
XPath 是一门在 XML 文档中查找信息的语言,最初是用来搜寻 XML 文档的,但是它同样适用于 HTML 文档的搜索。
所以在Python爬虫中,我们经常使用xpath解析这种高效便捷的方式来提取信息。
环境的安装
使用 xpath 需要安装 lxml 库
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
基础使用
实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。有两种方式:
1、将本地的html文档中的源码数据加载到etree对象中
etree.parse('filePath', etree.HTMLParser()) # filePath为文件的路径
示例:
from lxml import etree # 导包html = etree.parse('./test.html', etree.HTMLParser()) # ./test.html为本地的html文件的路径html.xpath('xpath表达式')将从互联网上获取的源码数据加载到etree对象中
etree.HtML('page_data') # page_data为从页面获取的源码数据
示例:
from lxml import etree # 导包html = etree.HtML('page_data') # page_data为从页面获取的源码数据html.xpath('xpath表达式')使用xpath解析数据,最重要的步骤就是xpath表达式的书写。下面介绍xpath的常用表达式。
xpath常用表达式
| 表达式 | 含义 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 表示的是从根节点开始定位。表示的是一个层级 |
| // | 从当前节点选取子孙节点(后代) |
| . | 选取当前节点 |
| @ | 选取属性 |
| text() | 获取文本 |
| * | 通配符,任何元素节点 |
| nodename[@attrib=‘value’] | 选取给定属性具有给定值的指定元素。如 div[@class=‘cell’] 表示 class 属性的值为 cell 的所有 div 元素 |
对以上的表达式的实例详解
先引入一段将要测试的 HTML 代码
DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <title>测试title>head><body> <div class="big"> <ul> <li><a href="https://www.baidu.com/">百度a>li> <li><a href="https://weibo.com/">微博a>li> <li><a href="https://www.tmall.com/">天猫a>li> <p>test1p> ul> <div> <a id="aa" href="https://www.iqiyi.com/">爱奇艺a> <a id="bb" href="https://v.qq.com/">腾讯视频a> <p>test2p> div> div>body>html>为了方便直观,我们对 HTML 文件进行本地读取测试
取节点
/ 和 // 的用法
我们先感受一下使用 xpath 来对网页进行解析的过程
代码:
from lxml import etreehtml = etree.parse('./test.html', etree.HTMLParser())result1 = html.xpath('/html/body/div/ul/li/a') # /表示层级关系,第一个/是根节点print(result1)运行结果:
[<Element a at 0x28696f20ac0>, <Element a at 0x28696f20b00>, <Element a at 0x28696f20b40>]可以看出运行结果中有3个节点,正好是从上往下数前面3个a节点。我们也可以看出上面使用了 / 来表示层级关系,所谓层级关系,其实就是一层包着一层,比如测试HTML代码中的 HTML 节点包着 body 节点,我们要取到 body 节点,就可以用 /html/body 来表示。以此类推,就可以取到我们想要的节点了。
我们既然能取出前3个a节点,那该如何取出所有的a节点呢?
这时我们就要用到 // 了
代码:
result2 = html.xpath('/html/body/div//a')print(result2)运行结果:
[<Element a at 0x222bf9afc80>, <Element a at 0x222bf9afcc0>, <Element a at 0x222bf9afd00>, <Element a at 0x222bf9afd40>, <Element a at 0x222bf9afd80>]不难看出 class=“big” 的div节点包着所有的 a节点,即所有的 a节点都是 class=“big” 的div节点的子孙节点(或简单理解为后代),我们用 /html/body/div//a 即可取出所有的 a节点
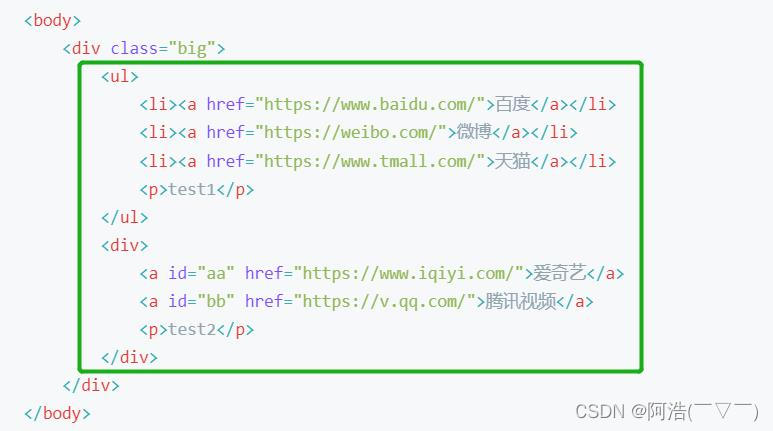
通配符 * 的用法
比如我们想取到下图的两个p节点,就可以用通配符 * 来提取

代码:
'''第一个p节点的表达式为: '/html/body/div/ul/p'第二个p节点的表达式为: '/html/body/div/div/p'可以看到这两个表达式唯一不同的地方的是 p节点前面的节点(父节点)一个是ul,一个是div这时我们只需用通配符 * 来代替p节点前面的父节点,因为通配符 * 可以表示任意节点'''# html.xpath('/html/body/div/ul/p')# html.xpath('/html/body/div/div/p')result = html.xpath('/html/body/div/*/p')print(result)运行结果:
[<Element p at 0x1e2c335f880>, <Element p at 0x1e2c335f8c0>]当然如果要取这两个p节点也可以用 // 来取,这里只是演示通配符 * 的用法
索引定位
比如我们想取到第一个a节点,就可以使用索引定位了
代码:
result3 = html.xpath('/html/body/div/ul/li[1]/a') #li[1]表示第一个li节点,注意索引是从[1]开始print(result3)运行结果:
[<Element a at 0x28705120ac0>]这里一定要注意索引是从 [1]开始!!!
