
最常见的方式就是为字段设置主键或唯一索引,当插入重复数据时,抛出错误,程序终止,但这会给后续处理带来麻烦,因此需要对插入语句做特殊处理,尽量避开或忽略异常,下面我介绍4种方法:
- insert ignore into
- on duplicate key update
- replace into
- insert if not exists
下面我来演示一下:
1 准备工作
我新建了一个users表,其中主键为id(自增),同时对username字段设置了唯一索引:
Create table users(id INT NOT NULL AUTO_INCREMENT,username VARCHAR(15) NOT NULL,address VARCHAR(30),PRIMARY KEY(id),UNIQUE KEY idx_username(username)) engine = InnoDB1.1 insert ignore into
即插入数据时,如果数据存在,则忽略此次插入,该方法有前提条件:插入的数据字段设置了主键或唯一索引。
测试SQL语句如下:
insert ignore into users(username,address) values("handsome","wuhan")当插入本条数据时,MySQL数据库会首先检索已有数据(也就是idx_username索引),如果存在,则忽略本次插入,如果不存在,则正常插入数据。
第一次执行如下:
由于数据表中没有数据,插入成功。
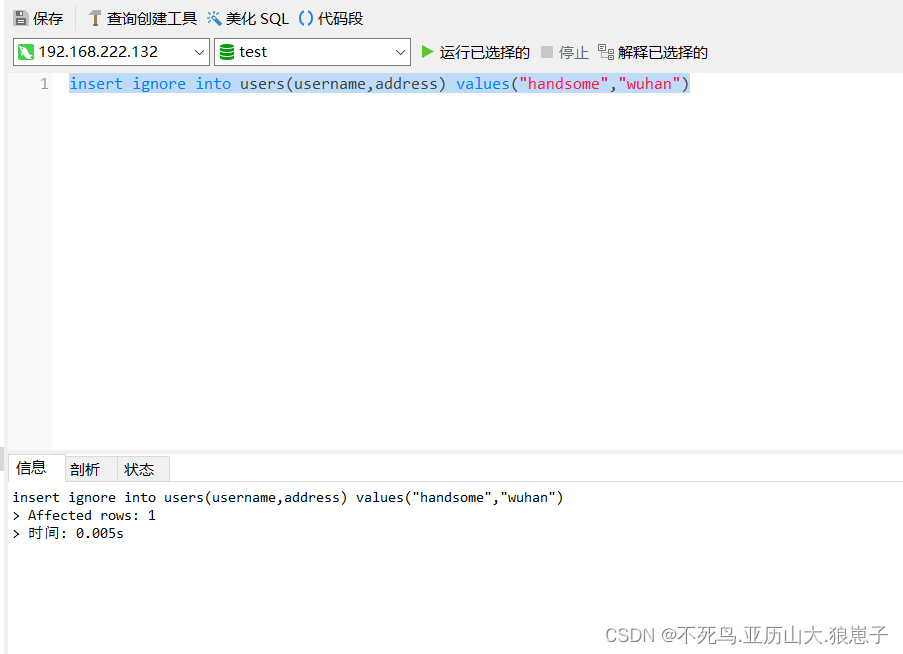
查询数据表可以看到该数据:
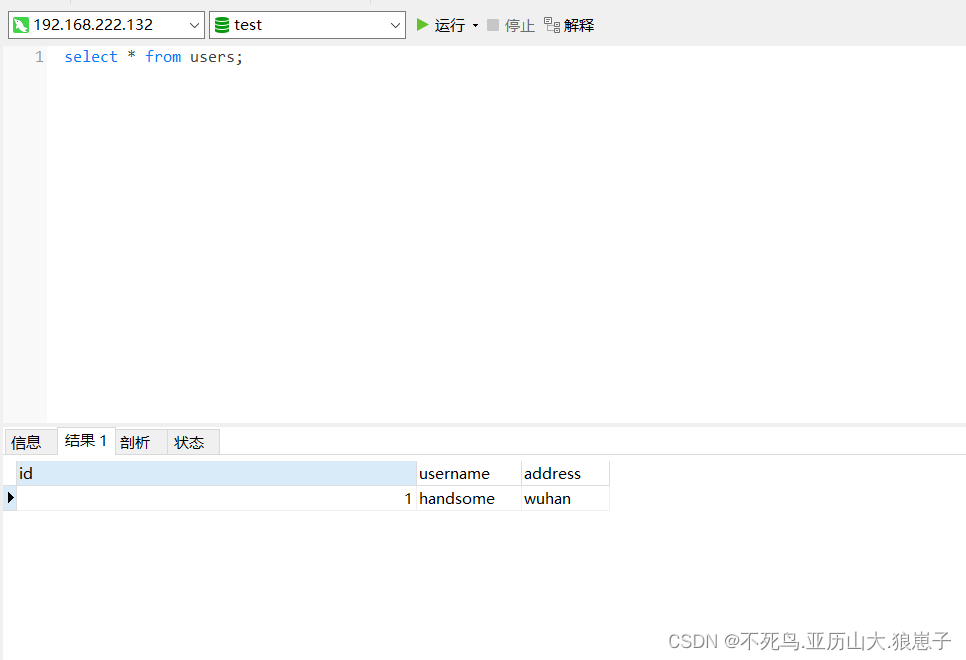
第二次插入,由于该数据表中已经存在该数据,可以看到,没有插入。
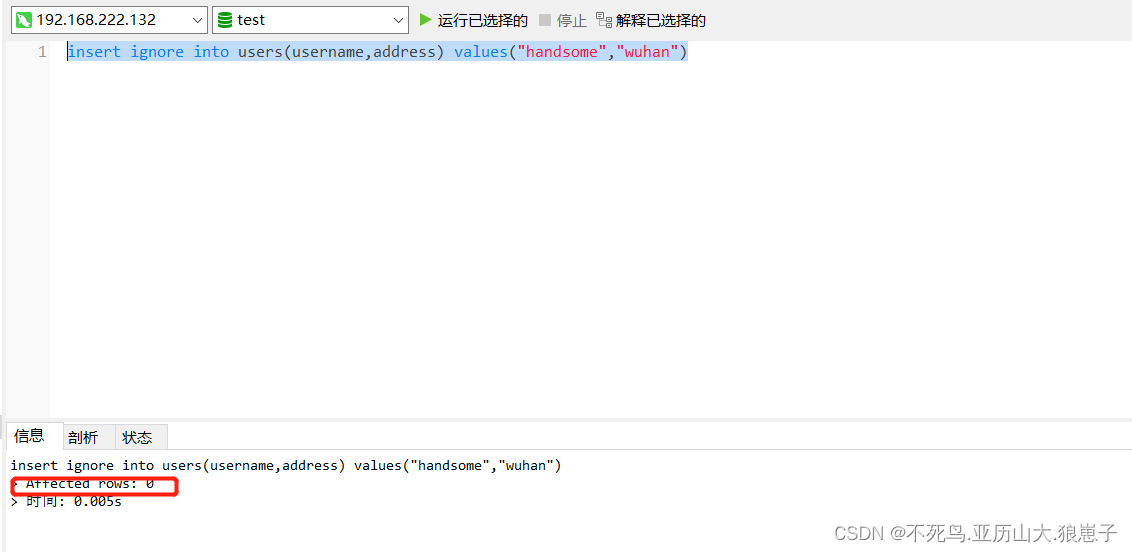
1.2 on duplicate key update
即插入数据时,如果数据存在,则执行更新操作,该方法有前提条件:插入的数据字段设置了主键或唯一索引。
测试SQL语句如下:
insert into users(username,address) values("god","suzhou") on DUPLICATE key update address='suzhou';当插入本条记录时,MySQL数据库会首先检索已有数据(idx_username索引),如果存在,则执行update更新操作,如果不存在,则直接插入。
第一次执行如下:
由于数据表中没有数据,插入成功。
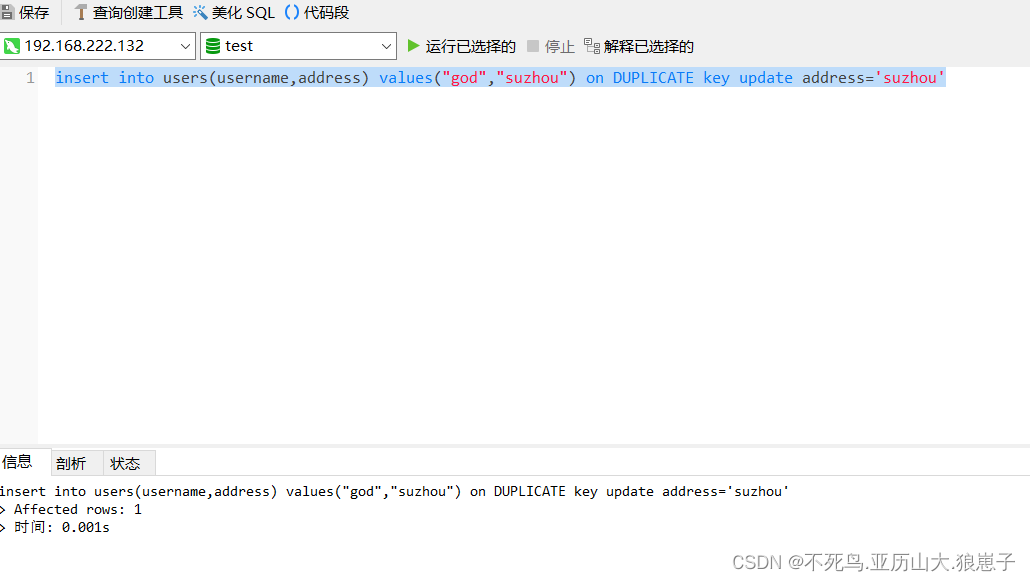
查询数据表可以看到该数据:
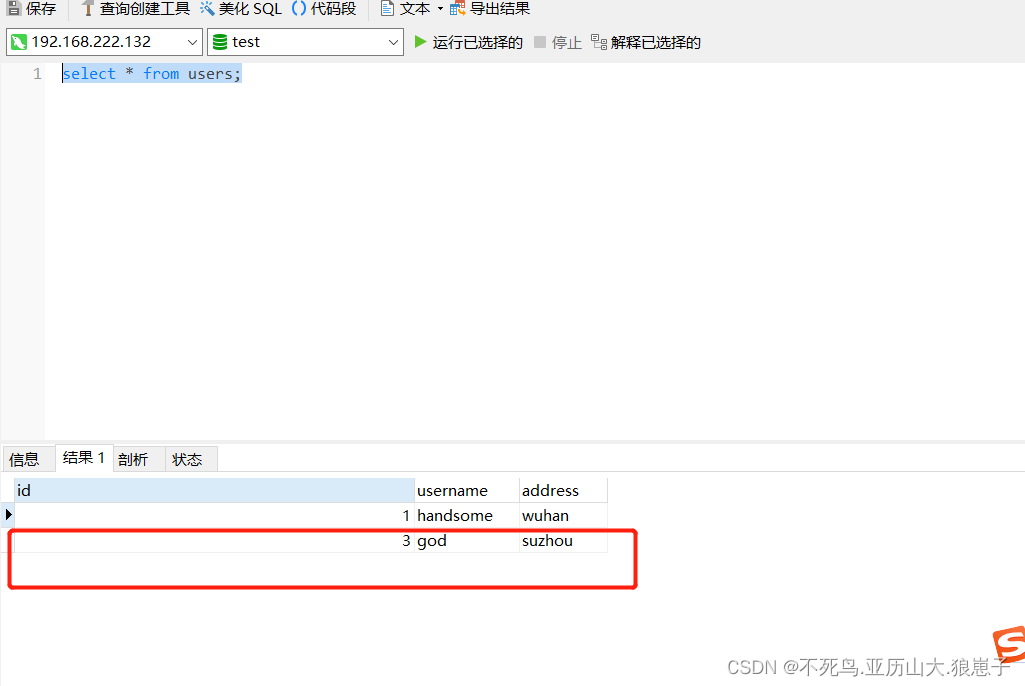
第二次插入,由于该数据表中已经存在该数据,可以看到,没有插入。
1.3 replace into
即插入数据时,如果数据存在,则删除再插入,该方法有前提条件:插入的数据字段需要设置主键或唯一索引。
测试SQL语句如下:
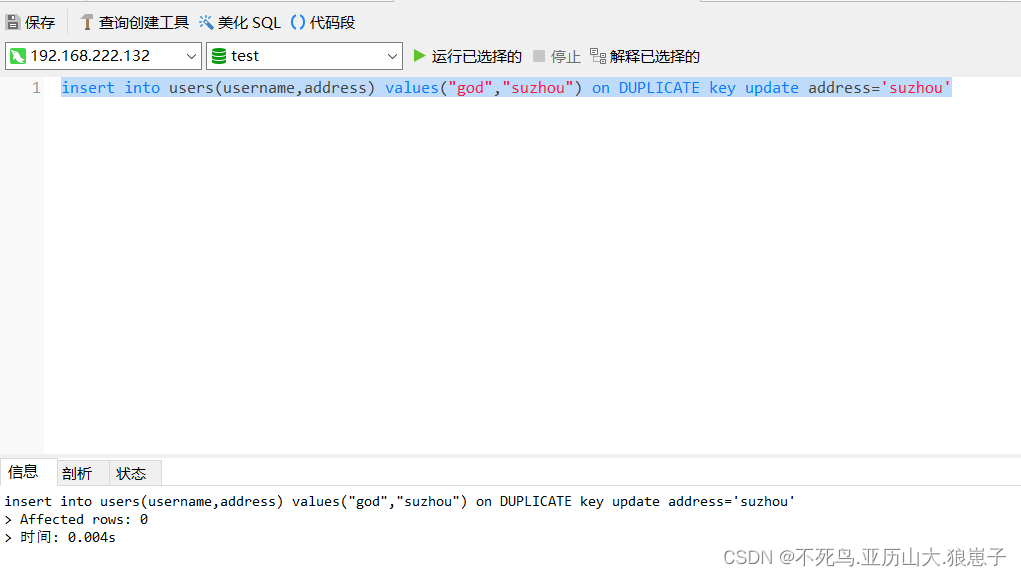
