
文章目录
灰色预测模型(Gray Forecast Model)是数学建模中的一个常用模型,旨在通过少量的、不完全的信息,建立数学模型并做出预测的一种预测方法,是处理小样本预测问题的有效工具,而对于小样本预测问题回归分析和神经网络模型的处理效果都不如灰色预测。
黑色系统被称为信息完全未确定的系统,白色系统被称信息完全确定的系统,灰色系统就是这介于这之间,一部分信息是已知的,另一部分信息是未知的,系统内各因素间有不确定的关系。
GM(1,1)是一阶微分方程模型,核心是通过对已知序列数据进行累加构造来制造规律,并利用常微分方程和最小二乘法来求解拟合的新序列。
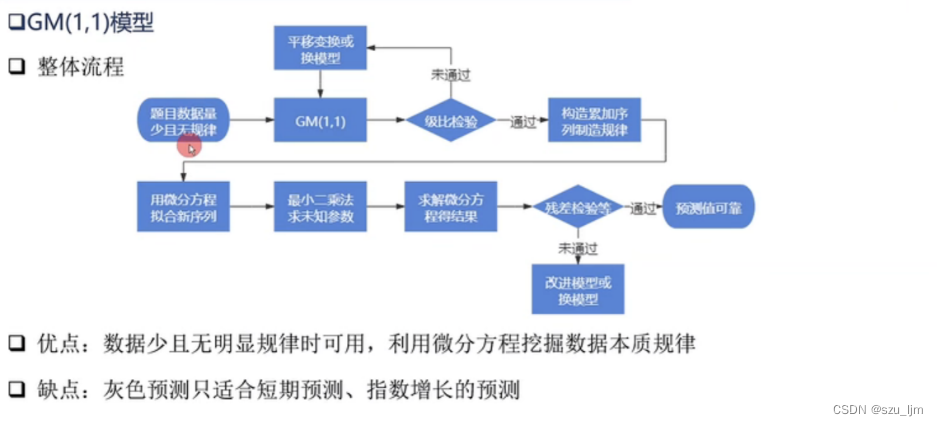
1. 级比检验
当我们得到一组数据时,为了保证灰色预测GM(1,1)模型的可行性,需要对原始序列数据进行级比检验。
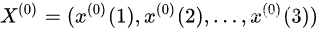
计算序列数据的级比 λ(k)
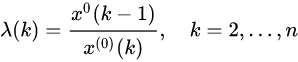
若计算出来的所有级比 λ ( k ) \lambda(k) λ(k)都落在区间 ( e − 2 / n + 1 , e 2 / n + 2 ) (e^{-2/n+1} , e^{2/n+2} ) (e−2/n+1,e2/n+2)内,则可进行灰色预测;若不在 ( e − 2 / n + 1 , e 2 / n + 2 ) (e^{-2/n+1} , e^{2/n+2} ) (e−2/n+1,e2/n+2)内,则要通过对序列数据进行平移变换使级比落在区间内;若平移变换也无法使级比落在区间内则改序列数据不适用GM(1,1)模型预测。
2. 构造累加序列
假设收到一组原始序列数据
X ( 0 ) = ( x ( 0 ) ( 1 ) , x ( 0 ) ( 2 ) , x ( 0 ) ( 3 ) , x ( 0 ) ( 4 ) , x ( 0 ) ( 5 ) ) X^{(0)}=(x^{(0)}(1),x^{(0)}(2),x^{(0)}(3),x^{(0)}(4),x^{(0)}(5)) X(0)=(x(0)(1),x(0)(2),x(0)(3),x(0)(4),x(0)(5))
为了制造规律,需要对该序列进行累加求和生成累加序列 X ( 1 ) = ( x ( 1 ) ( 1 ) , x ( 1 ) ( 2 ) , x ( 1 ) ( 3 ) , x ( 1 ) ( 4 ) , x ( 1 ) ( 5 ) ) X^{(1)}=(x^{(1)}(1),x^{(1)}(2),x^{(1)}(3),x^{(1)}(4),x^{(1)}(5)) X(1)=(x(1)(1),x(1)(2),x(1)(3),x(1)(4),x(1)(5))
x ( 1 ) ( 1 ) = x ( 0 ) ( 1 ) x^{(1)}(1)=x^{(0)}(1) x(1)(1)=x(0)(1)
x ( 1 ) ( 2 ) = x ( 0 ) ( 1 ) + x ( 0 ) ( 2 ) x^{(1)}(2)=x^{(0)}(1) + x^{(0)}(2) x(1)(2)=x(0)(1)+x(0)(2)
x ( 1 ) ( 3 ) = x ( 0 ) ( 1 ) + x ( 0 ) ( 2 ) + x ( 0 ) ( 3 ) x^{(1)}(3)=x^{(0)}(1) + x^{(0)}(2) + x^{(0)}(3) x(1)(3)=x(0)(1)+x(0)(2)+x(0)(3)
x ( 1 ) ( 4 ) = x ( 0 ) ( 1 ) + x ( 0 ) ( 2 ) + x ( 0 ) ( 3 ) + x ( 0 ) ( 4 ) x^{(1)}(4)=x^{(0)}(1) + x^{(0)}(2) + x^{(0)}(3) + x^{(0)}(4) x(1)(4)=x(0)(1)+x(0)(2)+x(0)(3)+x(0)(4)
x ( 1 ) ( 5 ) = x ( 0 ) ( 1 ) + x ( 0 ) ( 2 ) + x ( 0 ) ( 3 ) + x ( 0 ) ( 4 ) + x ( 0 ) ( 5 ) x^{(1)}(5)=x^{(0)}(1) + x^{(0)}(2) + x^{(0)}(3) + x^{(0)}(4) + x^{(0)}(5) x(1)(5)=x(0)(1)+x(0)(2)+x(0)(3)+x(0)(4)+x(0)(5)
3. 生成紧邻均值序列
为了减小单个样本数据的波动误差,需要对累加序列的相邻两项数据求均值生成紧邻均值序列 Z ( 1 ) = ( z ( 1 ) ( 2 ) , x ( 1 ) ( 3 ) , x ( 1 ) ( 4 ) , x ( 1 ) ( 5 ) ) Z^{(1)}=(z^{(1)}(2),x^{(1)}(3),x^{(1)}(4),x^{(1)}(5)) Z(1)=(z(1)(2),x(1)(3),x(1)(4),x(1)(5))
z ( 1 ) ( 2 ) = ( x ( 1 ) ( 1 ) + x ( 1 ) ( 2 ) ) / 2 z^{(1)}(2) = (x^{(1)}(1) + x^{(1)}(2))/2 z(1)(2)=(x(1)(1)+x(1)(2))/2
