
本篇内容介绍了“HanLP分词器的用法”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
前言:分析关键词
如何在一段文本之中提取出相应的关键词呢?
之前我有想过用机器学习的方法来进行词法分析,但是在项目中测试时正确率不够。于是这时候便有了 HanLP-汉语言处理包 来进行提取关键词的想法。
下载:.jar .properties data等文件
这里提供官网下载地址 HanLP下载,1.3.3数据包下载
在intellij中配置环境,并运行第一个demo
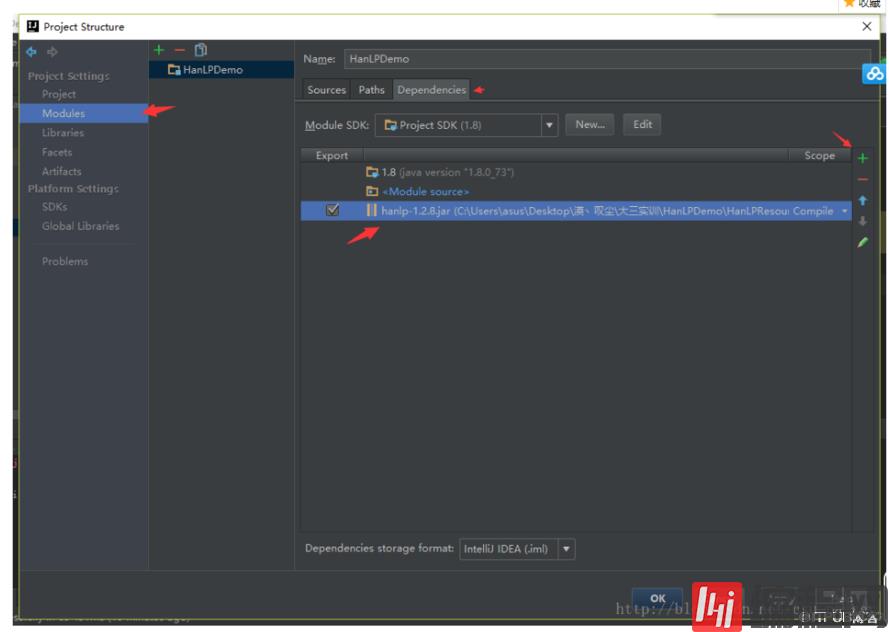
在项目中配置jar包,添加依赖。
file->Project Structure->Modules->Dependencies->+Jars
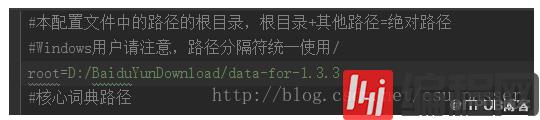
将properties文件转移到src根目录下,修改root为自己的数据集路径
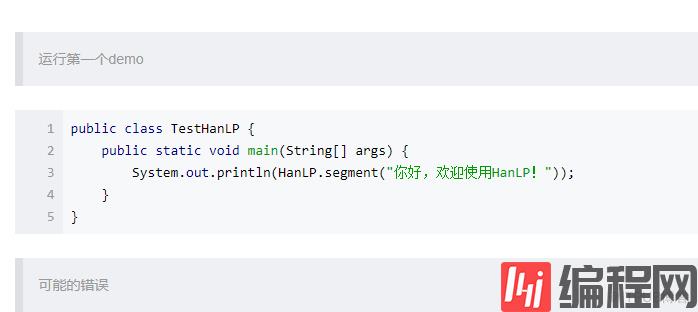
字符类型对应表加载失败:D:/BaiduYunDownload/data-for-1.3.3/data/dictionary/other/CharType.dat.yes
解决办法:查看错误提示页面下是否有该文件,如果没有则去网上下载一个。像我这里,由于只是使用其一部分功能,为了方便就不再下载了,这里我直接修改了一个文件的文件名—–成功运行!。

成功运行
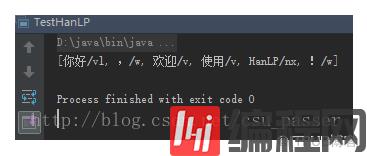
---------------------
“HanLP分词器的用法”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!








