
跨域问题在之前的单体架构开发中,其实是比较少见的问题,除非是需要接入第三方SDK时,才需要处理此问题。但随着现在前后端分离、分布式架构的流行,跨域问题也成为了每个Java开发必须要懂得解决的一个问题。
跨域问题产生的原因
产生跨域问题的主要原因就在于同源策略,为了保证用户信息安全,防止恶意网站窃取数据,同源策略是必须的,否则cookie可以共享。由于http无状态协议通常会借助cookie来实现有状态的信息记录,例如用户的身份/密码等,因此一旦cookie被共享,那么会导致用户的身份信息被盗取。
同源策略主要是指三点相同,协议+域名+端口 相同的两个请求,则可以被看做是同源的,但如果其中任意一点存在不同,则代表是两个不同源的请求,同源策略会限制了不同源之间的资源交互。
Nginx解决跨域问题
弄明白了跨域问题的产生原因,接下来看看Nginx中又该如何解决跨域呢?其实比较简单,在nginx.conf中稍微添加一点配置即可:
location / { # 允许跨域的请求,可以自定义变量$http_origin,*表示所有 add_header 'Access-Control-Allow-Origin' *; # 允许携带cookie请求 add_header 'Access-Control-Allow-Credentials' 'true'; # 允许跨域请求的方法:GET,POST,OPTIONS,PUT add_header 'Access-Control-Allow-Methods' 'GET,POST,OPTIONS,PUT'; # 允许请求时携带的头部信息,*表示所有 add_header 'Access-Control-Allow-Headers' *; # 允许发送按段获取资源的请求 add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range'; # 一定要有!!!否则Post请求无法进行跨域! # 在发送Post跨域请求前,会以Options方式发送预检请求,服务器接受时才会正式请求 if ($request_method = 'OPTIONS') { add_header 'Access-Control-Max-Age' 1728000; add_header 'Content-Type' 'text/plain; charset=utf-8'; add_header 'Content-Length' 0; # 对于Options方式的请求返回204,表示接受跨域请求 return 204; }}复制代码在nginx.conf文件加上如上配置后,跨域请求即可生效了。
但如果后端是采用分布式架构开发的,有时候RPC调用也需要解决跨域问题,不然也同样会出现无法跨域请求的异常,因此可以在你的后端项目中,通过继承
HandlerInterceptorAdapter类、实现WebMvcConfigurer接口、添加@CrossOrgin注解的方式实现接口之间的跨域配置。
十、Nginx防盗链设计
作者:竹子爱熊猫
链接:https://juejin.cn/post/7112826654291918855
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在nginx.conf文件加上如上配置后,跨域请求即可生效了。
但如果后端是采用分布式架构开发的,有时候RPC调用也需要解决跨域问题,不然也同样会出现无法跨域请求的异常,因此可以在你的后端项目中,通过继承
HandlerInterceptorAdapter类、实现WebMvcConfigurer接口、添加@CrossOrgin注解的方式实现接口之间的跨域配置。
十、Nginx防盗链设计
首先了解一下何谓盗链:盗链即是指外部网站引入当前网站的资源对外展示,来举个简单的例子理解:
好比壁纸网站
X站、Y站,X站是一点点去购买版权、签约作者的方式,从而积累了海量的壁纸素材,但Y站由于资金等各方面的原因,就直接通过这种方式照搬了X站的所有壁纸资源,继而提供给用户下载。

那么如果我们自己是这个X站的Boss,心中必然不爽,那么此时又该如何屏蔽这类问题呢?那么接下来要叙说的防盗链 登场了!