z ( 1 ) ( 3 ) = ( x ( 1 ) ( 2 ) + x ( 1 ) ( 3 ) ) / 2 z^{(1)}(3) = (x^{(1)}(2) + x^{(1)}(3))/2 z(1)(3)=(x(1)(2)+x(1)(3))/2
z ( 1 ) ( 4 ) = ( x ( 1 ) ( 3 ) + x ( 1 ) ( 4 ) ) / 2 z^{(1)}(4) = (x^{(1)}(3) + x^{(1)}(4))/2 z(1)(4)=(x(1)(3)+x(1)(4))/2
z ( 1 ) ( 5 ) = ( x ( 1 ) ( 4 ) + x ( 1 ) ( 5 ) ) / 2 z^{(1)}(5) = (x^{(1)}(4) + x^{(1)}(5))/2 z(1)(5)=(x(1)(4)+x(1)(5))/2
4. 建立灰微分方程
下面正式建立GM(1,1)模型的灰微分方程,其中, a a a 称为发展系数用于衡量样本数据的走向趋势, z ( 1 ) ( k ) z^{(1)}(k) z(1)(k)称为白化背景值, b b b 称为灰作用量。
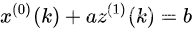
将上述线性方程组转换为矩阵,则GM(1,1)模型就可以表示为矩阵相乘 Y = B u Y = B u Y=Bu
u= [ a b ] ,Y= [ x ( 0 ) ( 2 ) x ( 0 ) ( 3 ) x ( 0 ) ( 4 ) x ( 0 ) ( 5 ) ] ,B= [ − z ( 1 ) ( 2 ) 1 − z ( 1 ) ( 3 ) 1 − z ( 1 ) ( 4 ) 1 − z ( 1 ) ( 5 ) 1 ] u= { \left[ \begin{array}{ccc} a\\ b \end{array} \right ]} , Y= { \left[ \begin{array}{ccc} x^{(0)}(2)\\ x^{(0)}(3)\\ x^{(0)}(4)\\ x^{(0)}(5) \end{array} \right ]}, B={ \left[ \begin{array}{ccc} -z^{(1)}(2) & 1\\ -z^{(1)}(3) & 1\\ -z^{(1)}(4) & 1\\ -z^{(1)}(5) & 1 \end{array} \right ]} u=[ab],Y=⎣⎢⎢⎡x(0)(2)x(0)(3)x(0)(4)x(0)(5)⎦⎥⎥⎤,B=⎣⎢⎢⎡−z(1)(2)−z(1)(3)−z(1)(4)−z(1)(5)1111⎦⎥⎥⎤
设 U^ \hat{U} U^ 为待估参数向量,即 U^ = ( a , b )T \hat{U}=(a,b)^T U^=(a,b)T,则灰微分方程的最小二乘估计参数列满足正规方程 U^ = ( BT B ) − 1 BT Yn \hat{U}=(B^TB)^{-1}B^TY_n U^=(BTB)−1BTYn,最小二乘法的目的就是求已知数据值和拟合函数值的平方差最小时参数估计取值,即求 ( Y − B U )T ( Y − B U ) (Y-BU)^{T}(Y-BU) (Y−BU)T(Y−BU)取最小值时的 U^ \hat{U} U^
5. 求解白化方程
建立灰色微分方程的白化方程
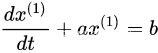
最后求白化方程的解
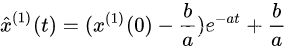
该解为估计值的累加和序列,求解估计值要x ^ ( 0 ) ( k + 1 ) = x ^ ( 1 ) ( k + 1 ) − x ^ ( 1 ) ( k ) \hat{x}^{(0)}(k+1)=\hat{x}^{(1)}(k+1) - \hat{x}^{(1)}(k) x^(0)(k+1)=x^(1)(k+1)−x^(1)(k)
6. 精度检验
为了验证样本数据使用GM(1,1)模型的预测精度,需要计算相对残差 ε ( k ) \varepsilon(k) ε(k)
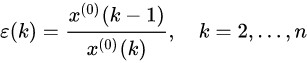
若 ε ( k ) \varepsilon(k) ε(k)<0.2 ,则认为达到一般要求;若 ε ( k ) \varepsilon(k) ε(k)<0.1 ,则认为达到较高要求。再计算级比偏差 ρ ( k ) \rho(k) ρ(k),需要用到之前的级比 λ ( k ) \lambda(k) λ(k) 和计算得到的 a a a

若 ρ ( k ) \rho(k) ρ(k) <0.2,则认为达到一般要求;若 ρ ( k ) \rho(k) ρ(k) <0.1, 则认为达到较高要求
利用Python实现GM(1,1)模型需要用到Python数据分析三剑客 - - Numpy,Pandas,Matplotlib库,下面我们以5年平均噪音序列数据为例进行建模和预测
