
这篇文章将为大家详细讲解有关Linux系统如何部署Hadoop集群,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
Hadoop简介:
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台
Hadoop允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
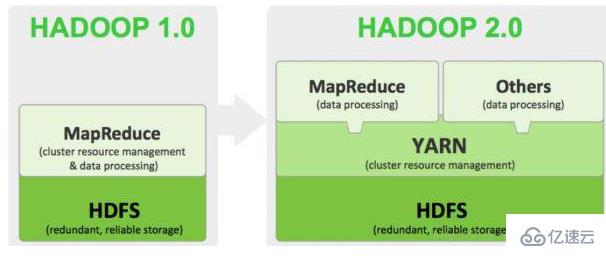
狭义上说,Hadoop指Apache这款开源框架,它的核心组件有:
HDFS(分布式文件系统):解决海量数据存储
YARN(作业调度和集群资源管理的框架):解决资源任务调度
MAPREDUCE(分布式运算编程框架):解决海量数据计算
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
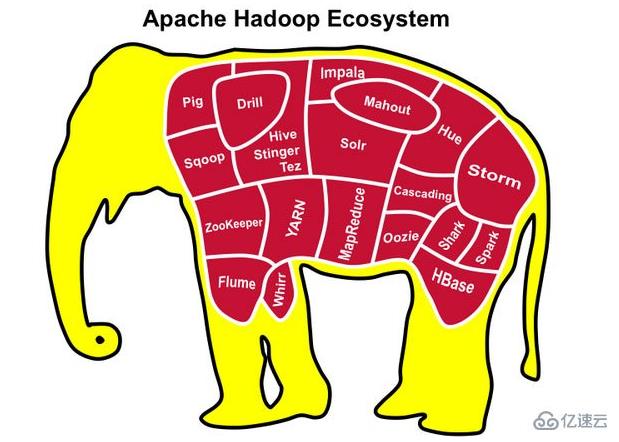
当下的Hadoop已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中不乏一些非Apache主管的项目,这些项目对HADOOP是很好的补充或者更高层的抽象。
Linux系统安装Hadoop步骤
安装ssh服务
进入shell命令,输入如下命令,查看是否已经安装好ssh服务,若没有,则使用如下命令进行安装:
sudo apt-get install ssh openssh-server
安装过程还是比较轻松加愉快的。
使用ssh进行无密码验证登录
1.创建ssh-key,这里我们采用rsa方式,使用如下命令:
ssh-keygen -t rsa -P “”
2.出现一个图形,出现的图形就是密码,不用管它
cat ~/.ssh/id_rsa.pub >> authorized_keys(好像是可以省略的)
3.然后即可无密码验证登录了,如下:
ssh localhost
成功截图如下:
下载Hadoop安装包
下载Hadoop安装也有两种方式
1.直接上官网进行下载,http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
2.使用shell进行下载,命令如下:
wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
貌似第二种的方法要快点,经过漫长的等待,终于下载完成。
解压缩Hadoop安装包
使用如下命令解压缩Hadoop安装包
tar -zxvf hadoop-2.7.1.tar.gz
解压缩完成后出现hadoop2.7.1的文件夹
配置Hadoop中相应的文件
需要配置的文件如下,hadoop-env.sh,core-site.xml,mapred-site.xml.template,hdfs-site.xml,所有的文件均位于hadoop2.7.1/etc/hadoop下面,具体需要的配置如下:
1.core-site.xml 配置如下:
其中的hadoop.tmp.dir的路径可以根据自己的习惯进行设置。
2.mapred-site.xml.template配置如下:
3.hdfs-site.xml配置如下:
其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的目录下面。
补充,如果运行Hadoop的时候发现找不到jdk,可以直接将jdk的路径放置在hadoop.env.sh里面,具体如下:
export JAVA_HOME=”/home/leesf/program/java/jdk1.8.0_60″
运行Hadoop
在配置完成后,运行hadoop。
1.初始化HDFS系统
在hadop2.7.1目录下使用如下命令:
bin/hdfs namenode -format
截图如下:

过程需要进行ssh验证,之前已经登录了,所以初始化过程之间键入y即可。
成功的截图如下:
表示已经初始化完成。
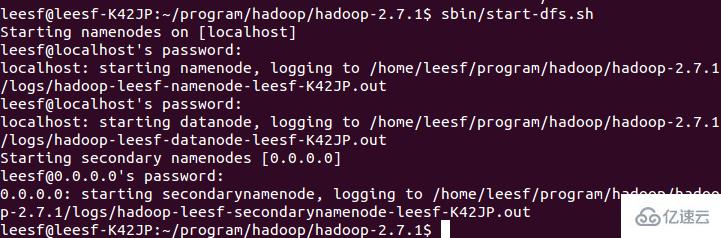
2.开启NameNode和DataNode守护进程
使用如下命令开启:
sbin/start-dfs.sh,成功的截图如下:
3.查看进程信息
使用如下命令查看进程信息
jps,截图如下:
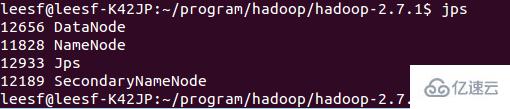
表示数据DataNode和NameNode都已经开启
4.查看Web UI
在浏览器中输入http://localhost:50070,即可查看相关信息,截图如下:
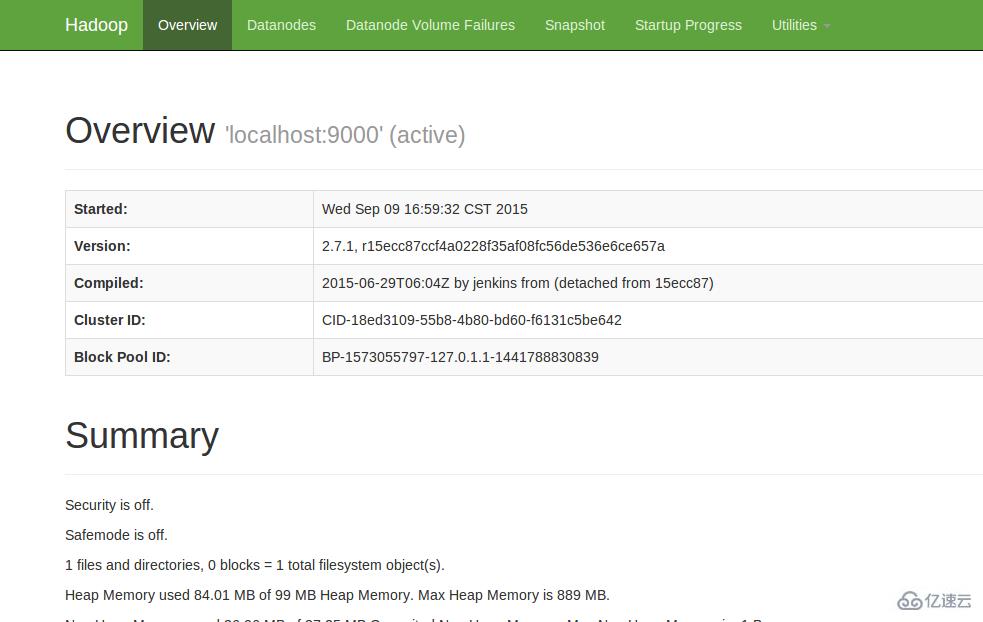
至此,hadoop的环境就已经搭建好了。下面开始使用hadoop来运行一个WordCount例子。
运行WordCount Demo
1.在本地新建一个文件,笔者在home/leesf目录下新建了一个words文档,里面的内容可以随便填写。
2.在HDFS中新建一个文件夹,用于上传本地的words文档,在hadoop2.7.1目录下输入如下命令:
bin/hdfs dfs -mkdir /test,表示在hdfs的根目录下建立了一个test目录
使用如下命令可以查看HDFS根目录下的目录结构
bin/hdfs dfs -ls /
具体截图如下:

表示在HDFS的根目录下已经建立了一个test目录
3.将本地words文档上传到test目录中
使用如下命令进行上传操作:
bin/hdfs dfs -put /home/leesf/words /test/
使用如下命令进行查看
bin/hdfs dfs -ls /test/
结果截图如下:

表示已经将本地的words文档上传到了test目录下了。
4.运行wordcount
使用如下命令运行wordcount:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /test/words /test/out
截图如下:

运行完成后,在/test目录下生成名为out的文件,使用如下命令查看/test目录下的文件
bin/hdfs dfs -ls /test
截图如下:

表示在test目录下已经有了一个名为Out的文件目录
输入如下命令查看out目录下的文件:
bin/hdfs dfs -ls /test/out,结果截图如下:

表示已经成功运行了,结果保存在part-r-00000中。
5.查看运行结果
使用如下命令查看运行结果:
bin/hadoop fs -cat /test/out/part-r-00000
结果截图如下:
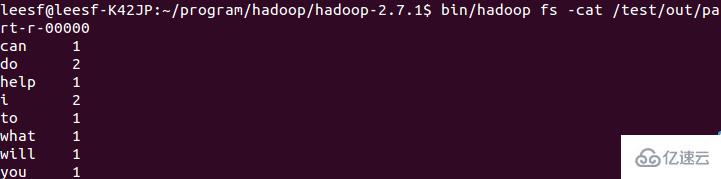
关于“Linux系统如何部署Hadoop集群”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。