Nginx的防盗链机制实现,跟上篇文章《HTTP/HTTPS》中分析到的一个头部字段:Referer有关,该字段主要描述了当前请求是从哪儿发出的,那么在Nginx中就可获取该值,然后判断是否为本站的资源引用请求,如果不是则不允许访问。Nginx中存在一个配置项为valid_referers,正好可以满足前面的需求,语法如下:
valid_referers none | blocked | server_names | string ...;none:表示接受没有Referer字段的HTTP请求访问。blocked:表示允许http://或https//以外的请求访问。server_names:资源的白名单,这里可以指定允许访问的域名。string:可自定义字符串,支配通配符、正则表达式写法。
简单了解语法后,接下来的实现如下:
# 在动静分离的location中开启防盗链机制location ~ .*\.(html|htm|gif|jpg|jpeg|bmp|png|ico|txt|js|css){ # 最后面的值在上线前可配置为允许的域名地址 valid_referers blocked 192.168.12.129; if ($invalid_referer) { # 可以配置成返回一张禁止盗取的图片 # rewrite ^/ http://xx.xx.com/NO.jpg; # 也可直接返回403 return 403; } root /soft/nginx/static_resources; expires 7d;}复制代码根据上述中的内容配置后,就已经通过Nginx实现了最基本的防盗链机制,最后只需要额外重启一下就好啦!当然,对于防盗链机制实现这块,也有专门的第三方模块ngx_http_accesskey_module实现了更为完善的设计,感兴趣的小伙伴可以自行去看看。
PS:防盗链机制也无法解决爬虫伪造
referers信息的这种方式抓取数据。
十一、Nginx大文件传输配置
在某些业务场景中需要传输一些大文件,但大文件传输时往往都会会出现一些Bug,比如文件超出限制、文件传输过程中请求超时等,那么此时就可以在Nginx稍微做一些配置,先来了解一些关于大文件传输时可能会用的配置项:
| 配置项 | 释义 |
|---|---|
client_max_body_size | 设置请求体允许的最大体积 |
client_header_timeout | 等待客户端发送一个请求头的超时时间 |
client_body_timeout | 设置读取请求体的超时时间 |
proxy_read_timeout | 设置请求被后端服务器读取时,Nginx等待的最长时间 |
proxy_send_timeout | 设置后端向Nginx返回响应时的超时时间 |
在传输大文件时,client_max_body_size、client_header_timeout、proxy_read_timeout、proxy_send_timeout这四个参数值都可以根据自己项目的实际情况来配置。
上述配置仅是作为代理层需要配置的,因为最终客户端传输文件还是直接与后端进行交互,这里只是把作为网关层的
Nginx配置调高一点,调到能够“容纳大文件”传输的程度。
当然,Nginx中也可以作为文件服务器使用,但需要用到一个专门的第三方模块nginx-upload-module,如果项目中文件上传的作用处不多,那么建议可以通过Nginx搭建,毕竟可以节省一台文件服务器资源。但如若文件上传/下载较为频繁,那么还是建议额外搭建文件服务器,并将上传/下载功能交由后端处理。
十二、Nginx配置SSL证书
随着越来越多的网站接入HTTPS,因此Nginx中仅配置HTTP还不够,往往还需要监听443端口的请求,但在上篇《HTTP/HTTPS》中谈到过,HTTPS为了确保通信安全,所以服务端需配置对应的数字证书,当项目使用Nginx作为网关时,那么证书在Nginx中也需要配置,接下来简单聊一下关于SSL证书配置过程:
- ①先去CA机构或从云控制台中申请对应的
SSL证书,审核通过后下载Nginx版本的证书。 - ②下载数字证书后,完整的文件总共有三个:
.crt、.key、.pem:.crt:数字证书文件,.crt是.pem的拓展文件,因此有些人下载后可能没有。.key:服务器的私钥文件,及非对称加密的私钥,用于解密公钥传输的数据。.pem:Base64-encoded编码格式的源证书文本文件,可自行根需求修改拓展名。
- ③在
Nginx目录下新建certificate目录,并将下载好的证书/私钥等文件上传至该目录。 - ④最后修改一下
nginx.conf文件即可,如下:
# ----------HTTPS配置-----------server { # 监听HTTPS默认的443端口 listen 443; # 配置自己项目的域名 server_name www.xxx.com; # 打开SSL加密传输 ssl on; # 输入域名后,首页文件所在的目录 root html; # 配置首页的文件名 index index.html index.htm index.jsp index.ftl; # 配置自己下载的数字证书 ssl_certificate certificate/xxx.pem; # 配置自己下载的服务器私钥 ssl_certificate_key certificate/xxx.key; # 停止通信时,加密会话的有效期,在该时间段内不需要重新交换密钥 ssl_session_timeout 5m; # TLS握手时,服务器采用的密码套件 ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4; # 服务器支持的TLS版本 ssl_protocols TLSv1 TLSv1.1 TLSv1.2; # 开启由服务器决定采用的密码套件 ssl_prefer_server_ciphers on; location / { .... }}# ---------HTTP请求转HTTPS-------------server { # 监听HTTP默认的80端口 listen 80; # 如果80端口出现访问该域名的请求 server_name www.xxx.com; # 将请求改写为HTTPS(这里写你配置了HTTPS的域名) rewrite ^(.*)$ https://www.xxx.com;}复制代码OK~,根据如上配置了Nginx后,你的网站即可通过https://的方式访问,并且当客户端使用http://的方式访问时,会自动将其改写为HTTPS请求。
十三、Nginx的高可用
线上如果采用单个节点的方式部署Nginx,难免会出现天灾人祸,比如系统异常、程序宕机、服务器断电、机房爆炸、地球毁灭....哈哈哈,夸张了。但实际生产环境中确实存在隐患问题,由于Nginx作为整个系统的网关层接入外部流量,所以一旦Nginx宕机,最终就会导致整个系统不可用,这无疑对于用户的体验感是极差的,因此也得保障Nginx高可用的特性。
接下来则会通过
keepalived的VIP机制,实现Nginx的高可用。VIP并不是只会员的意思,而是指Virtual IP,即虚拟IP。
keepalived在之前单体架构开发时,是一个用的较为频繁的高可用技术,比如MySQL、Redis、MQ、Proxy、Tomcat等各处都会通过keepalived提供的VIP机制,实现单节点应用的高可用。
Keepalived+重启脚本+双机热备搭建
①首先创建一个对应的目录并下载keepalived安装包(提取码:s6aq)到Linux中并解压:
[root@localhost]# mkdir /soft/keepalived && cd /soft/keepalived[root@localhost]# wget https://www.keepalived.org/software/keepalived-2.2.4.tar.gz[root@localhost]# tar -zxvf keepalived-2.2.4.tar.gz复制代码②进入解压后的keepalived目录并构建安装环境,然后编译并安装:
[root@localhost]# cd keepalived-2.2.4[root@localhost]# ./configure --prefix=/soft/keepalived/[root@localhost]# make && make install复制代码③进入安装目录的/soft/keepalived/etc/keepalived/并编辑配置文件:
[root@localhost]# cd /soft/keepalived/etc/keepalived/[root@localhost]# vi keepalived.conf复制代码④编辑主机的keepalived.conf核心配置文件,如下:
global_defs { # 自带的邮件提醒服务,建议用独立的监控或第三方SMTP,也可选择配置邮件发送。 notification_email { root@localhost } notification_email_from root@localhost smtp_server localhost smtp_connect_timeout 30 # 高可用集群主机身份标识(集群中主机身份标识名称不能重复,建议配置成本机IP)router_id 192.168.12.129 }# 定时运行的脚本文件配置vrrp_script check_nginx_pid_restart { # 之前编写的nginx重启脚本的所在位置script "/soft/scripts/keepalived/check_nginx_pid_restart.sh" # 每间隔3秒执行一次interval 3 # 如果脚本中的条件成立,重启一次则权重-20weight -20}# 定义虚拟路由,VI_1为虚拟路由的标示符(可自定义名称)vrrp_instance VI_1 { # 当前节点的身份标识:用来决定主从(MASTER为主机,BACKUP为从机)state MASTER # 绑定虚拟IP的网络接口,根据自己的机器的网卡配置interface ens33 # 虚拟路由的ID号,主从两个节点设置必须一样virtual_router_id 121 # 填写本机IPmcast_src_ip 192.168.12.129 # 节点权重优先级,主节点要比从节点优先级高priority 100 # 优先级高的设置nopreempt,解决异常恢复后再次抢占造成的脑裂问题nopreempt # 组播信息发送间隔,两个节点设置必须一样,默认1s(类似于心跳检测)advert_int 1 authentication { auth_type PASS auth_pass 1111 } # 将track_script块加入instance配置块 track_script { # 执行Nginx监控的脚本check_nginx_pid_restart } virtual_ipaddress { # 虚拟IP(VIP),也可扩展,可配置多个。192.168.12.111 }}复制代码⑤克隆一台之前的虚拟机作为从(备)机,编辑从机的keepalived.conf文件,如下:
global_defs { # 自带的邮件提醒服务,建议用独立的监控或第三方SMTP,也可选择配置邮件发送。 