属性定位
比如我想取 id=“aa” 的a节点,就可以使用属性定位 nodename[@attrib='value']
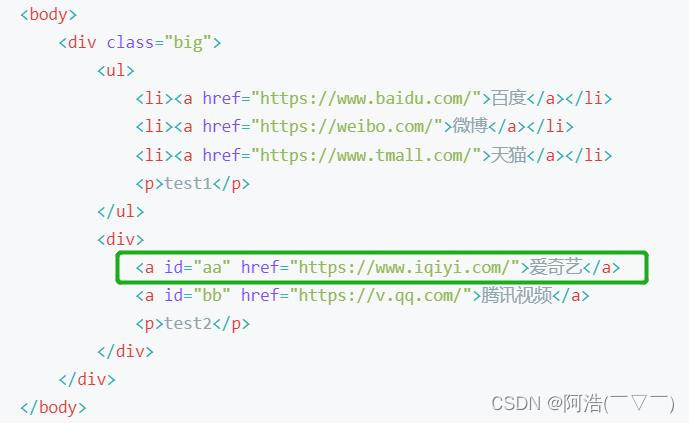
代码:
result4 = html.xpath('//a[@id="aa"]')print(result4)运行结果:
[<Element a at 0x2718236fc00>]取文本
在xpath中,使用 text() 即可取出网页中的文本信息
代码:
result5 = html.xpath('/html/body/div/ul/li[1]/a/text()') # text()获取文本print(result5)运行结果:
['百度']可以看到这个结果是一个列表,如果我们想取到里面的字符串,可以这样