replace into users(username,address) values("xiong","wuxi")当插入本条记录时,MySQL数据库会首先检索已有数据(idx_username索引),如果存在,则先删除旧数据,然后再插入,如果不存在,则直接插入。
第一次执行如下:
由于数据表中没有数据,插入成功。
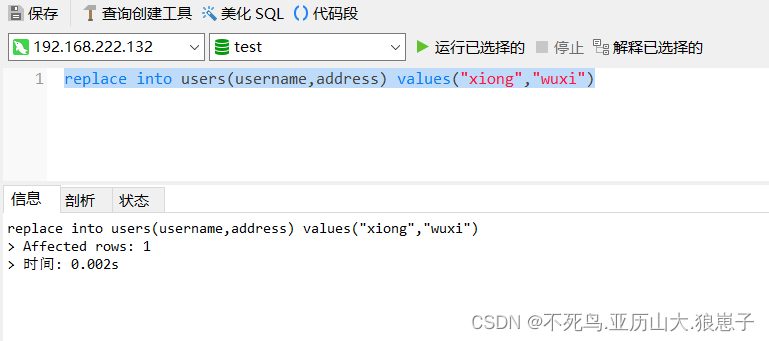
查询数据表可以看到该数据:
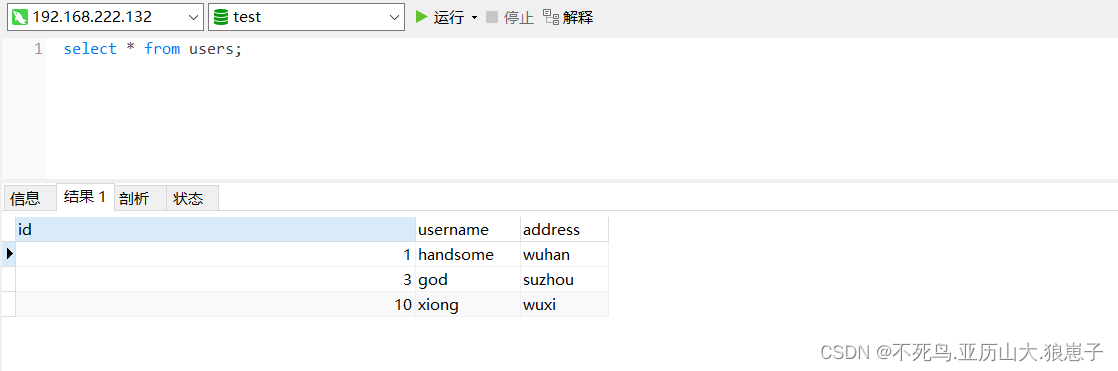
第二次插入,由于该数据表中已经存在该数据,先删除,再插入,可以看到执行结果两条。
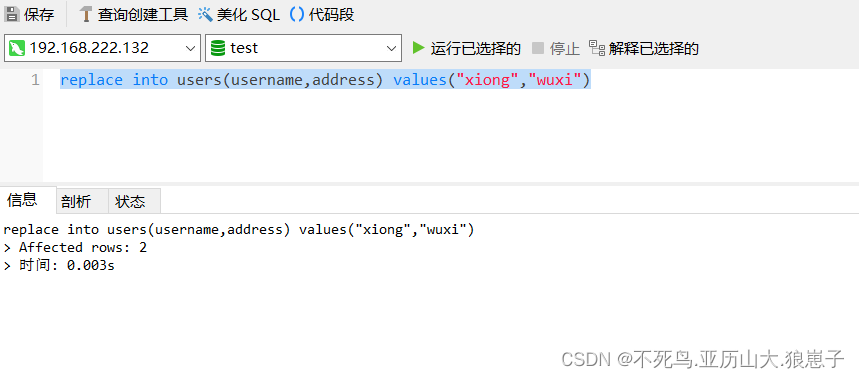
查看发现主键已经变化。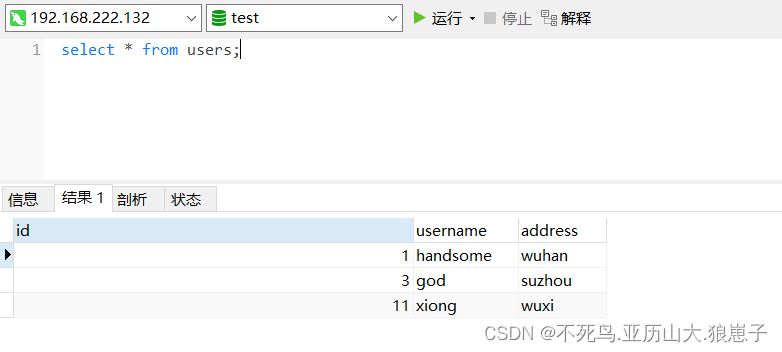
1.4 insert if not exists