notification_email { root@localhost } notification_email_from root@localhost smtp_server localhost smtp_connect_timeout 30 # 高可用集群主机身份标识(集群中主机身份标识名称不能重复,建议配置成本机IP)router_id 192.168.12.130 }# 定时运行的脚本文件配置vrrp_script check_nginx_pid_restart { # 之前编写的nginx重启脚本的所在位置script "/soft/scripts/keepalived/check_nginx_pid_restart.sh" # 每间隔3秒执行一次interval 3 # 如果脚本中的条件成立,重启一次则权重-20weight -20}# 定义虚拟路由,VI_1为虚拟路由的标示符(可自定义名称)vrrp_instance VI_1 { # 当前节点的身份标识:用来决定主从(MASTER为主机,BACKUP为从机)state BACKUP # 绑定虚拟IP的网络接口,根据自己的机器的网卡配置interface ens33 # 虚拟路由的ID号,主从两个节点设置必须一样virtual_router_id 121 # 填写本机IPmcast_src_ip 192.168.12.130 # 节点权重优先级,主节点要比从节点优先级高priority 90 # 优先级高的设置nopreempt,解决异常恢复后再次抢占造成的脑裂问题nopreempt # 组播信息发送间隔,两个节点设置必须一样,默认1s(类似于心跳检测)advert_int 1 authentication { auth_type PASS auth_pass 1111 } # 将track_script块加入instance配置块 track_script { # 执行Nginx监控的脚本check_nginx_pid_restart } virtual_ipaddress { # 虚拟IP(VIP),也可扩展,可配置多个。192.168.12.111 }}复制代码⑥新建scripts目录并编写Nginx的重启脚本,check_nginx_pid_restart.sh:
[root@localhost]# mkdir /soft/scripts /soft/scripts/keepalived[root@localhost]# touch /soft/scripts/keepalived/check_nginx_pid_restart.sh[root@localhost]# vi /soft/scripts/keepalived/check_nginx_pid_restart.sh#!/bin/sh# 通过ps指令查询后台的nginx进程数,并将其保存在变量nginx_number中nginx_number=`ps -C nginx --no-header | wc -l`# 判断后台是否还有Nginx进程在运行if [ $nginx_number -eq 0 ];then # 如果后台查询不到`Nginx`进程存在,则执行重启指令 /soft/nginx/sbin/nginx -c /soft/nginx/conf/nginx.conf # 重启后等待1s后,再次查询后台进程数 sleep 1 # 如果重启后依旧无法查询到nginx进程 if [ `ps -C nginx --no-header | wc -l` -eq 0 ];then # 将keepalived主机下线,将虚拟IP漂移给从机,从机上线接管Nginx服务 systemctl stop keepalived.service fifi复制代码⑦编写的脚本文件需要更改编码格式,并赋予执行权限,否则可能执行失败:
[root@localhost]# vi /soft/scripts/keepalived/check_nginx_pid_restart.sh:set fileformat=unix # 在vi命令里面执行,修改编码格式:set ff # 查看修改后的编码格式[root@localhost]# chmod +x /soft/scripts/keepalived/check_nginx_pid_restart.sh复制代码⑧由于安装keepalived时,是自定义的安装位置,因此需要拷贝一些文件到系统目录中:
[root@localhost]# mkdir /etc/keepalived/[root@localhost]# cp /soft/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/[root@localhost]# cp /soft/keepalived/keepalived-2.2.4/keepalived/etc/init.d/keepalived /etc/init.d/[root@localhost]# cp /soft/keepalived/etc/sysconfig/keepalived /etc/sysconfig/复制代码⑨将keepalived加入系统服务并设置开启自启动,然后测试启动是否正常:
[root@localhost]# chkconfig keepalived on[root@localhost]# systemctl daemon-reload[root@localhost]# systemctl enable keepalived.service[root@localhost]# systemctl start keepalived.service其他命令:systemctl disable keepalived.service # 禁止开机自动启动systemctl restart keepalived.service # 重启keepalivedsystemctl stop keepalived.service # 停止keepalivedtail -f /var/log/messages # 查看keepalived运行时日志复制代码⑩最后测试一下VIP是否生效,通过查看本机是否成功挂载虚拟IP:
[root@localhost]# ip addr复制代码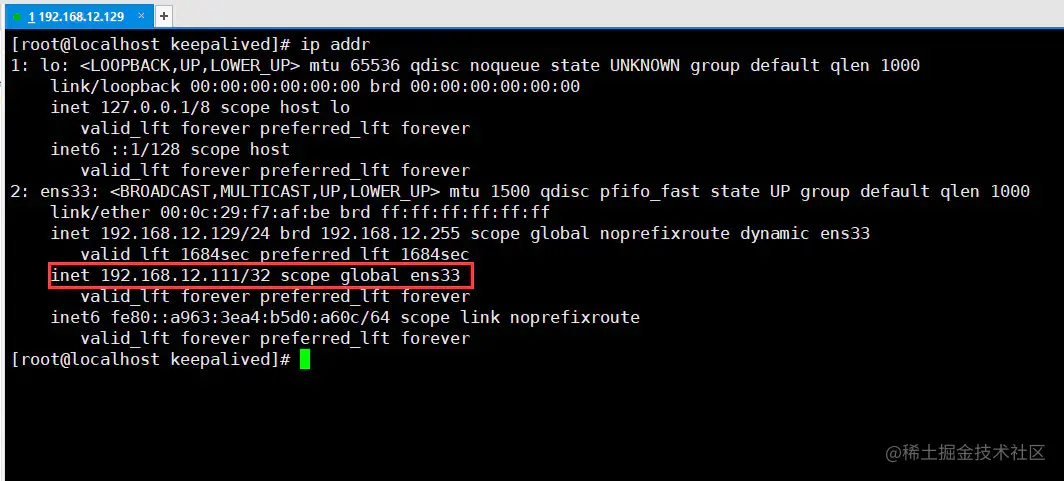
从上图中可以明显看见虚拟
IP已经成功挂载,但另外一台机器192.168.12.130并不会挂载这个虚拟IP,只有当主机下线后,作为从机的192.168.12.130才会上线,接替VIP。最后测试一下外网是否可以正常与VIP通信,即在Windows中直接ping VIP:
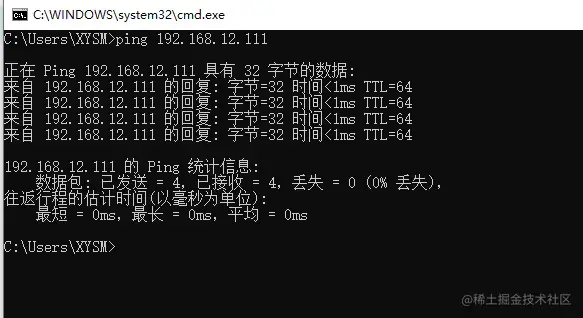
外部通过VIP通信时,也可以正常Ping通,代表虚拟IP配置成功。
Nginx高可用性测试
经过上述步骤后,keepalived的VIP机制已经搭建成功,在上个阶段中主要做了几件事:
- 一、为部署
Nginx的机器挂载了VIP。 - 二、通过
keepalived搭建了主从双机热备。 - 三、通过
keepalived实现了Nginx宕机重启。
由于前面没有域名的原因,因此最初server_name配置的是当前机器的IP,所以需稍微更改一下nginx.conf的配置:
sever{ listen 80; # 这里从机器的本地IP改为虚拟IPserver_name 192.168.12.111;# 如果这里配置的是域名,那么则将域名的映射配置改为虚拟IP}复制代码最后来实验一下效果:
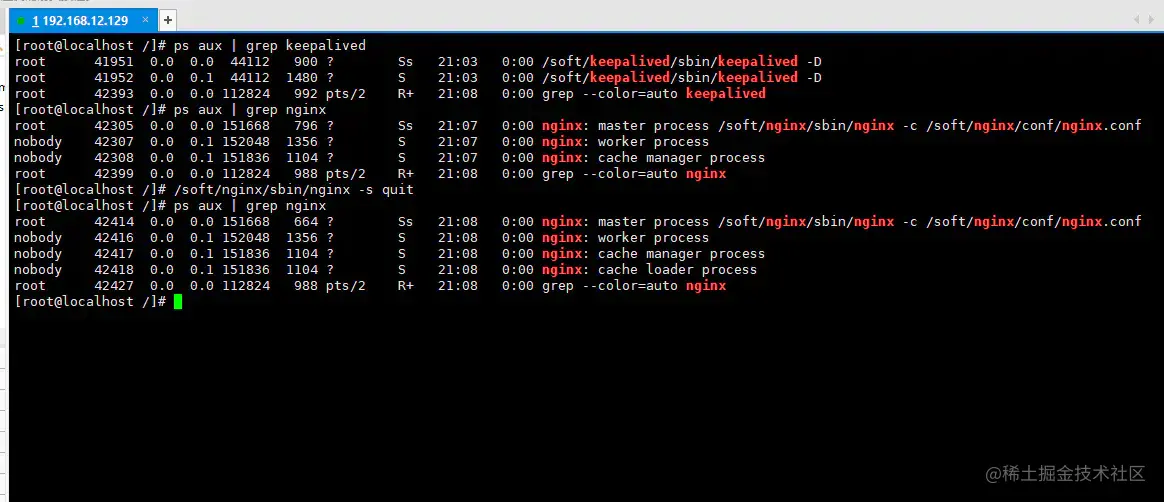
在上述过程中,首先分别启动了
keepalived、nginx服务,然后通过手动停止nginx的方式模拟了Nginx宕机情况,过了片刻后再次查询后台进程,我们会发现nginx依旧存活。
从这个过程中不难发现,keepalived已经为我们实现了Nginx宕机后自动重启的功能,那么接着再模拟一下服务器出现故障时的情况:
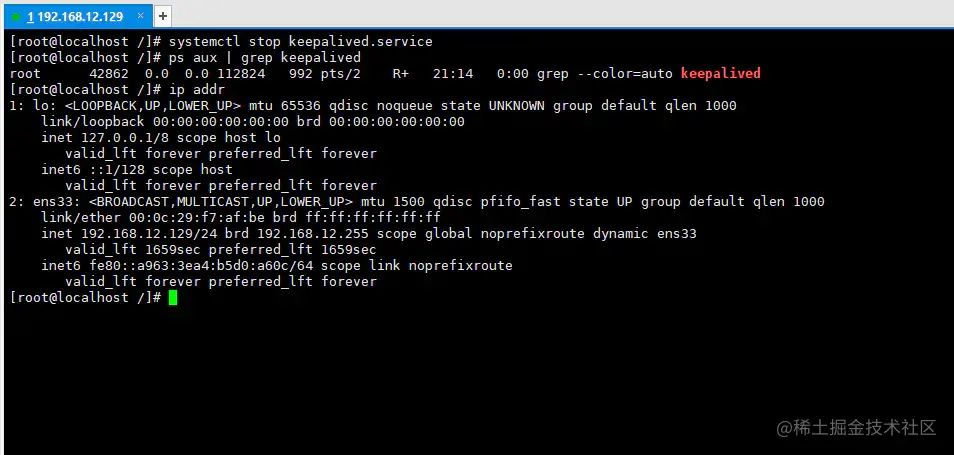
在上述过程中,我们通过手动关闭
keepalived服务模拟了机器断电、硬件损坏等情况(因为机器断电等情况=主机中的keepalived进程消失),然后再次查询了一下本机的IP信息,很明显会看到VIP消失了!
