
目录
第1关 关系模型
数据库数据模型通常可分为三种:关系模型、层次模型和网状模型。
关系型数据模型
用二维表表示实体类型及实体间联系的数据模型称之为关系数据模型。
关系型数据模型对应的数据库自然就是关系型数据库了,这是目前应用最多的数据库。
关系模型基本术语
在关系模型种有以下术语:
-
关系:一个关系对应通常说的一张表。
-
元组:表中的一行即为一个元组。
-
属性:表中的一列即为一个属性,给每一个属性起一个名称即属性名。
-
码:也称码键,表中的某个属性组,它可以唯一确定一个元组。
-
域:是一组具有相同数据类型的值的集合,属性的取值范围来自某个域。
-
分量:元组中的一个属性值。
-
关系模型:对关系的描述,一般表示为:关系名(属性1,属性2,…,属性 n)
注意:关系必须是规范化的,满足一定的规范条件。最基本的规范条件:关系的每一个分量必须是一个不可分的数据项,不允许表中还有表。
关系模型的数据操纵与完整性约束
-
数据操纵
关系模型的数据操纵主要包括查询、插入、删除和更新数据,它的数据操纵是集合操作,操作对象和操作结果都是关系,如关系代数。
-
完整性约束
数据及其联系所具有的制约和依赖规则,保证数据的正确性、有效性和相容性
关系必须满足实体完整性、参照完整性和用户定义完整性约束
关系模型优缺点
-
优点
-
结构简单,都是一些表格的框架,实体的属性是表格中列的条目,实体之间的关系也是通过表格的公共属性表示,结构简单明了。
-
存取路径对用户而言是完全隐蔽的,使程序和数据具有高度的独立性,其数据语言的非过程化程度较高。
-
操作方便,操作的基本对象是集合而不是某一个元祖。
-
有坚实的数学理论做基础,包括逻辑计算、数学计算等。
-
缺点
-
查询效率低,关系数据模型提供了较高的数据独立性和非过程化的查询功能(查询的时候只需指明数据存在的表和需要的数据所在的列,不用指明具体的查找路径),因此加大了系统的负担。
-
由于查询效率较低,因此需要数据库管理系统对查询进行优化,加大了 DBMS 的负担。
use mydb;实验
例如以学生选课系统为例进行说明:
学生选课系统的实体包括:学生、教师、课程;其联系一般为学生与课程之间是一种多对多的关系,教师与课程之间是多对多的关系。学生可以同时选择多门课程,一门课程也可以同时被多个学生同时选择;一位教师可以教授多门课程,一门可能可以由多个教师教授。因此他们之间的联系如下:

将该 E-R 图映射为关系数据模型中的表格如下:
- 学生
- 课程
- 教师
- 选课
- 教课
从中我们可以观察到学生与课程之间的联系以及教师和课程之间的多对多联系都被映射成了表格。其中选课表中的 stu_id 和 course_id 分别是引用学生表和课程表的 course_id 的外键,教课表也是如此。
编程要求
编写 SQL 语句,将 E-R 图 转换成二维表,创建这些转换的表。 E-R 图如下:

说明:一共涉及五张表,将表明分别确定为t_player(参赛选手表)、t_school(参赛学校表)、t_product(参赛作品表)、t_player_product(参赛选手与作品联系表)和t_school_player(参赛选手与学校联系表),创表时除两张关联表外,各字段顺序按照图中标签顺序拟定,字段类型除编号、学号、得分、电话、大小为int(11),其他字段皆为varchar(32)。
两张关联表字段顺序如下:
- t_player_product
| 字段 | 说明 |
|---|---|
| p_id | 选手编号 |
| pr_id | 作品编号 |
| pr_grade | 作品成绩 |
| grade_rates | 获奖等级 |
- t_school_player
| 字段 | 说明 |
|---|---|
| s_name | 学校名称 |
| p_id | 选手编号 |
头歌实验代码
#请在此添加实现代码########## Begin ###########在mydb库中创建表create table t_player( p_id int(11) NOT NULL, p_name varchar(32) NOT NULL, p_sex varchar(32) NOT NULL, p_num int(11) NOT NULL, p_email varchar(32) NOT NULL, PRIMARY KEY (p_id) );create table t_school( s_name varchar (32) NOT NULL, s_address varchar(32) NOT NULL, s_telephone int(11) NOT NULL, s_email varchar (32) NOT NULL, PRIMARY KEY (s_name));create table t_product( pr_id int(11) NOT NULL, pr_name varchar(32) NOT NULL, pr_kind varchar(32) NOT NULL, pr_link varchar(32) NOT NULL, pr_size int(11) NOT NULL, PRIMARY KEY (pr_id));create table t_player_product( p_id int(11) NOT NULL, pr_id int(11) NOT NULL, pr_grade int(11) NOT NULL, grade_rates varchar(11) NOT NULL, CONSTRAINT fk_player_product1 FOREIGN KEY t_player_product(p_id) REFERENCES t_player(p_id), CONSTRAINT fk_player_product2 FOREIGN KEY t_player_product(pr_id) REFERENCES t_product(pr_id));create table t_school_player( s_name varchar(32) NOT NULL, p_id int(11) NOT NULL, CONSTRAINT fk_school_stu1 FOREIGN KEY t_school_player(s_name) REFERENCES t_school(s_name), CONSTRAINT fk_school_stu2 FOREIGN KEY t_school_player(p_id) REFERENCES t_player(p_id));########## End ##########第2关 层次模型
层次型数据模型
层次模型是数据库系统中最早出现的数据模型,层次数据库系统采用层次模型作为数据的组织方式。它采用树形结构来表示各类实体以及实体间的联系。
其实层次数据模型就是的图形表示就是一个倒立生长的树,由基本数据结构中的树(或者二叉树)的定义可知,每棵树都有且仅有一个根节点,其余的节点都是非根节点。每个节点表示一个记录类型对应与实体的概念,记录类型的各个字段对应实体的各个属性。各个记录类型及其字段都必须记录。