result6 = html.xpath('/html/body/div/ul/li[1]/a/text()')[0] # 从列表中取第一个元素print(result6)运行结果:
百度取属性
如果我们想取到下图这个属性,我可以使用 @属性 这个表达式
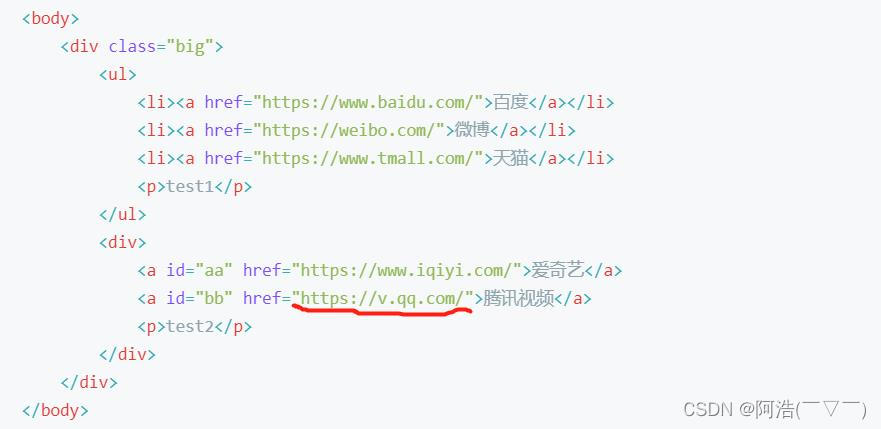
代码:
result7 = html.xpath('//a[@id="bb"]/@href')print(result7)运行结果:
['https://v.qq.com/']写xpath表达式的小技巧
我们在写爬虫时,往往会遇到比较复杂的页面代码,我们写xpath表达式也比较费劲。这里告诉大家一个偷懒的方法,直接借助浏览器copy
学会偷懒
具体操作:在浏览器中 F12 打开开发者工具 ——> 用左上角的箭头选取需要的内容 ——> 在对应的代码上鼠标右击 ——> Copy ——> Copy XPath