即insert into … select … where not exist ... ,这种方式适合于插入的数据字段没有设置主键或唯一索引,当插入一条数据时,首先判断MySQL数据库中是否存在这条数据,如果不存在,则正常插入,如果存在,则忽略:
insert into users(username,address) select distinct "peng","chongqing" from users where not exists (select username from users where username="peng")第一次执行如下:
由于数据表中没有数据,插入成功。

查询数据库以插入成功
第二次插入,由于该数据表中已经存在该数据,可以看到,没有插入。
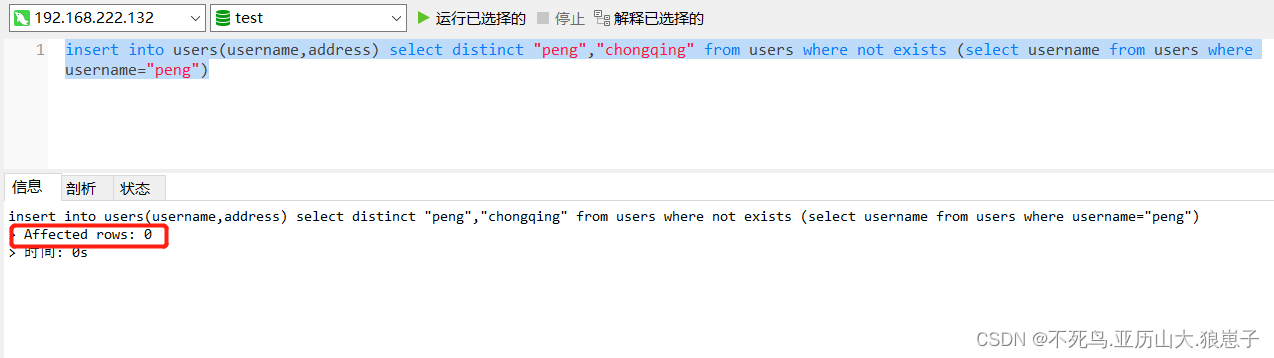
2 总结
以上4种MySQL处理重复数据的方式,前3种方式适合字段设置了主键或唯一索引,最后一种方式则没有此限制。
来源地址:https://blog.csdn.net/u013938578/article/details/128966261







