019", "NewYork");c. 删除“John Smith"拥有的马自达车( Mazda)。
delete from ownswhere (owns.driver_id, owns.license) = (select driver_id, licensefrom (person natural join owns) join car using (license)where name="John Smith" and model="Mazda");5. 假设有关系 marks(ID, score) , 我们希望基于如下标准为学生评定等级:
- 如果 score<40 得 F
- 如果 40
- 如果 score<80 得 B
- 如果 80
写出sql查询完成下列操作:
a 基于marks关系显示每个学生的等级。
select ID, casewhen score < 40 then 'F'when score < 60 then 'C'when score < 80 then 'B'else 'A'endfrom marks;b 找出各等级的学生数。 \textcolor{red}{找出各等级的学生数。} 找出各等级的学生数。
select grade, count(*)from (select ID, ( case when score < 40 then 'F' when score < 60 then 'C' when score < 80 then 'B' else 'A' end) from marks) as id_grade(ID, grade)group by grade;6. SQL的like 运算符是大小写敏感的, 但字符串上的lower( )函数可用来实现大小写不敏感的匹配。
为了说明是怎么用的, 写出这样一个查询: 找出名称中包含了 “sci” 子串的系,忽略大小写。
select dept_namefrom departmentwhere lower(dept_name) like "%sci%";7. 考虑SQL 查询
select distinct p.alfrom p, rl, r2 where p.al=rl.al or p.al =r2.al在什么条件下这个查询选择的 p.al 值要么在 r1 中,要么在 r2 中? 仔细考察 r1 或 r2 可能为空的情况。
8. 考虑图3-19中的银行数据库,其中加下划线的是主码。为这个关系数据库构造出如下SQL查询:

-
找出银行中所有有账户但无贷款的客户。
select customer_namefrom depositorwhere customer_name not in (select customer_namefrom borrower); -
找出与“Smith"居住在同一一个城市、同一个街道的所有客户的名字。
# 方法 1select customer_namefrom customerwhere (customer_street, customer_city) = (select customer_street, customer_cityfrom customerwhere customer_name = "Smith");# 方法 2select customer_namefrom customer as S, customer as Twhere S.customer_name = "Smith" and T.customer_street = S.customer_street and T.customer_city = S.customer_city; -
找出所有支行的名称,在这些支行中都有居住在 " Hrrison" 的客户所开设的账户。
select distinct branch_namefrom (account natural join customer) join depositor using(account_number)where customer_city = "Hrrison";
9. 考虑图3-20的雇员数据库,其中加下划线的是主码。为下面每个查询写出SQL表达式:

-
找出所有为“First Bank Corporation" 工作的雇员名字及其居住城市。
select person_name, cityfrom employee join works using(ID)where company_name = "First Bank Corporation"; -
找出所有为“First Bank Corporation"工作且薪金超过10 000美元的雇员名字、居住街道和城市。
select person_name, street, cityfrom employee join works using(ID)where company_name="First Bank Corporation" and salary > 10000; -
找出数据库中所有不为“First Bank Corporation"工作的雇员。
select ID, person_namefrom employee join works using(ID)where company_name <> "First Bank Corporation"; -
找出数据库中工资高于“Small Bank Corporation" 的每个雇员的所有雇员。