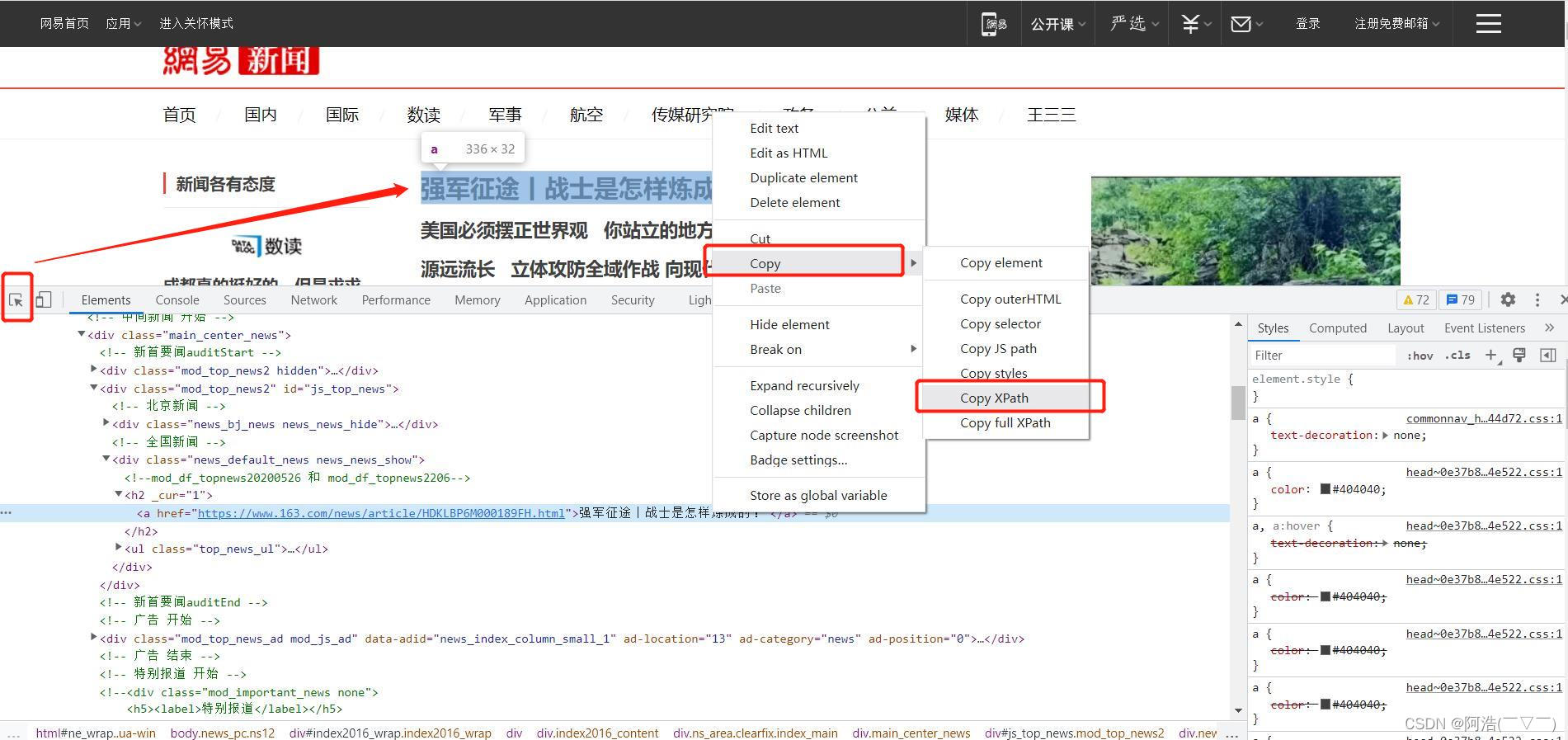
Copy的结果://*[@id="js_top_news"]/div[2]/h2/a这样的话,我们就轻松拿到了需要的xpath表达式。
当然我们不能只会使用这种copy的方法,还要真正理解xpath表达式的语法规则。因为在Python爬虫中xpath解析是有局限的,有些情况我们不能使用xpath表达式。
xpath解析的局限性
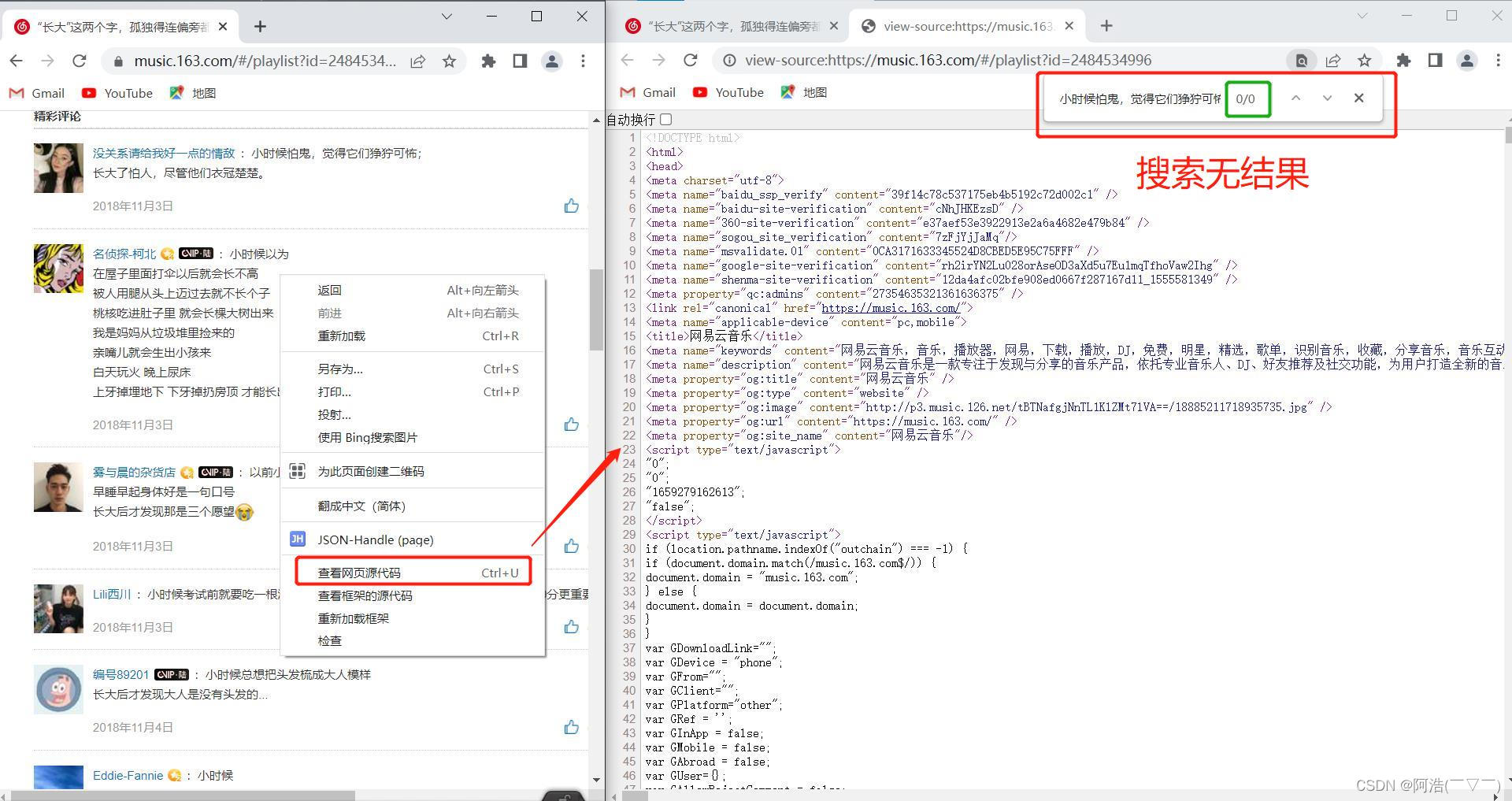
如果网页的数据是通过Ajax动态加载的,我们就不能使用xpath表达式来提取信息
一个简单的判断方法:在网页中鼠标右击 ——> 查看网页源代码 ——> ctrl+F 搜索想要的信息 ——> 搜索无结果 ——> 不能使用xpath解析