现在再切换到另外一台机器:192.168.12.130来看看情况:
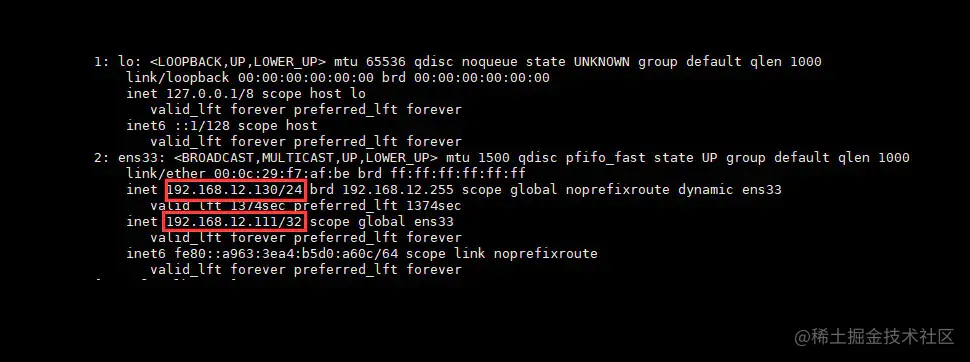
此刻我们会发现,在主机
192.168.12.129宕机后,VIP自动从主机飘移到了从机192.168.12.130上,而此时客户端的请求就最终会来到130这台机器的Nginx上。
最终,利用Keepalived对Nginx做了主从热备之后,无论是遇到线上宕机还是机房断电等各类故障时,都能够确保应用系统能够为用户提供7x24小时服务。
十四、Nginx性能优化
到这里文章的篇幅较长了,最后再来聊一下关于Nginx的性能优化,主要就简单说说收益最高的几个优化项,在这块就不再展开叙述了,毕竟影响性能都有多方面原因导致的,比如网络、服务器硬件、操作系统、后端服务、程序自身、数据库服务等,对于性能调优比较感兴趣的可以参考之前《JVM性能调优》中的调优思想。
优化一:打开长连接配置
通常Nginx作为代理服务,负责分发客户端的请求,那么建议开启HTTP长连接,用户减少握手的次数,降低服务器损耗,具体如下:
upstream xxx { # 长连接数 keepalive 32; # 每个长连接提供的最大请求数 keepalived_requests 100; # 每个长连接没有新的请求时,保持的最长时间 keepalive_timeout 60s;}复制代码优化二、开启零拷贝技术
零拷贝这个概念,在大多数性能较为不错的中间件中都有出现,例如Kafka、Netty等,而Nginx中也可以配置数据零拷贝技术,如下:
sendfile on; # 开启零拷贝机制复制代码零拷贝读取机制与传统资源读取机制的区别:
- 传统方式:硬件-->内核-->用户空间-->程序空间-->程序内核空间-->网络套接字
- 零拷贝方式:硬件-->内核-->程序内核空间-->网络套接字
从上述这个过程对比,很轻易就能看出两者之间的性能区别。
优化三、开启无延迟或多包共发机制
在Nginx中有两个较为关键的性能参数,即tcp_nodelay、tcp_nopush,开启方式如下:
tcp_nodelay on;tcp_nopush on;复制代码TCP/IP协议中默认是采用了Nagle算法的,即在网络数据传输过程中,每个数据报文并不会立马发送出去,而是会等待一段时间,将后面的几个数据包一起组合成一个数据报文发送,但这个算法虽然提高了网络吞吐量,但是实时性却降低了。
因此你的项目属于交互性很强的应用,那么可以手动开启
tcp_nodelay配置,让应用程序向内核递交的每个数据包都会立即发送出去。但这样会产生大量的TCP报文头,增加很大的网络开销。
相反,有些项目的业务对数据的实时性要求并不高,追求的则是更高的吞吐,那么则可以开启tcp_nopush配置项,这个配置就类似于“塞子”的意思,首先将连接塞住,使得数据先不发出去,等到拔去塞子后再发出去。设置该选项后,内核会尽量把小数据包拼接成一个大的数据包(一个MTU)再发送出去.