select ID, person_namefrom employee join works using (ID)where salary > (select max(salary)from workswhere company_name = "Small Bank Corporation"); -
假设一个公司可以在好几个城市有分部。找出位于“Small Bank Corporation"所有所在城市的所有公司。
select distinct company_namefrom companywhere city in (select cityfrom companywhere company_name = "Small Bank Corporation"); -
找出雇员最多的公司。
select comp_namefrom ( select (company_name, count(ID)) from works group by company_name ) as comp_worker(comp_name, num_worker)where num_worker = (select max(num_worker)from ( select (company_name, count(ID)) from works group by company_name ) as comp_worker(comp_name, num_worker)); -
找出平均工资高于“First Bank Corporatin"平均工资的那些公司。
select company_namefrom (select company_name avg(salary)from worksgroup by company_name) as comp_avg(comp_name, avg_salary)where avg_salary > (select avg(salary)from workswhere company_name = "First Bank Corporation");
10. 考虑图3-20的关系数据库,给出下面每个查询的SQL表达式:

-
修改数据库使 “Jones" 现在居住在 “Newtown" 市。
update employeeset city="Newtown"where person_name = "Jones"; -
为 “Fist Bank Copontions” 所有工资不超过 10 0000 美元的经理增长 10% 工资,对工资超过10 0000 美元的只增长3%。
update worksset salary = casewhen salary <= 100000 then salary * 1.1else salary * 1.03where ID in ( select distinct manager_idfrom manages)
习题
11. 使用大学模式,请用 SQL 写出如下查询:
-
找出至少选修了一门 Comp. Sci 课程的学生姓名和 ID,保证结果中没有重复的姓名。
select distinct name, IDfrom (takes natural join student) join course using(course_id)where course.dept_name="Comp. Sci."group by name,IDhaving count(*) > 1order by name; -
找出所有没有选修在 2017 年之前开设的任何课程的每名学生的 ID 和姓名。
select name, IDfrom (takes natural join student) group by name, IDhaving min(year)>2017; -
找出每个系教师的最高工资值。可以假设每个系至少有一位教师。
select dept_name, max(salary)from instructorgroup by dept_name; -
从前述查询所计算出的每个系最高工资中选出所有系中的最低值。
select dept_name, min(max_salary)from (select dept_name, max(salary) from instructor group by dept_name) as dept_salary(dept_name, max_salary);
12. 使用大学模式, 用SQL写出如下查询。
-
创建一门课程 "CS-001”, 其名称为 “Weekly Seminar”,学分为 1。
insert into course values("CS-001", "Weekly Seminar", "Comp. Sci.", 1); -
创建该课程在 2018 年秋季的一一个课程段,sec_id 为 1。
insert into sectionvalues("CS-001", 1, "Fall", 2018, "Taylor", "3128", "A"); -
让 Comp. Sci. 系的每个学生都选修上述课程段。
insert into takesselect ID, "CS-001", 1, "Fall", 2018, nullfrom studentwhere dept_name="Comp. Sci."; -
删除名为 Chavez 的学生选修上述课程段的信息。
delete from takeswhere course_id="CS-001" and ID = (select IDfrom studentwhere name="Chavez"); -