写xpath表达式的避坑指南
有时,我们直接复制 xpath表达式或者自己写xpath表达式会遇到提取信息后返回一个 空列表 这种情况,反复对照代码发现自己好像又没写错,这是怎么回事呢?
其实,很大可能是你没有以 网页源代码 为准来写xpath表达式,而是根据开发者工具展示的代码来写xpath表达式。原因就是开发者工具是实时的网页代码(比如通过js加载一些数据后的),而我们提取到的页面源码数据不一定是实时的网页代码。
比如:
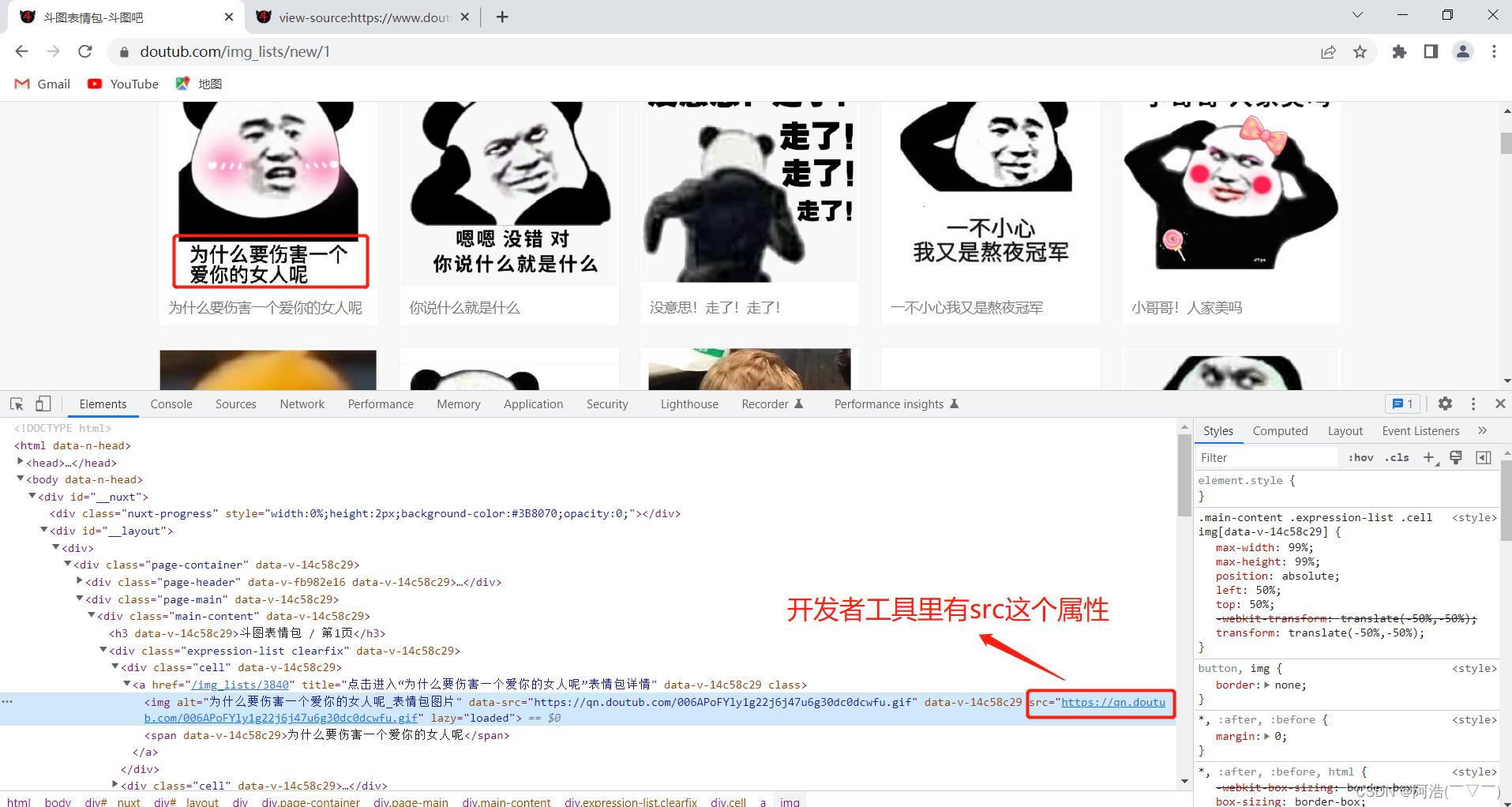
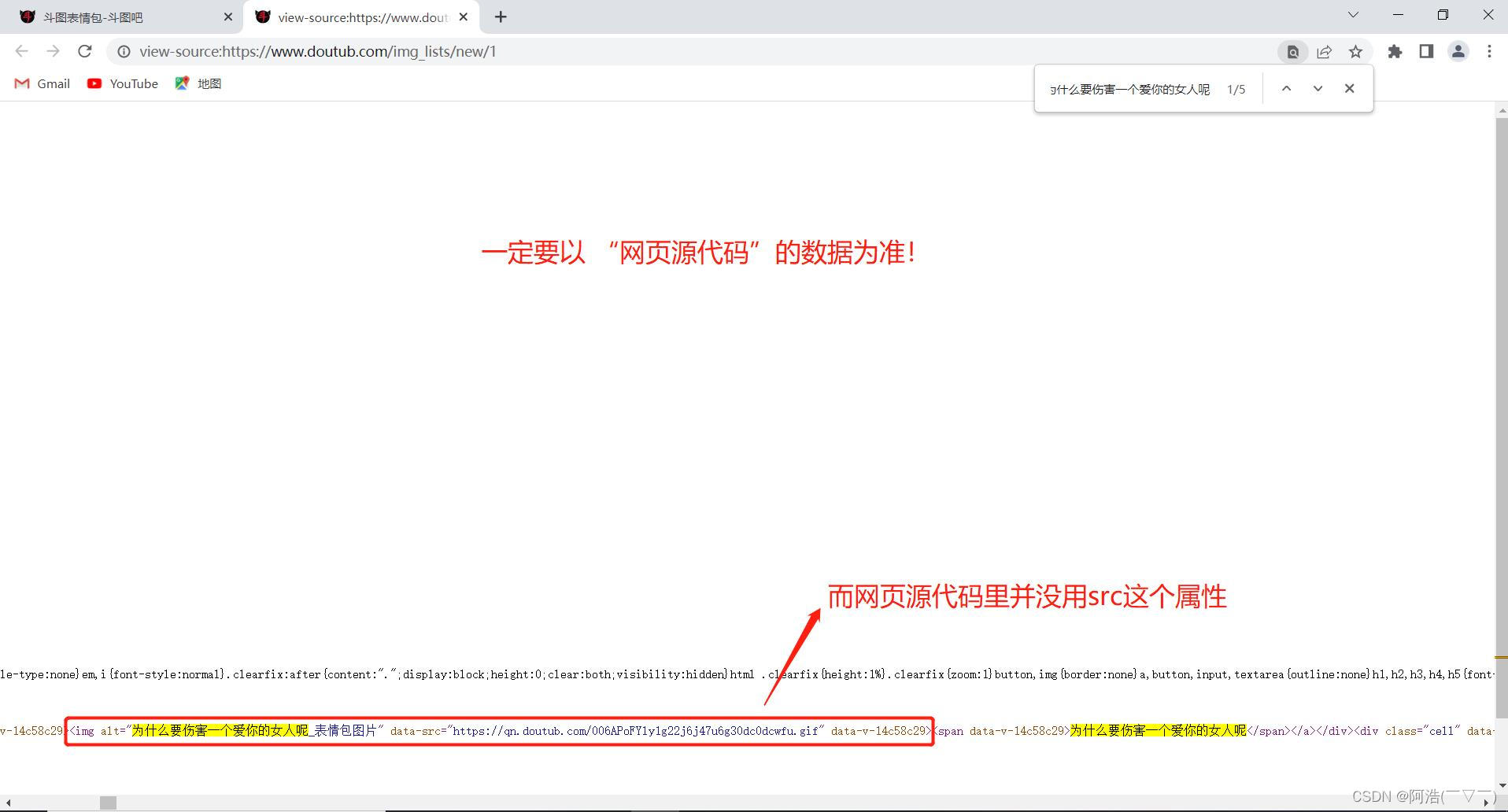
一般情况下,我们可以直接根据开发者工具展示的代码来写xpath表达式,但是一定要结合网页源代码,以网页源代码为准!
重要的事情说三遍!以网页源代码为准!以网页源代码为准!以网页源代码为准!