上图中,R1、R2 等表示实体类型,也叫做结点,每个实体类型可包含若干个属性,也叫做字段。R1 结点和 R2 结点之间的关系叫做实体间联系。R1 结点叫做根结点,R2 结点和 R3 结点叫做 R1 结点的子节点。R1 结点叫做 R2 结点的双亲结点。没有子结点的结点也叫做叶结点,如 R3 、R4和 R5。
以学校某个系的组织结构为例:

-
实体系是根结点,由系编号和系名2个属性(字段)组成。它有两个子结点,分别是教研室实体和学生实体。
-
实体教研室是系的子结点,它由教研室编号和教研室名2个属性(字段)组成。
-
实体学生是系的子结点,它由学号、姓名和成绩这3个属性(字段)组成,由于它没有子结点,所以也叫叶结点。
-
实体教师是教研室的子结点,它由教师编号、教师姓名和研究方向组成,由于它没有子结点,所以也叫叶结点。
层次模型的数据操纵与完整性约束
-
数据操纵
层次模型的数据操纵主要有查询、插入、删除和更新,进行插入、删除、更新操作时要满足其完整性约束条件。
-
无相应的双亲结点值就不能插入子女结点值
-
如果删除双亲结点值,则相应的子女结点值也被同时删除
-
更新操作时,应更新所有相应记录,以保证数据的一致性
-
完整性约束
-
数据及其联系所具有的制约和依赖规则
-
保证数据库中数据的正确性、有效性和相容性
-
通过指针维护父子关系
层次模型优缺点
-
优点
-
层次模型的数据结构比较简单清晰
-
查询效率高,性能优于关系模型,不低于网状模型
-
层次数据模型提供了良好的完整性支持
-
缺点
-
结点之间的多对多联系表示不自然
-
对插入和删除操作的限制多,应用程序的编写比较复杂
-
查询子女结点必须通过双亲结点
-
层次命令趋于程序化
层次模型转化为关系模型
关系模型是现在数据库的主流模型,要想把层次模型转化为关系模型,只需把层次模型中的各个实体通过外键关联即可。
现有一个层次模型如下:

该层次模型有三个实体,分别是系、教研室和学生。我们可以把它转化为如下图的关系模型:
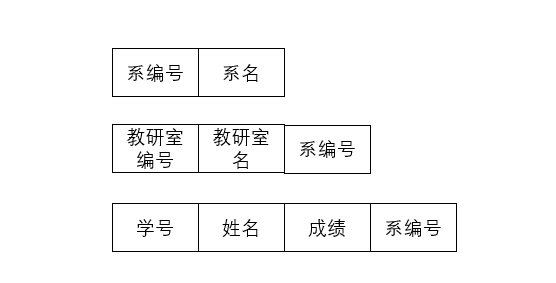
可以看出转化为关系模型后,依旧有3个实体,各实体之间通过系编号这一属性形成关联,这一属性体现在建表语句中就是添加外键。
编程要求
编写 SQL 语句,将指定的层次模型转换为相应的关系模型后创建表并插入数据。具体要求如下:
- 层次模型图