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltdata = np.array([71.1,72.4,72.4,72.1,71.4]) #噪音数据lens = len(data)# 数据检验## 计算级比lambds = []for i in range(1, lens): lambds.append(data[i-1]/data[i])## 计算区间X_min = np.e**(-2/(lens+1))X_max = np.e**(2/(lens+1))## 检验test = Truefor lambd in lambds: if (lambd < X_min or lambd > X_max): test = Falseif test == False: print('该数据不可以用灰色GM(1,1)模型')else: print('该数据可以用灰色GM(1,1)模型')# 构建灰色模型GM(1,1)## 生成累加数列data_add = []for i in range(1, lens): data_add = data.cumsum()## 生成紧邻均值序列ds = []zs = []for i in range(1, lens): ds.append(data[i]) zs.append(-1/2*(data_add[i-1]+data_add[i]))## 生成矩阵和最小二乘法B = np.array(zs).reshape(lens-1,1)one = np.ones(lens-1)B = np.c_[B, one] # 加上一列1Y = np.array(ds).reshape(lens-1,1)a, b = np.dot(np.dot(np.linalg.inv(np.dot(B.T, B)), B.T), Y)print('a='+str(a))print('b='+str(b))# 预测def forecast(k): c = b/a return (data[0]-c)*(np.e**(-a*k))+cdata_1_for = [] # 累加预测值data_0_for = [] # 原始预测值data_1_for.append(forecast(0))data_0_for.append(data_1_for[0])for i in range(1, lens+5): # 多预测5次 data_1_for.append(forecast(i)) data_0_for.append(data_1_for[i]-data_1_for[i-1])print('预测值为:')for i in data_0_for: print(i)# 模型检验## 预测结果方差data_h = np.array(data_0_for[0:lens]).Tsum_h = data_h.sum()mean_h = sum_h/lensS1 = np.sum((data_h-mean_h)**2)/lens## 残差方差e = data - data_he_sum = e.sum()e_mean = e_sum/lensS2 = np.sum((e-e_mean)**2)/lens## 后验差比C = S2/S1## 结果if (C <= 0.35): print('1级,效果好')elif (C <= 0.5 and C >= 0.35): print('2级,效果合格')elif (C <= 0.65 and C >= 0.5): print('3级,效果勉强')else: print('4级,效果不合格')# 可视化plt.figure(figsize=(30, 30), dpi=100)x1 = np.linspace(1, 5, 5)x2 = np.linspace(1, 10, 10)plt.subplot(121)plt.title('x^0')plt.plot(x2, data_0_hat, 'r--', marker='*')plt.scatter(x1, data, marker='^')plt.subplot(122)plt.title('x^1')plt.plot(x2, data_1_hat, 'r--', marker='*')plt.scatter(x1, data_add, marker='^')plt.show()#/usr/bin/python3.8 /home/ljm/PycharmProject/pythoncode1/code9.py 该数据可以用灰色GM(1,1)模型a=[0.00456966]b=[73.06050512]预测值为:[71.1][72.56966625][72.23880382][71.90944986][71.58159751][71.25523991][70.93037026][70.60698176][70.28506767][69.96462127]1级,效果好#Process finished with exit code 0
我们可以发现GM(1,1)模型拟合的效果不错
以上就是今天笔记的内容,本文简单介绍了灰色预测GM(1,1)模型的使用,而灰色预测广泛用于数学建模领域,特别适用于样本数据较少的情况。GM(1,1)模型为我打开了数学建模的大门,愿小伙伴们一起探寻事物背后的底层数学逻辑吧!
来源地址:https://blog.csdn.net/m0_55202222/article/details/128762558