当然若一定时间后(一般为
200ms),内核仍然没有积累到一个MTU的量时,也必须发送现有的数据,否则会一直阻塞。
tcp_nodelay、tcp_nopush两个参数是“互斥”的,如果追求响应速度的应用推荐开启tcp_nodelay参数,如IM、金融等类型的项目。如果追求吞吐量的应用则建议开启tcp_nopush参数,如调度系统、报表系统等。
注意:
①tcp_nodelay一般要建立在开启了长连接模式的情况下使用。
②tcp_nopush参数是必须要开启sendfile参数才可使用的。
优化四、调整Worker工作进程
Nginx启动后默认只会开启一个Worker工作进程处理客户端请求,而我们可以根据机器的CPU核数开启对应数量的工作进程,以此来提升整体的并发量支持,如下:
# 自动根据CPU核心数调整Worker进程数量worker_processes auto;复制代码工作进程的数量最高开到
8个就OK了,8个之后就不会有再大的性能提升。
同时也可以稍微调整一下每个工作进程能够打开的文件句柄数:
# 每个Worker能打开的文件描述符,最少调整至1W以上,负荷较高建议2-3Wworker_rlimit_nofile 20000;复制代码操作系统内核(
kernel)都是利用文件描述符来访问文件,无论是打开、新建、读取、写入文件时,都需要使用文件描述符来指定待操作的文件,因此该值越大,代表一个进程能够操作的文件越多(但不能超出内核限制,最多建议3.8W左右为上限)。
优化五、开启CPU亲和机制
对于并发编程较为熟悉的伙伴都知道,因为进程/线程数往往都会远超出系统CPU的核心数,因为操作系统执行的原理本质上是采用时间片切换机制,也就是一个CPU核心会在多个进程之间不断频繁切换,造成很大的性能损耗。
而CPU亲和机制则是指将每个Nginx的工作进程,绑定在固定的CPU核心上,从而减小CPU切换带来的时间开销和资源损耗,开启方式如下:
worker_cpu_affinity auto;复制代码优化六、开启epoll模型及调整并发连接数
在最开始就提到过:Nginx、Redis都是基于多路复用模型去实现的程序,但最初版的多路复用模型select/poll最大只能监听1024个连接,而epoll则属于select/poll接口的增强版,因此采用该模型能够大程度上提升单个Worker的性能,如下:
events { # 使用epoll网络模型 use epoll; # 调整每个Worker能够处理的连接数上限 worker_connections 10240;}复制代码这里对于
select/poll/epoll模型就不展开细说了,后面的IO模型文章中会详细剖析。
十五、放在最后的结尾
至此,Nginx的大部分内容都已阐述完毕,关于最后一小节的性能优化内容,其实在前面就谈到的动静分离、分配缓冲区、资源缓存、防盗链、资源压缩等内容,也都可归纳为性能优化的方案。
来源地址:https://blog.csdn.net/weixin_37855495/article/details/130082400