删除课程CS-001。 如果在运行此删除语句之前,没有先删除这门课程的授课信息 (课程段),会发生什么事情?
delete from coursewhere course_id="CS-001";# create table 时使用了 on delete cascade 所以即使没有删除 section 里的开课信息,也可以正常删除 course 里的 CS-001,同时也会自动删除 section 和 takes 里面和该课有关的元组。 -
删除课程名称中包含 “database" 的任意棵程的任意课程段所对应的所有 takes 元组,在课程名的匹配中忽略大小写。
delete from takeswhere course_id in (select course_idfrom coursewhere lower(title) like "%database%");
13. 写出对应于图3-18中模式的SQL DDL,在数据类型上做合理的假设,确保声明主码和外码。
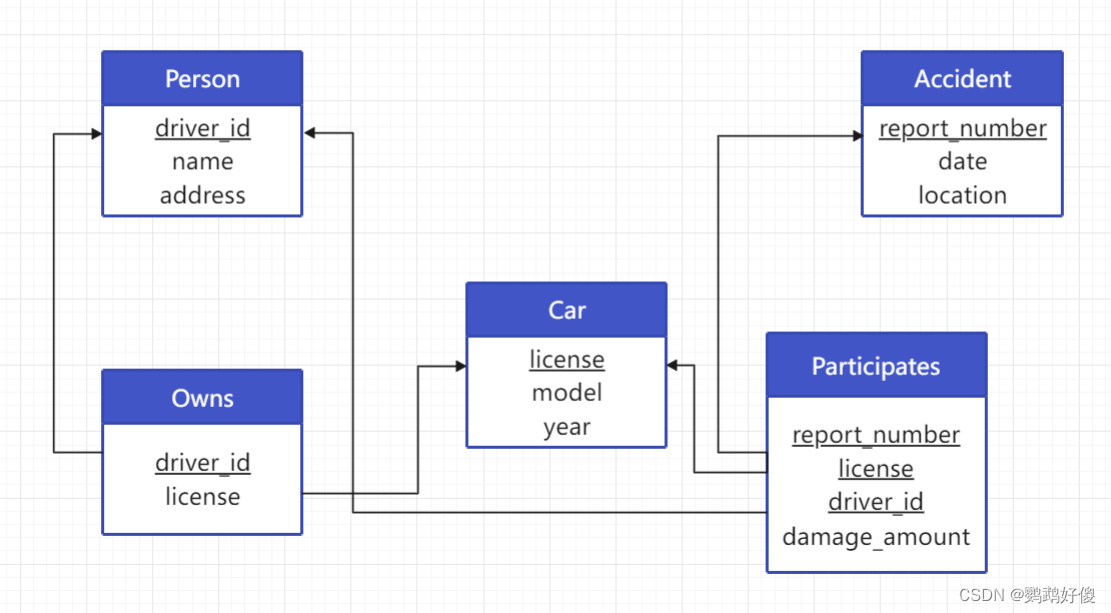
create table person(driver_id varchar(10) primary key,namevarchar(10),addressvarchar(50));create table car(licensevarchar(10) primary key,modelvarchar(25),yearnumeric(4,0) check (year > 1701 and year < 2100));create table accident(report_numbervarchar(20) primary key,dateDATE,locationvarchar(100));create table owns(driver_idvarchar(10) primary key,licensevarchar(10),foreign key (driver_id) references person(driver_id),foreign key (license) references car(license));create table participates(report_number varchar(20),license varchar(10),driver_idvarchar(10),damage_amountnumeric(18, 2),primary key (report_number, license, driver_id),foreign key (report_number) references accident(report_number),foreign key (license) references car(license),foreign key (driver_id) references person(driver_id));14. 考虑图 3-18中的保险公司数据库,其中加下划线的是主码。对这个关系数据库构造如下的SQL查询:
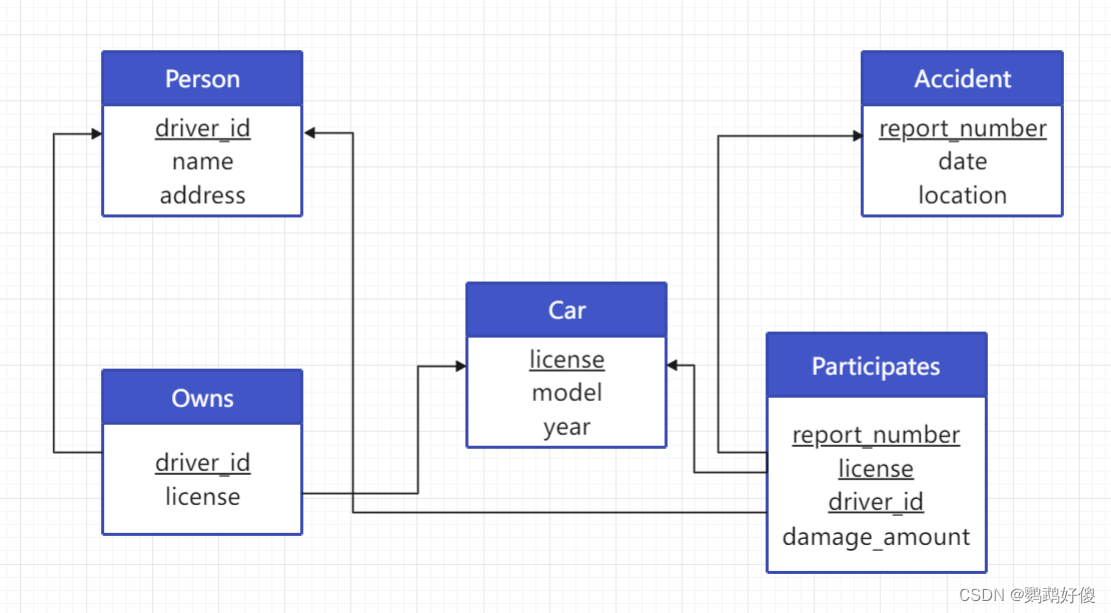
-
找出和 “John Smith" 的车有关的交通事故数量。
select count(report_number)from participateswhere driver_id in (select driver_idfrom personwhere name="John Smith");select count(report_number)from participates natural join personwhere name="John Smith"; -
对事故报告编号为 “AR2197" 中的车牌是 “AABB2000" 的车辆损坏保险费用更新到 3000 美元
update participatesset damage_amount = 3000where report_number="AR2197" and license="AABB2000";
15. 考虑图3-19 中的银行数据库,其中加下划线的是主码。为这个关系数据库构直出如下SQL查询:

-
找出在“ B r o o k l y n " 的所有支行都有账户的所有客户。 \textcolor{red}{找出在 “Brooklyn" 的所有支行都有账户的所有客户。} 找出在“Brooklyn"的所有支行都有账户的所有客户。
select S.customer_namefrom (account natural join depositor natural join customer natural join branch)) as Swhere exists((select branch_city from (account natural join depositor natural join customer natural join branch)) as T where S.customer_name = T.customer_name) except ( select branch_name from branch where branch_city="Brooklyn")); -
找出银行的所有贷款额的总和。
select sum(amount)from loan; -
找出总资产至少比位于 Brooklyn 的某一-家支行要多的所有支行名字。