爬虫实战
下面进入爬虫实战。我们的目标是爬取某斗图网的表情包图片和描述文字,并把描述文字作为表情包图片的文件名
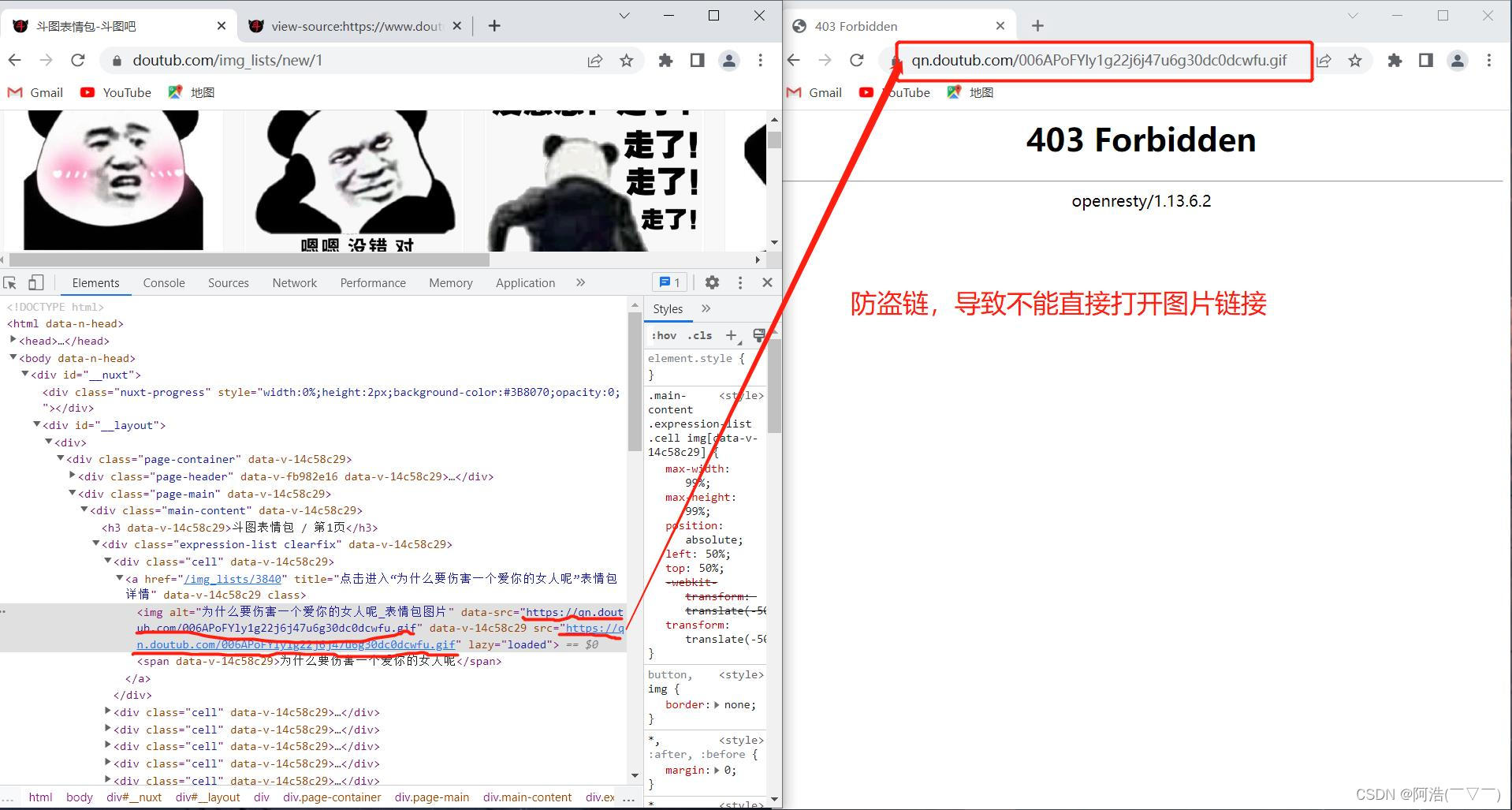
# 导入必要的库import requestsfrom lxml import etreeimport timeimport reimport osheaders = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36", "Referer": "https://www.doutub.com/" # 防盗链:溯源,当前本次请求的上一级是谁。请看下面图一、图二}num = int(input("你想爬取前几页:"))if os.path.exists("images") == False: os.mkdir("images") #如果不存在images文件夹,则创建images文件夹for n in range(num): # for循环提取多页内容 url = f'https://www.doutub.com/img_lists/new/{n+1}' # url 是网址,这里使用字符串拼接网址 # 如 https://www.doutub.com/img_lists/new/1(第一页网址) https://www.doutub.com/img_lists/new/2(第二页网址)等等 resp = requests.get(url, headers=headers) html = etree.HTML(resp.text) divs = html.xpath("//div[@class='cell']")[0:50] # 返回的 divs 是一个列表,切片去除无用信息,第51个div我们不需要,详细看图三 for div in divs: imgSrc = div.xpath("./a/img/@data-src")[0] word = div.xpath("./a/span/text()")[0].strip() name = re.sub(r'[\:*?"<>/|]', '', word) #使用正则表达式sub函数去除 \:*?"<>/|这些字符。原因看图四 img_type = imgSrc.split(".")[-1] #因为图片文件的格式有些是jpg,有些是gif,这里取出图片格式 # 下载图片 img_resp = requests.get(imgSrc, headers=headers) with open("images/" + name + "." + img_type, mode="wb") as f: f.write(img_resp.content) print(name + "." + img_type, "下载完成") time.sleep(0.3) # 防止频繁访问被封ip,这里休息0.3秒 print(f"\n第{n+1}页下载完成!\n")print("全部下载完成!!!")图一:
防盗链问题
图二:
解决防盗链
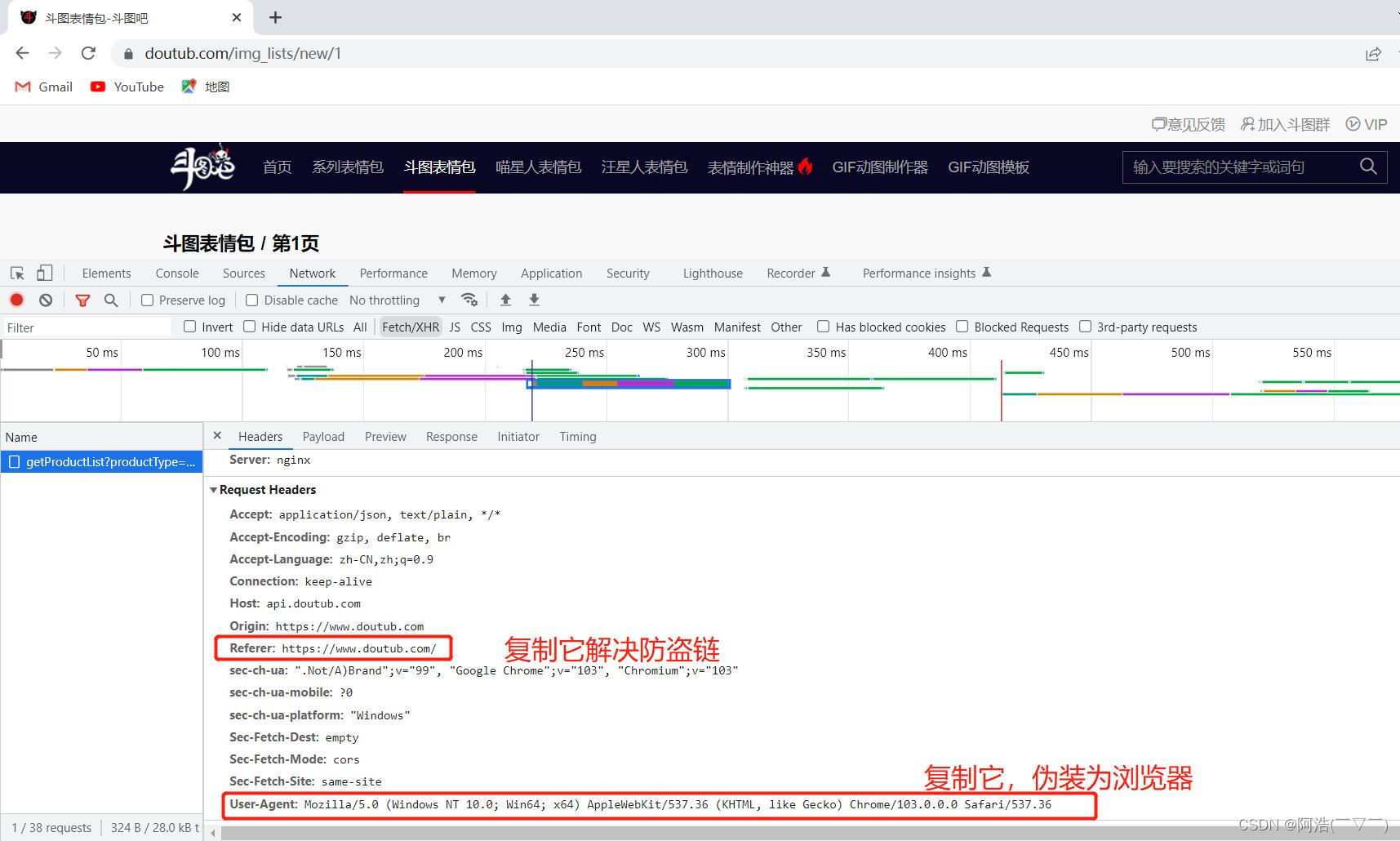
图三:
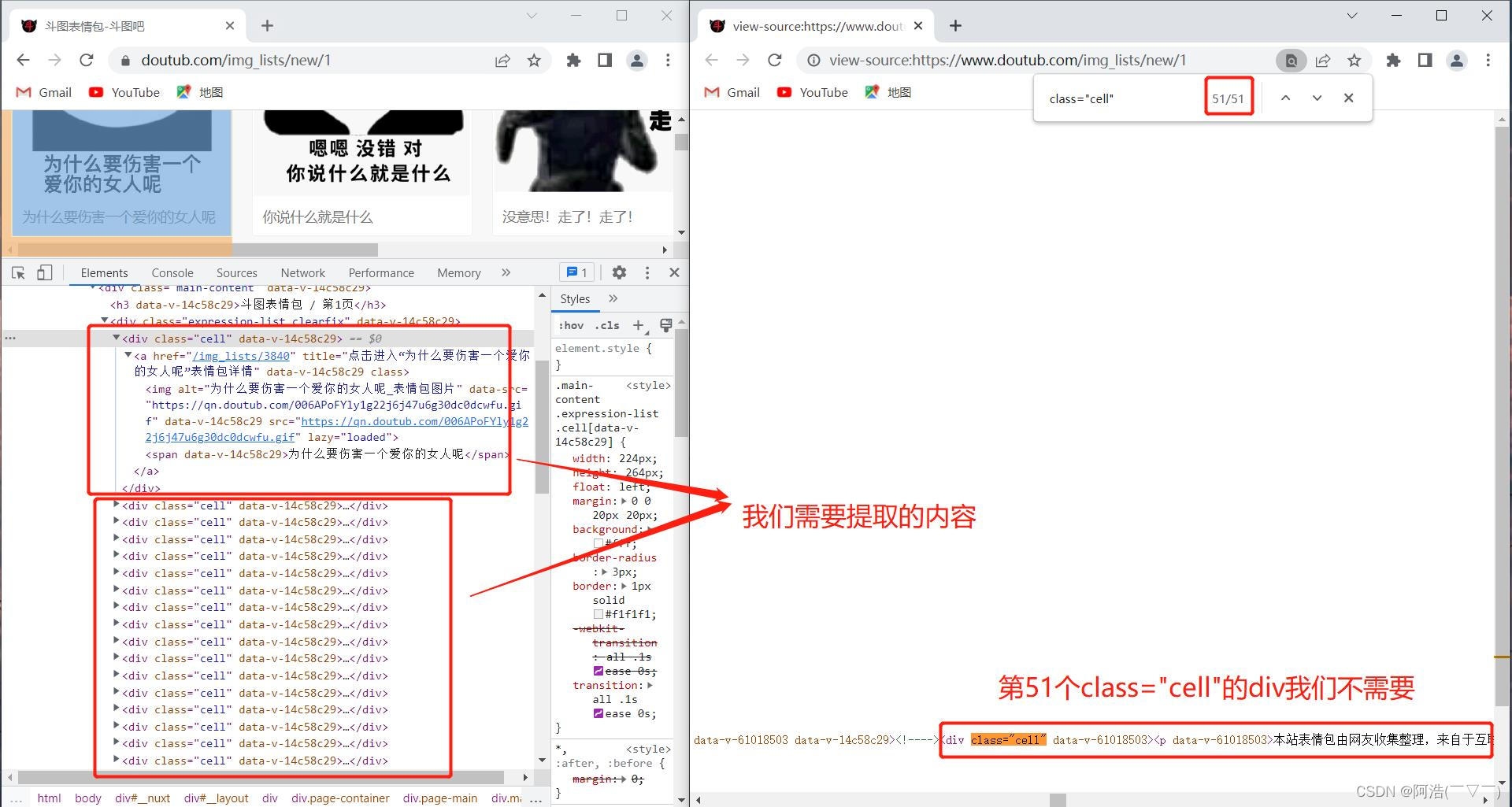
图四:
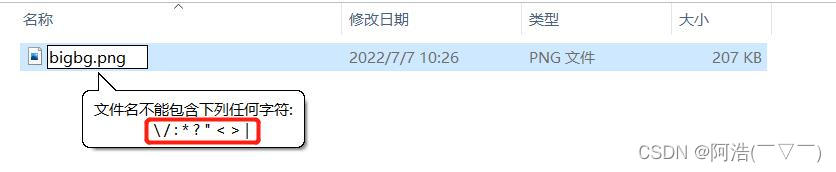
最终效果:
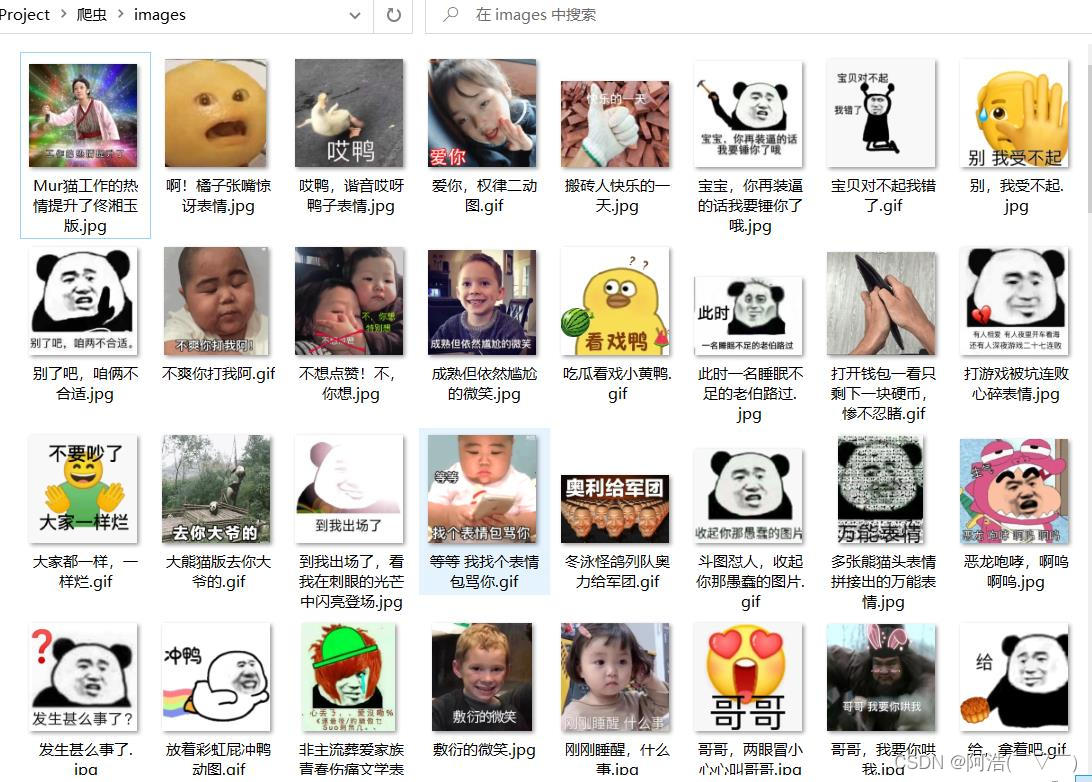
大功告成!
来源地址:https://blog.csdn.net/weixin_58667126/article/details/126105955