将学生表命名为 student,教研室表命名为 edu,院系表命名为 dept,职工表命名为 emp。其中表中字段解释如下:
| 字段名 | 建表用字段名 |
|---|---|
| 系号 | dept_id |
| 系名 | dept_name |
| 地址 | addr |
| 教研室号 | edu_id |
| 教研室名 | edu_name |
| 学号 | student_id |
| 姓名 | student_name |
| 年级 | level_class |
| 职工号 | emp_id |
| 姓名 | emp_name |
| 职称 | title |
注意:创表时外键字段名和主键字段名一致
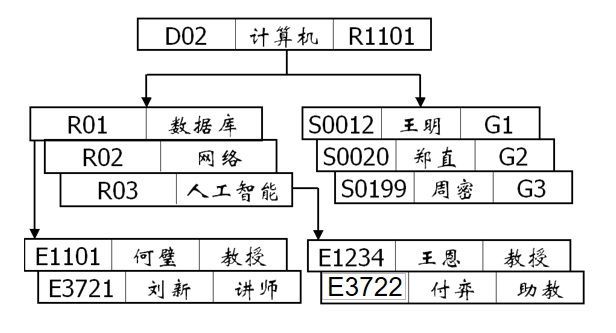
插入数据如下图:
头歌实验代码
#请在此添加实现代码########## Begin ###########在mydb库中创建表并插入数据CREATE TABLE dept ( dept_id CHAR (3) PRIMARY KEY, dept_name VARCHAR (20) NOT NULL, addr VARCHAR (100));CREATE TABLE edu ( edu_id CHAR (3) PRIMARY KEY, edu_name VARCHAR (20), dept_id CHAR (3), FOREIGN KEY (dept_id) REFERENCES dept (dept_id));CREATE TABLE student ( student_id CHAR (10) PRIMARY KEY, student_name VARCHAR (10), level_class CHAR (3), dept_id CHAR (3), FOREIGN KEY (dept_id) REFERENCES dept (dept_id));CREATE TABLE emp ( emp_id CHAR (10) PRIMARY KEY, emp_name VARCHAR (10), title VARCHAR (10), edu_id CHAR (3), dept_id CHAR (3), FOREIGN KEY (edu_id) REFERENCES edu (edu_id), FOREIGN KEY (dept_id) REFERENCES dept (dept_id));INSERT INTO dept VALUES ('D02', '计算机', 'R1101');INSERT INTO edu VALUES ('R01', '数据库', 'D02'), ('R02', '网络', 'D02'), ('R03', '人工智能', 'D02');INSERT INTO student VALUES ('S0012', '王明','G1','D02'),('S0020', '郑直','G2', 'D02'), ('S0199', '周密','G3', 'D02');INSERT INTO emp VALUES ('E1101', '何璧','教授','R01', 'D02'), ('E3721', '刘新','讲师','R01', 'D02'), ('E1234', '王思','教授','R03', 'D02'), ('E3722', '付弈','助教','R03', 'D02');########## End ##########第3关 网状模型
网状数据库模型
对于层次和非层次结构的事物都能比较自然的模拟,在关系数据库出现之前网状 DBMS (数据库任务组)要比层次 DBMS 用得普遍。
网状型数据模型
用有向图表示实体和实体间联系的数据结构模型称为网状数据模型。
网状模型是一种比层次模型更具普遍性的结构。满足下面两个条件的基本层次联系的集合称为网状数据模型:①允许一个以上的结点无双亲;②一个结点可以有多于一个的双亲。
下图即是一个简单的网状模型例子:

层次模型中子女结点与双亲结点的联系是唯一的,而在网状模型中,这种关系可以不唯一。因此节点之间的对应也就是 m:n 的关系,从而克服了层次状数据模型的缺点。
下面以学生和课程之间的关系为例:

以课程和学生之间的关系来说,他们是一种 m:n 的关系,也就是说一个学生能够选修多门课程,一门课程也可以被多个学生同时选修。
网状模型的数据操纵与完整性约束
-
数据操作
主要包括查询、插入、删除和更新。具体如下:
-
进行插入操作时,允许插入尚未确定双亲结点值的子结点值。如可增加一名尚未分配到某个教研室的新老师,也可增加一些刚来报到还未分配宿舍的学生。
-
进行删除操作时,允许只删除双亲结点值。如可删除一个教研室,而该科研室所有教师的信息仍保留在数据库中。
-
修改数据时,可直接表示非树状结构,而无须像层次模型那样增加冗余结点,因此修改操作时只需要指定更新记录即可。
-
进行更新操作时只需更新指定记录即可。
-
完整性约束条件
一般来说,网状模型没有层次模型那样严格的完整性约束条件,但具体的网状数据库系统(如 DBTG)对数据操作都加了一些限制,提供了一定的完整性约束。DBTG 在模式 DDL 中提供了定义 DBTG 数据库完整性的若干概念和语句,主要有:
-
支持记录码的概念,码是唯一标识记录的数据项的集合。
-
保证一个联系中双亲记录和子记录之间是一对多的联系。
-
可以支持双亲记录和子记录之间某些约束条件。如有些子记录要求双亲记录存在才能插入,双亲记录删除时也连同删除。
网状模型优缺点
-
优点
-
网状数据模型可以很方便的表示现实世界中的很多复杂的关系。
-
修改网状数据模型时,没有层次状数据模型的那么多的严格限制,可以删除一个节点的父节点而依旧保留该节点;也允许插入一个没有任何父节点的节点,这样的插入在层次状数据模型中是不被允许的,除非是首先插入的是根节点。
-
实体之间的关系在底层中可以借由指针指针实现,因此在这种数据库中的执行操作的效率较高。
-
缺点
-
网状数据模型的结构复杂,使用不易,随着应用环境的扩大,数据结构越来越复杂,数据的插入、删除牵动的相关数据太多,不利于数据库的维护和重建。
-
网状数据模型数据之间的彼此关联比较大,该模型其实一种导航式的数据模型结构,不仅要说明要对数据做些什么,还说明操作的记录的路径。
-
DDL、DML语言复杂,用户不容易使用。
-
记录之间联系是通过存取路径实现的,用户必须了解系统结构的细节。
网状模型与层次模型
网状模型与层次模型之间的区别:
-
网状模型允许多个结点没有双亲结点
-
网状模型允许结点有多个双亲结点
-
网状模型允许两个结点之间有多种联系(复合联系)
-
网状模型可以更直接地描述现实世界
-
层次模型实际上是网状模型的一个特例
网状模型转化为关系模型
网状模型转化成关系模型只需将其网状模型节点之间指针描述的联系在关系模型中使用外键描述即可。
仍使用上面示例中学生和课程间联系的网状模型,我们将它转化为关系模型后如下图:

编程要求
编写 SQL 语句,将指定的网状模型转换为相应的关系模型后创建表,并向表中插入数据。具体要求如下:
- 网状模型图

将学生表命名为 t_student,课程表命名为 t_course,关系表命名为 t_relation,表种各字段如下:
| 字段名称 | 备注 | 类型 |
|---|---|---|
| s_id | 学号 | varchar(32) |
| s_name | 学生姓名 | varchar(32) |
| s_class | 年级 | varchar(32) |
| c_id | 课程号 | varchar(32) |
| c_name | 课程名 | varchar(32) |
| c_creadit | 学分 | int(3) |
| grade | 成绩 | varchar(32) |
学生信息和课程信息如下:
| s_id | s_name | s_class |
|---|---|---|
| S1 | 张乐 | 大一 |
| S2 | 王冲 | 大二 |
| S3 | 翠花 | 大一 |
| c_id | c_name | c_creadit |
|---|---|---|
| C1 | 数据库 | 45 |
| C2 | python | 30 |
t_relation 表的插入数据如下图:

头歌实验代码
#请在此添加实现代码########## Begin ##########CREATE TABLE t_student ( s_id VARCHAR(32) NOT NULL, s_name VARCHAR(32) NOT NULL, s_class VARCHAR(32), PRIMARY KEY (s_id));CREATE TABLE t_course ( c_id VARCHAR(32) NOT NULL, c_name VARCHAR(32) NOT NULL, c_creadit INT(3), PRIMARY KEY (c_id));CREATE TABLE t_relation ( s_id VARCHAR(32) NOT NULL, c_id VARCHAR(32) NOT NULL, grade VARCHAR(32) NOT NULL, CONSTRAINT fk_1 FOREIGN KEY t_relation(s_id) REFERENCES t_student(s_id), CONSTRAINT fk_2 FOREIGN KEY t_relation(c_id) REFERENCES t_course(c_id));INSERT INTO t_student VALUES("S1","张乐","大一"),("S2","王冲","大二"),("S3","翠花","大一");INSERT INTO t_course VALUES("C1","数据库",45),("C2","python",30);INSERT INTO t_relation VALUES("S1","C1","A"), ("S1","C2","A"), ("S2","C1","B"), ("S2","C2","A-"), ("S3","C1","C");########## End ##########来源地址:https://blog.csdn.net/weixin_51970555/article/details/127197896