select branch_namefrom branchwhere assets > (select min(assets)from branchwhere branch_city = "Brooklyn");
16. 考虑图3-20中的雇员数据库,其中主码被加了下划线。请给出下面每个查询的SQL表达式。
-
找出每位这样的雇员的ID和姓名: 该雇员所居住的城市与其工作的公司所在城市一样。
select ID, person_namefrom (employee natural join works) join company using(company_name)where employee.city = company.city; -
找出所居住的城市和街道与其经理相同的每位雇员的ID和姓名。
select ID, person_namefrom (employee natural join manages) as Swhere (S.street, S.city) = (select employee.street, employee.city from employee where employee.ID = (select manager_id from manages where manages.ID = S.ID)); -
找出工资高于其所在公司所有雇员平均工资的每位雇员的ID和姓名。
select ID, person_namefrom (employee natural join works) as Swhere salary > (select avg(salary) from (employee natural join works) as T where S.company_name = T.company_name); -
找出工资总和最小的公司。
select comp_name, sum_salaryfrom (select company_name, sum(salary)from works group by company_name ) as comp_salary(comp_name, sum_salary);where sum_salary = (select min(sum_salary) from (select company_name, sum(salary) from works group by company_name ) as comp_salary(comp_name, sum_salary));
17. 考虑图3-19中的雇员数据库。请给出下面每个查询的SQL表达式。
-
为“First Bank Corporation"的所有雇员增长10%的工资。
update works set salary = salary * 1.1where company_name = 'First Bank Corporation'; -
为“First Bank Corporation"的所有经理增长10%的工资。
update works set salary = salary * 1.1where company_name = 'First Bank Corporation' and ID in (select manager_id from manages); -
删除“Small Bank Corporation"的雇员在works关系中的所有元组。
delete from workswhere company_name = 'Small Bank Corporation';
18. 请给出图3-19的雇员数据库的 SQL模式定义。为每个属性选择合适的域, 并为每个关系模式选择合适的主码。引人任何合理的外码约束。
SQL 模式定义:
create database employees;use employees;create table employee(IDvarchar(5) primary key, person_namevarchar(25), streetvarchar(100), cityvarchar(50));create table works(IDvarchar(5) primary key, company_namevarchar(50), salarydecimal(8,2), foreign key (ID) references employee(ID), foreign key (company_name) references company(company_name));create table company(company_namevarchar(50) primary key, cityvarchar(50));create table manages(IDvarchar(5) primary key, manager_idvarchar(5), foreign key (ID) references employee(ID), foreign key (manager_id) references employee(ID),); 19. 列出两个原因,说明为什么空值可能被引入到数据库中。
- 插入数据时,对那些没有标注为 not null 的属性插入了 null 值
- 执行外连接的时候,join 左右两边的关系模式中有不匹配的元组,此时缺少的那些属性值就会被赋值为 null 然后插入到结果中。
- 外码完整性约束中有一项是 on delete null,如果被引用的元组被删除了,引用该元组的元组中对应数据会被赋值为 null
20. 证明在 SQL中,<>all 等价于 not in.
假设 a 为一个整数,B 为一个整数集合,我们来证:
-
a <> all B ⇒ \Rightarrow ⇒ a not in B
a <> all B,说明:对 ∀ b ∈ B \forall~b \in B ∀ b∈B, 均有 a ≠ b a \ne b a=b, 也就是说: a ∉ B a \notin B a∈/B, 即:a not in B
-
a not in B ⇒ \Rightarrow ⇒ a <> all B
a not in B 说明:不存在一个 b ∈ B b \in B b∈B 使得: b = a b = a b=a, 即:对 ∀ b ∈ B \forall~b \in B ∀ b∈B 均有: b ≠ a b \ne a b=a,即:a <> all B
21. 给出图 3-20 中雇员数据库的 SQL 模式定义。为每个属性选择合适的域,并为每个关系模式选择合适的主码。
create table employee(IDvarchar(10)primary key,person_namevarchar(20),streetvarchar(50),cityvarchar(10));create table company(company_namevarchar(50)primary key,cityvarchar(10));create table works(IDvarchar(10) primary key,company_namevarchar(50),salarynumeric(9, 2),foreign key (ID) references employee(ID),foreign key (company_name) references company(company_name));create table manages(IDvarchar(10) primary key,manages_id varchar(10),foreign key (ID) references employee(ID),foreign key (manages_id) references employee(ID));22. 考虑图3.21中的图书馆教据率。用SQL写出如下查询:

-
打印借阅了任意由 “MeGraw-Hill" 出版的书的会员名字。
select distinct namefrom member natural join borrowed natural join bookwhere publisher = "MeGraw-Hill"; -
打印借阅了所有由"MeGraw HilI" 出版的书的会员名字
select S.memb_no, S.namefrom (member natural join borrowed natural join book) as Swhere exists (select isdn from (member natural join borrowed natural join book) as T where S.memb_no = T.memb_no) except (select isdn from book where publisher = "MeGraw Hill"); -
对于每个出版商,打印借阅了多于 5 本由该出版商出版的书的会员名字。 \textcolor{red}{对于每个出版商,打印借阅了多于 5 本由该出版商出版的书的会员名字。} 对于每个出版商,打印借阅了多于5本由该出版商出版的书的会员名字。
select publisher, name, count(isdn)from member natural join borrowed natural join bookgroup by publisher, memb_id, namehaving count(isdn)>5; -
打印每位会员借阅书籍数量的平均值。考虑这样的情况:如果某会员没有借阅任何书籍,那么该会员根本不会出现在 borrowed 关系中。
select (select count(*) from borrowed) / (select count(*) from member);
23. 不使用 unique结构,重写下面的 where语句:
where unique (select title from course);where (select count(distinct title) from course) = (select count(title) from course);24. 考虑查询:
select course_id, semester, year, sec_id, avg(tot_cred)from takes natural join studentwhere year = 2018group by course_id, semester, year, sec_idhaving count(ID) >= 2解释为什么在 from 子句中还加上与section的连接不会改变查询结果。
section 和 student 没有共同的属性,section 和 takes 的共同属性有:course_id, semester, year, sec_id,这些属性构成了 section 的主键,所以 takes 的每一个元组都会唯一对应一个 section 中的元组,也就是连接结果中不会额外增加元组的数目。此外,原查询想要找出 2018 年至少有两位学生上的课程的 id, semester, year, sec_id 和学生的平均总学分。显然这与 section 中的信息没有关系。
所以在from 子句中加上与section的连接不会改变查询结果。
25. 考虑查询:
with dept_total (dept_name, value) as(select dept_name, sum(salary) from instructor group by dept_name),dept_total_avg(value) as(select avg(value) from dept_total)select dept_namefrom dept_total, dept_total_avgwhere dept_total.value >= dept_total_avg.value;不使用with结构,重写此查询。
题中 SQL 语句查询这样的部门名称:这个部门的教师的总工资大于部门总工资的平均值
select dept_namefrom instructorgroup by dept_namehaving sum(salary) > ( (select sum(salary) from instructor) / (select count(distinct dept_name) from instructor));group by course_id, semester, year, sec_id
having count(ID) >= 2
解释为什么在 from 子句中还加上与section的连接不会改变查询结果。section 和 student 没有共同的属性,section 和 takes 的共同属性有:course_id, semester, year, sec_id,这些属性构成了 section 的主键,所以 takes 的每一个元组都会唯一对应一个 section 中的元组,也就是连接结果中不会额外增加元组的数目。此外,原查询想要找出 2018 年至少有两位学生上的课程的 id, semester, year, sec_id 和学生的平均总学分。显然这与 section 中的信息没有关系。所以在from 子句中加上与section的连接不会改变查询结果。### 考虑查询:```sqlwith dept_total (dept_name, value) as(select dept_name, sum(salary) from instructor group by dept_name),dept_total_avg(value) as(select avg(value) from dept_total)select dept_namefrom dept_total, dept_total_avgwhere dept_total.value >= dept_total_avg.value;不使用with结构,重写此查询。
题中 SQL 语句查询这样的部门名称:这个部门的教师的总工资大于部门总工资的平均值
select dept_namefrom instructorgroup by dept_namehaving sum(salary) > ( (select sum(salary) from instructor) / (select count(distinct dept_name) from instructor));来源地址:https://blog.csdn.net/m0_46927364/article/details/127289020










